引言
這裡需要分享的是一個 簡單字符串庫和 鏈表的基庫,代碼也許用到特定技巧.有時候回想一下,
如果我讀書的時候有人告訴我這些關於C開發的積澱, 那麼會走的多直啊.剛參加工作的時候做桌面開發,
服務是C++寫,界面是C#寫.那時候剛進去評級我是中級,因為他問我關於系統鎖和信號量都答出來.開發一段
時間,寫C#也寫的很溜.後面招我那個人讓我轉行就寫C++和php,那時候就開始學習C++有關知識.
後面去四川工作了,開發安卓,用eclipse + java語法 + android jdk,開發前端,用起來,我的感受,都相似,就是api名字
有點長. 都是那老套路,後來四川公司黃了. 輾轉又來了北京做C系列還有php開發. 說了這麼多, 我想說下面幾個問題.
1. 你寫的是 C# 和 java嗎,還只是.net/jdk的積木 , 寫了那麼多這樣的代碼,你感到疑惑嗎?
2.假如你也感到過疑惑, 推薦去看看 Linux程序開發 或 unix環境編程, 網絡編程
//2.1 不推薦認真學C++, 學了好多,看了好多書,還是不明覺歷,覺得是在雜耍! 如果喜歡C,把市面上好的C書都看一遍,敲一遍!
3. 因為隨著年紀增長,效率太重要了, 需要去找到學到那些一招鮮吃遍天的東西, 其它的讓年起人去拼搏吧.
有時候想想,做軟件開發,初中就夠了,高中綽綽有余,大學研究生都暴遣天物. 大家覺得呢.
又扯了一會兒蛋, 今天分享的還是很有用的,但是感覺沒接觸這樣黑科技的還是有點難. 或者說封裝一個框架還是有難度的,
或者,哪怕再小的一個庫封裝完畢都是不容易的.而我們分享的是封裝庫的庫. 個人比較水,打臉要輕打.
用到的資源
list 測試demo http://download.csdn.net/detail/wangzhione/9428243
入行第一篇博文 C的回歸(國內超一線) http://blog.codingnow.com/2007/09/c_vs_cplusplus.html
再扯一點, 2015 北京平均工資最高的三個職業 IT 特殊服務業 電子設備. 如果你窮你真的需要 認真學習編程,不要太沉迷於框架的學習中.
真的 人窮就應該多編程, 別人搶紅包,你 需要寫代碼, , ,
前言
終於到這裡了,扯的有點多. 首先來看一下今天主要寫的通用鏈表的接口,看設計
#ifndef _H_LIST
#define _H_LIST
#include <schead.h>
/*
* 這個萬能單鏈表庫 前提所有結點都是堆上分配的,設計的比較老了,能用
*注意
* 1.使用的時候,需要加上 _LIST_HEAD; 宏
* 2.創建的第一句話就是 list head = NULL; 開始從空鏈表開始list的生涯
*/
struct __lnode {
struct __lnode* next;
};
// 不多說了一定放在想使用鏈表結構的結構體頭部
#define _LIST_HEAD \
struct __lnode __ln;
// 簡單鏈表結構, 當你使用這個鏈表的時候 需要 list_t head = NULL; 開始使用之旅
typedef void* list_t;
/*
* 采用頭查法插入結點, 第一使用需要 list_t head = NULL;
*返回 _RT_OK 表示成功!
* ph : 指向頭結點的指針
* node : 待插入的結點對象
*/
extern int list_add(list_t* ph, void* node);
/*
* 鏈表中查找函數,查找失敗返回NULL,查找成功直接返回那個結點,推薦不要亂改,否則就崩了.
