最近在苦於思考kmeans算法的MPI並行化,花了兩天的時間先把串行版本實現了。
聚類問題就是給定一個元素集合V,其中每個元素具有d個可觀察屬性,使用某種算法將V劃分成k個子集,要求每個子集內部的元素之間相異度盡可能低,而不同子集的元素相異度盡可能高。
下面是google到該算法的一個流程圖,表意清楚:
1、隨機選取數據集中的k個數據點作為初始的聚類中心:
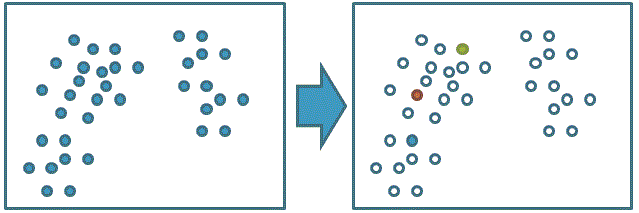
2、計算每個數據點對應的最短距離的聚類中心::
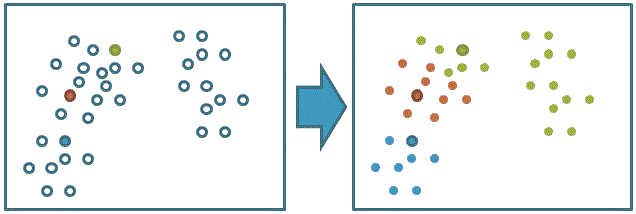
3、利用目前得到的聚類重新計算中心點:
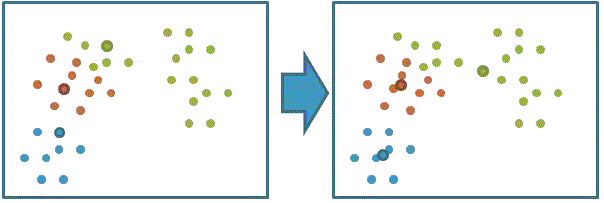
4、重復步驟2和3直到收斂(達到最大迭代次數或聚類中心移動距離極小):
code:
1 #include <stdio.h>
3 #include <stdlib.h>
4 #include <math.h>
5 #include <time.h>
6
7 int K,N,D; //聚類的數目,數據量,數據的維數
8 float **data; //存放數據
9 int *in_cluster; //標記每個點屬於哪個聚類
10 float **cluster_center; //存放每個聚類的中心點
11
12 float **array(int m,int n);
13 void freearray(float **p);
14 float **loadData(int *k,int *d,int *n);
15 float getDistance(float avector[],float bvector[],int n);
16 void cluster();
17 float getDifference();
18 void getCenter(int in_cluster[N]);
19
20 int main()
21 {
22 int i,j,count=0;
23 float temp1,temp2;
24 data=loadData(&K,&D,&N);
25 printf("Data sets:\n");
26 for(i=0;i<N;i++)
27 for(j=0;j<D;j++){
28 printf("%-8.2f",data[i][j]);
29 if((j+1)%D==0) putchar('\n');
30 }
31 printf("-----------------------------\n");
32
33 srand((unsigned int)(time(NULL))); //隨機初始化k個中心點
34 for(i=0;i<K;i++)
35 for(j=0;j<D;j++)
36 cluster_center[i][j]=data[(int)(N*rand()/(RAND_MAX+1.0))][j];
37
38 cluster(); //用隨機k個中心點進行聚類
39 temp1=getDifference(); //第一次中心點和所屬數據點的距離之和
40 count++;
41 printf("The difference between data and center is: %.2f\n\n", temp1);
42
43 getCenter(in_cluster);
44 cluster(); //用新的k個中心點進行第二次聚類
45 temp2=getDifference();
46 count++;
47 printf("The difference between data and center is: %.2f\n\n",temp2);
48
49 while(fabs(temp2-temp1)!=0){ //比較前後兩次迭代,若不相等繼續迭代
50 temp1=temp2;
51 getCenter(in_cluster);
52 cluster();
53 temp2=getDifference();
54 count++;
55 printf("The %dth difference between data and center is: %.2f\n\n",count,temp2);
56 }
57
58 printf("The total number of cluster is: %d\n\n",count); //統計迭代次數
59 system("pause");
60 return 0;
61 }
62
63
64 //動態創建二維數組
65 float **array(int m,int n)
66 {
67 float **p;
68 p=(float **)malloc(m*sizeof(float *));
69 p[0]=(float *)malloc(m*n*sizeof(float));
70 for(int i=1;i<m;i++) p[i]=p[i-1]+n;
71 return p;
72 }
73
74 //釋放二維數組所占用的內存
75 void freearray(float **p)
76 {
77 free(*p);
78 free(p);
79 }
80
81 //從data.txt導入數據,要求首行格式:K=聚類數目,D=數據維度,N=數據量
82 float **loadData(int *k,int *d,int *n)
83 {
84 float **arraydata;
85 FILE *fp;