*如果需要改的話,推薦 用 list_findpop, 找到並彈出
* h : 鏈表頭結點
* cmp : 查找的比較函數
* left : cmp(left, right) 用的左結點
* : 返回查找的結點對象
*/
extern void* list_find(list_t h, icmp_f cmp, const void* left);
/*
* 查找到要的結點,並彈出,需要你自己回收
* ph : 指向頭結點的指針
* cmp : 比較函數,將left同 *ph中對象按個比較
* left : cmp(left, x) 比較返回 0 >0 <0
* : 找到了退出/返回結點, 否則返回NULL
*/
extern void* list_findpop(list_t *ph, icmp_f cmp, const void* left);
/*
* 這裡獲取當前鏈表長度, 推薦調用一次就記住len
* h : 當前鏈表的頭結點
* : 返回 鏈表長度 >=0
*/
extern int list_len(list_t h);
/*
* 查找索引位置為idx的結點,找不見返回NULL
* h : 當前結點
* idx : 查找的索引值[0,len)
* : 返回查到的結點,如果需要刪除的推薦調用 list_pop(&h, idx);
*/
extern void* list_get(list_t h, int idx);
/*
* 按照索引彈出並返回結點, 需要自己回收這個結點 推薦 free(list_pop...);
* ph : 指向鏈表結點的指針
* idx : 彈出的索引
* return : 無效的彈出,返回NULL
*/
void* list_pop(list_t* ph, int idx);
/*
* 返回結點node 的上一個結點,如果node = NULL, 返回最後一個結點
* h : 當前鏈表結點
* node : 待查找的結點信息
* return : 返回查找到的結點,不存在返回NULL
*/
void* list_front(list_t h, void* node);
/*
* 這個宏推薦不使用, 主要返回結點n的下一個結點
* 第一種使用方法 node->next = (void*)list_node(n), 另一種是 list_node(n) = node;
* n : 當前結點
*/
#define list_next(n) \
(((struct __lnode*)n)->next)
/*
* 和 list_add 功能相似,但是插入位置在尾巴那
* ph : 待插入結點的指針
* node : 待插入的當前結點
*/
int list_addlast(list_t* ph, void* node);
/*
* 在鏈表的第idx索引處插入結點,也必須需要 list_t head = NULL; 在idx過大的時候
*插入尾巴處,如果<0直接返回 _RT_EP. 成功了返回 _RT_OK
* ph : 指向頭結點的指針
* idx : 結點的索引處
* node : 待插入的結點
*/
int list_addidx(list_t* ph, int idx, void* node);
/*
* 這裡的銷毀函數,只有這些數據都是棧上的才推薦這麼做,會自動讓其指向NULL
* ph : 指向當前鏈表結點的指針
*/
void list_destroy(list_t* ph);
#endif // !_H_LIST
這裡接口使用的 extern聲明的希望外部直接使用, 沒有extern的外部可以使用,屬於擴展功能.
對於上面接口 簡單的測試 代碼如下
#include <list.h>
struct lint {
_LIST_HEAD;
int node;
};
//簡單創建函數
static struct lint* __lint_new(int node)
{
struct lint* ln = malloc(sizeof(struct lint));
if(ln){
ln->node = node;
}
return ln;
}
//簡單打印函數
static void __lint_puts(list_t head)
{
int len = list_len(head);
int i;
printf("當前鏈表中數據結果如下:");
for(i=0; i<len; ++i){
struct lint* tl = list_get(head, i);
printf("%d ", tl->node);
}
putchar('\n');
}
/*
* 這裡簡單測試一下 關於鏈表的常用接口
*/
int main(int argc, char* argv[])
{
list_t head = NULL;
int arrs[] = { 1, 2, 3, 4, 5, 6, 7, 8};
int i;
//這裡添加結點
for(i=0; i<sizeof(arrs)/sizeof(*arrs); ++i)
list_add(&head, __lint_new(arrs[i]));
__lint_puts(head);
//這裡刪除一個結點
free(list_pop(&head, 0));
__lint_puts(head);
//刪除第二個結點
free(list_pop(&head, 1));
__lint_puts(head);
list_destroy(&head);
return 0;
}
測試了幾個簡答接口. 注釋比較詳細, 寫的也比較簡單相對於Linux內核的數據結構而言. 這裡是個開門紅.
臨摹幾遍都能理解C接口的簡單設計.
正文
其實呀上面代碼主要突出一個設計, 實現而言還是比較容易,因為結構有了,算法就能夠寫好了. 例如 獲取某個結點的源碼
/*
* 這裡獲取當前鏈表長度, 推薦調用一次就記住len
* h : 當前鏈表的頭結點
* : 返回 鏈表長度 >=0
*/
int list_len(list_t h)
{
int len = 0;
while(h){
++len;
h = list_next(h);
}
return len;
}
很基礎也容易理解, 大多數代碼其實結構設計好實現也就是時間問題, 也等同於業務了. 精妙的東西沒有那麼多, 魔鬼藏在細節裡.向那些這個池那個組,都名次解釋.
很普通.現在我們只談設計, 最後會給出完整的代碼. 同樣還有一種結構, (狀態不好,加班太多了,寫的很水望見諒,因為很多東西說出來還是做不出來,做出來說的不好.)
看下面關於簡單字符串設計代碼
#ifndef _H_TSTRING
#define _H_TSTRING
#include <schead.h>
//------------------------------------------------簡單字符串輔助操作----------------------------------
/*
* 主要采用jshash 返回計算後的hash值
* 不沖突率在 80% 左右還可以, 不要傳入NULL
*/
extern unsigned str_hash(const char* str);
//------------------------------------------------簡單文本字符串輔助操作----------------------------------
#ifndef _STRUCT_TSTRING
#define _STRUCT_TSTRING
//簡單字符串結構,並定義文本字符串類型tstring
struct tstring {
char* str; //字符串實際保存的內容
int len; //當前字符串大小
int size; //字符池大小
};
typedef struct tstring* tstring;
#endif // !_STRUCT_TSTRING
//文本串棧上創建內容,不想用那些技巧了,就這樣吧
#define TSTRING_CREATE(var) \
struct tstring var = { NULL, 0, 0}
#define TSTRING_DESTROY(var) \
free(var.str)
/*
* tstring 的創建函數, 會根據str創建一個 tstring結構的字符串
*
* str : 待創建的字符串
*
* ret : 返回創建好的字符串,如果創建失敗返回NULL
*/
extern tstring tstring_create(const char* str);
/*
* tstring 完全銷毀函數
* tstr : 指向tsting字符串指針量的指針
*/
extern void tstring_destroy(tstring* tstr);
/*
* 向簡單文本字符串tstr中添加 一個字符c
* tstr : 簡單字符串對象
* c : 待添加的字符
* ret : 返回狀態碼 見 schead 中 _RT_EB 碼等
*/
extern int tstring_append(tstring tstr, int c);
/*
* 向簡單文本串中添加只讀字符串
* tstr : 文本串
* str : 待添加的素材串
* ret : 返回狀態碼主要是 _RT_EP _RT_EM
*/
extern int tstring_appends(tstring tstr, const char* str);
//------------------------------------------------簡單文件輔助操作----------------------------------
/*
* 簡單的文件幫助類,會讀取完畢這個文件內容返回,失敗返回NULL.
* 需要事後使用 tstring_destroy(&ret); 銷毀這個字符串對象
* path : 文件路徑
* ret : 返回創建好的字符串內容,返回NULL表示讀取失敗
*/
extern tstring file_malloc_readend(const char* path);
/*
* 文件寫入,沒有好說的,會返回 _RT_EP _RT_EM _RT_OK
* path : 文件路徑
* str : 待寫入的字符串
* ret : 返回寫入的結果
*/
extern int file_writes(const char* path, const char* str);
/*
* 文件追加內容, 添加str內同
* path : 文件路徑
* str : 待追加的文件內同
* : 返回值,主要是 _RT_EP _RT_EM _RT_OK 這些狀態
*/
extern int file_append(const char* path, const char* str);
#endif // !_H_TSTRING
這個串可以用在讀取一個大串,主要解決的問題是內存空間分配問題,還可以用.最大浪費就50%.