86 if((fp=fopen("data.txt","r"))==NULL) fprintf(stderr,"cannot open data.txt!\n");
87 if(fscanf(fp,"K=%d,D=%d,N=%d\n",k,d,n)!=3) fprintf(stderr,"load error!\n");
88 arraydata=array(*n,D); //生成數據數組
89 cluster_center=array(*k,D); //聚類的中心點
90 in_cluster=(int *)malloc(*n * sizeof(int)); //每個數據點所屬聚類的標志數組
91 for(int i=0;i<*n;i++)
92 for(int j=0;j<D;j++)
93 fscanf(fp,"%f",&arraydata[i][j]); //讀取數據點
94 return arraydata;
95 }
96
97 //計算歐幾裡得距離
98 float getDistance(float avector[],float bvector[],int n)
99 {
100 int i;
101 float sum=0.0;
102 for(i=0;i<n;i++)
103 sum+=pow(avector[i]-bvector[i],2);
104 return sqrt(sum);
105 }
106
107 //把N個數據點聚類,標出每個點屬於哪個聚類
108 void cluster()
109 {
110 int i,j;
111 float min;
112 float **distance=array(N,K); //存放每個數據點到每個中心點的距離
113 //float distance[N][K]; //也可使用C99變長數組
114 for(i=0;i<N;++i){
115 min=9999.0;
116 for(j=0;j<K;++j){
117 distance[i][j] = getDistance(data[i],cluster_center[j],D);
118 //printf("%f\n", distance[i][j]);
119 if(distance[i][j]<min){
120 min=distance[i][j];
121 in_cluster[i]=j;
122 }
123 }
124 printf("data[%d] in cluster-%d\n",i,in_cluster[i]+1);
125 }
126 printf("-----------------------------\n");
127 free(distance);
128 }
129
130 //計算所有聚類的中心點與其數據點的距離之和
131 float getDifference()
132 {
133 int i,j;
134 float sum=0.0;
135 for(i=0;i<K;++i){
136 for(j=0;j<N;++j){
137 if(i==in_cluster[j])
138 sum+=getDistance(data[j],cluster_center[i],D);
139 }
140 }
141 return sum;
142 }
143
144 //計算每個聚類的中心點
145 void getCenter(int in_cluster[N])
146 {
147 float **sum=array(K,D); //存放每個聚類中心點
148 //float sum[K][D]; //也可使用C99變長數組
149 int i,j,q,count;
150 for(i=0;i<K;i++)
151 for(j=0;j<D;j++)
152 sum[i][j]=0.0;
153 for(i=0;i<K;i++){
154 count=0; //統計屬於某個聚類內的所有數據點
155 for(j=0;j<N;j++){
156 if(i==in_cluster[j]){
157 for(q=0;q<D;q++)
158 sum[i][q]+=data[j][q]; //計算所屬聚類的所有數據點的相應維數之和
159 count++;
160 }
161 }
162 for(q=0;q<D;q++)
163 cluster_center[i][q]=sum[i][q]/count;
164 }
165 printf("The new center of cluster is:\n");
166 for(i = 0; i < K; i++)
167 for(q=0;q<D;q++){
168 printf("%-8.2f",cluster_center[i][q]);
169 if((q+1)%D==0) putchar('\n');
170 }
171 free(sum);
172 }
該程序支持不同維度的數據集,一個示例的數據集: data.txt如下:
K=3,D=3,N=15
-25 22.2 35.34
31.2 -14.4 23
32.02 -23 24.44
-25.35 36.3 -33.34
-20.2 27.333 -28.22
-15.66 17.33 -23.33
26.3 -31.34 16.3
-22.544 16.2 -32.22
12.2 -15.22 22.11
-41.241 25.232 -35.338
-22.22 45.22 23.55
-34.22 50.14 30.98
15.23 -30.11 20.987
-32.5 15.3 -25.22
-38.97 20.11 33.22