現在我們簡單說一下具體實現,其實一看
#ifndef _STRUCT_TSTRING
#define _STRUCT_TSTRING
//簡單字符串結構,並定義文本字符串類型tstring
struct tstring {
char* str; //字符串實際保存的內容
int len; //當前字符串大小
int size; //字符池大小
};
typedef struct tstring* tstring;
#endif // !_STRUCT_TSTRING
全部明白了. 就是 len表現當前str中保存的長度, size表現當前str的容量.分配代碼如下
//簡單分配函數,智力一定會分配內存的, len > size的時候調用這個函數
static int __tstring_realloc(tstring tstr, int len)
{
int size = tstr->size;
for (size = size < _INT_TSTRING ? _INT_TSTRING : size; size < len; size <<= 1)
;
//分配內存
char *nstr = realloc(tstr->str, size);
if (NULL == nstr) {
SL_NOTICE("realloc(tstr->str:0x%p, size:%d) is error!", tstr->str, size);
return _RT_EM;
}
tstr->str = nstr;
tstr->size = size;
return _RT_OK;
}
len是新的str大小.後面展現 全部的演示代碼.
#include <tstring.h>
#include <sclog.h>
/*
* 主要采用jshash 返回計算後的hash值
* 不沖突率在 80% 左右還可以, 不要傳入NULL
*/
unsigned
str_hash(const char* str)
{
size_t i, h = strlen(str), sp = (h >> 5) + 1;
unsigned char* ptr = (unsigned char*)str;
for (i = h; i >= sp; i -= sp)
h ^= ((h<<5) + (h>>2) + ptr[i-1]);
return h ? h : 1;
}
/*
* tstring 的創建函數, 會根據str創建一個 tstring結構的字符串
*
* str : 待創建的字符串
*
* ret : 返回創建好的字符串,如果創建失敗返回NULL
*/
tstring
tstring_create(const char* str)
{
tstring tstr = calloc(1, sizeof(struct tstring));
if (NULL == tstr) {
SL_NOTICE("calloc is sizeof struct tstring error!");
return NULL;
}
tstring_appends(tstr, str);
return tstr;
}
/*
* tstring 完全銷毀函數
* tstr : 指向tsting字符串指針量的指針
*/
void tstring_destroy(tstring* tstr)
{
if (tstr && *tstr) { //展現內容
free((*tstr)->str);
free(*tstr);
*tstr = NULL;
}
}
//文本字符串創建的度量值
#define _INT_TSTRING (32)
//簡單分配函數,智力一定會分配內存的, len > size的時候調用這個函數
static int __tstring_realloc(tstring tstr, int len)
{
int size = tstr->size;
for (size = size < _INT_TSTRING ? _INT_TSTRING : size; size < len; size <<= 1)
;
//分配內存
char *nstr = realloc(tstr->str, size);
if (NULL == nstr) {
SL_NOTICE("realloc(tstr->str:0x%p, size:%d) is error!", tstr->str, size);
return _RT_EM;
}
tstr->str = nstr;
tstr->size = size;
return _RT_OK;
}
/*
* 向簡單文本字符串tstr中添加 一個字符c
* tstr : 簡單字符串對象
* c : 待添加的字符
* ret : 返回狀態碼 見 schead 中 _RT_EM 碼等
*/
int tstring_append(tstring tstr, int c)
{
//不做安全檢查
int len = tstr->len + 2; // c + '\0' 而len只指向 字符串strlen長度
//需要進行內存分配,唯一損失
if ((len > tstr->size) && (_RT_EM == __tstring_realloc(tstr, len)))
return _RT_EM;
tstr->len = --len;
tstr->str[len - 1] = c;
tstr->str[len] = '\0';
return _RT_OK;
}
/*
* 向簡單文本串中添加只讀字符串
* tstr : 文本串
* str : 待添加的素材串
* ret : 返回狀態碼主要是 _RT_EP _RT_EM
*/
int tstring_appends(tstring tstr, const char* str)
{
int len;
if (!tstr || !str || !*str) {
SL_NOTICE("check param '!tstr || !str || !*str'");
return _RT_EP;
}
len = tstr->len + strlen(str) + 1;
if ((len > tstr->size) && (_RT_EM == __tstring_realloc(tstr, len)))
return _RT_EM;
//這裡復制內容
strcpy(tstr->str + tstr->len, str);
tstr->len = len - 1;
return _RT_OK;
}
//------------------------------------------------簡單文件輔助操作----------------------------------
/*
* 簡單的文件幫助類,會讀取完畢這個文件內容返回,失敗返回NULL.
* 需要事後使用 tstring_destroy(&ret); 銷毀這個字符串對象
* path : 文件路徑
* ret : 返回創建好的字符串內容,返回NULL表示讀取失敗
*/
tstring file_malloc_readend(const char* path)
{
int c;
tstring tstr;
FILE* txt = fopen(path, "r");
if (NULL == txt) {
SL_NOTICE("fopen r path = '%s' error!", path);
return NULL;
}
//這裡創建文件對象,創建失敗直接返回
if ((tstr = tstring_create(NULL)) == NULL) {
fclose(txt);
return NULL;
}
//這裡讀取文本內容
while ((c = fgetc(txt))!=EOF)
if (_RT_OK != tstring_append(tstr, c))
break;
fclose(txt);//很重要創建了就要釋放,否則會出現隱藏的句柄bug
return tstr;
}
/*
* 文件寫入,沒有好說的,會返回 _RT_EP _RT_EM _RT_OK
* path : 文件路徑
* str : 待寫入的字符串
* ret : 返回寫入的結果
*/
int file_writes(const char* path, const char* str)
{
FILE* txt;
//檢查參數問題
if (!path || !str) {
SL_NOTICE("check is '!path || !str'");
return _RT_EP;
}
if ((txt = fopen(path, "w")) == NULL) {
SL_NOTICE("fopen w path = '%s' error!", path);
return _RT_EF;
}
//這裡寫入信息
fputs(str, txt);
fclose(txt);
return _RT_OK;
}
/*
* 文件追加內容, 添加str內同
* path : 文件路徑
* str : 待追加的文件內同
* : 返回值,主要是 _RT_EP _RT_EM _RT_OK 這些狀態
*/
int
file_append(const char* path, const char* str)
{
FILE* txt;
//檢查參數問題
if (!path || !str) {
SL_NOTICE("check is '!path || !str'");
return _RT_EP;
}
if ((txt = fopen(path, "a")) == NULL) {
SL_NOTICE("fopen a path = '%s' error!", path);
return _RT_EF;
}
//這裡寫入信息
fputs(str, txt);
fclose(txt);
return _RT_OK;
}
相比雲風的那個玩具要簡單的多,而且針對性很強,就為了大字符串. 轉存用.還可以一試.
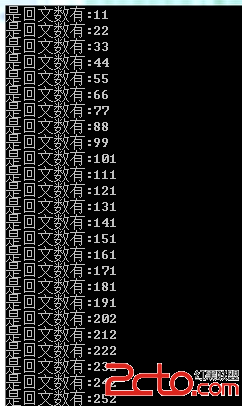
到這裡就到了今天一個主題. 主要測試list demo. 首先看運行的結果圖
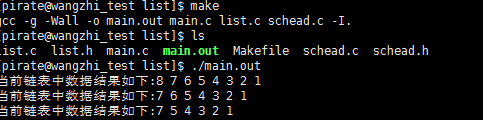
首先看Makefile 文件
main.out:main.c list.c schead.c
gcc -g -Wall -o $@ $^ -I.
再看schead.h 文件
#ifndef _H_CHEAD
#define _H_CHEAD
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <errno.h>
#include <string.h>
#include <time.h>
#include <stdint.h>
#include <stddef.h>
/*
* 1.0 錯誤定義宏 用於判斷返回值狀態的狀態碼 _RF表示返回標志
* 使用舉例 :
int flag = scconf_get("pursue");
if(flag != _RT_OK){
sclog_error("get config %s error! flag = %d.", "pursue", flag);
exit(EXIT_FAILURE);
}
* 這裡是內部 使用的通用返回值 標志
*/
#define _RT_OK (0) //結果正確的返回宏
#define _RT_EB (-1) //錯誤基類型,所有錯誤都可用它,在不清楚的情況下
#define _RT_EP (-2) //參數錯誤
#define _RT_EM (-3) //內存分配錯誤
#define _RT_EC (-4) //文件已經讀取完畢或表示鏈接關閉
#define _RT_EF (-5) //文件打開失敗
/*
* 1.1 定義一些 通用的函數指針幫助,主要用於基庫的封裝中
* 有構造函數, 釋放函數, 比較函數等
*/
typedef void* (*pnew_f)();
typedef void(*vdel_f)(void* node);
// icmp_f 最好 是 int cmp(const void* ln,const void* rn); 標准結構
typedef int(*icmp_f)();
/*
* 1.2 最簡單的 判斷字符串是否為空白字符代碼, true為真
*/
#define sh_isspace(c) \
(c==' '||c=='\t'||c=='\n'||c=='\r'||c=='\v'||c=='\f')
/*
* 2.0 如果定義了 __GNUC__ 就假定是 使用gcc 編譯器,為Linux平台
* 否則 認為是 Window 平台,不可否認宏是丑陋的
*/
#if defined(__GNUC__)
//下面是依賴 Linux 實現,等待毫秒數
#include <unistd.h>
#include <sys/time.h>
#define SLEEPMS(m) \
usleep(m * 1000)
#else
// 這裡創建等待函數 以毫秒為單位 , 需要依賴操作系統實現
#include <Windows.h>
#include <direct.h> // 加載多余的頭文件在 編譯階段會去掉
#define inline __inline //附加一個內聯函數宏
#define rmdir _rmdir
/**
* Linux sys/time.h 中獲取時間函數在Windows上一種移植實現
**tv : 返回結果包含秒數和微秒數
**tz : 包含的時區,在window上這個變量沒有用不返回
** : 默認返回0
**/
extern int gettimeofday(struct timeval* tv, void* tz);
//為了解決 不通用功能
#define localtime_r(t, tm) localtime_s(tm, t)
#define SLEEPMS(m) \
Sleep(m)
#endif /*__GNUC__ 跨平台的代碼都很丑陋 */
//3.0 浮點數據判斷宏幫助, __開頭表示不希望你使用的宏
#define __DIFF(x, y) ((x)-(y)) //兩個表達式做差宏
#define __IF_X(x, z) ((x)<z&&(x)>-z) //判斷宏,z必須是宏常量
#define EQ(x, y, c) EQ_ZERO(__DIFF(x,y), c) //判斷x和y是否在誤差范圍內相等
//3.1 float判斷定義的宏
#define _FLOAT_ZERO (0.000001f) //float 0的誤差判斷值
#define EQ_FLOAT_ZERO(x) __IF_X(x,_FLOAT_ZERO) //float 判斷x是否為零是返回true
#define EQ_FLOAT(x, y) EQ(x, y, _FLOAT_ZERO) //判斷表達式x與y是否相等
//3.2 double判斷定義的宏
#define _DOUBLE_ZERO (0.000000000001) //double 0誤差判斷值
#define EQ_DOUBLE_ZERO(x) __IF_X(x,_DOUBLE_ZERO) //double 判斷x是否為零是返回true
#define EQ_DOUBLE(x,y) EQ(x, y, _DOUBLE_ZERO) //判斷表達式x與y是否相等
//4.0 控制台打印錯誤信息, fmt必須是雙引號括起來的宏
#ifndef CERR
#define CERR(fmt, ...) \
fprintf(stderr,"[%s:%s:%d][error %d:%s]" fmt "\r\n",\
__FILE__, __func__, __LINE__, errno, strerror(errno),##__VA_ARGS__)
#endif/* !CERR */
//4.1 控制台打印錯誤信息並退出, t同樣fmt必須是 ""括起來的字符串常量
#ifndef CERR_EXIT
#define CERR_EXIT(fmt,...) \
CERR(fmt,##__VA_ARGS__),exit(EXIT_FAILURE)
#endif/* !ERR */
#ifndef IF_CERR
/*
*4.2 if 的 代碼檢測
*
* 舉例:
* IF_CERR(fd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP), "socket create error!");
* 遇到問題打印日志直接退出,可以認為是一種簡單模板
* code : 要檢測的代碼
* fmt : 必須是""括起來的字符串宏
* ... : 後面的參數,參照printf
*/
#define IF_CERR(code, fmt, ...) \
if((code) < 0) \
CERR_EXIT(fmt, ##__VA_ARGS__)
#endif //!IF_CERR
//5.0 獲取數組長度,只能是數組類型或""字符串常量,後者包含'\0'
#ifndef LEN
#define LEN(arr) \
(sizeof(arr)/sizeof(*(arr)))
#endif/* !ARRLEN */
//6.0 程序清空屏幕函數
#ifndef CONSOLE_CLEAR
#ifndef _WIN32
#define CONSOLE_CLEAR() \
system("printf '\ec'")
#else
#define CONSOLE_CLEAR() \
system("cls")
#endif/* _WIN32 */
#endif /*!CONSOLE_CLEAR*/
//7.0 置空操作
#ifndef BZERO
//v必須是個變量
#define BZERO(v) \
memset(&v,0,sizeof(v))
#endif/* !BZERO */
//9.0 scanf 健壯的
#ifndef SAFETY_SCANF
#define SAFETY_SCANF(scanf_code,...) \
while(printf(__VA_ARGS__),scanf_code){\
while(getchar()!='\n');\
puts("輸入出錯,請按照提示重新操作!");\
}\
while(getchar()!='\n')
#endif /*!SAFETY_SCANF*/
//10.0 簡單的time幫助宏
#ifndef TIME_PRINT
#define TIME_PRINT(code) {\
clock_t __st,__et;\
__st=clock();\
code\
__et=clock();\
printf("當前代碼塊運行時間是:%lf秒\n",(0.0+__et-__st)/CLOCKS_PER_SEC);\
}
#endif /*!TIME_PRINT*/
//11.0 等待的宏 這裡 已經處理好了
#define _STR_PAUSEMSG "請按任意鍵繼續. . ."
extern void sh_pause(void);
#ifndef INIT_PAUSE
# ifdef _DEBUG
# define INIT_PAUSE() atexit(sh_pause)
# else
# define INIT_PAUSE() (void)316 /* 別說了,都重新開始吧 */
# endif
#endif/* !INIT_PAUSE */
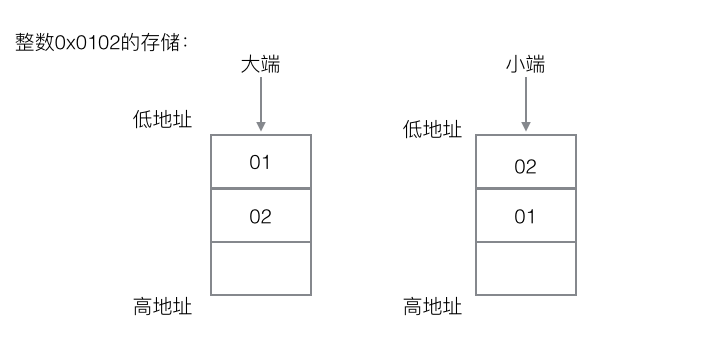
//12.0 判斷是大端序還是小端序,大端序返回true
extern bool sh_isbig(void);
/**
* sh_free - 簡單的釋放內存函數,對free再封裝了一下
**可以避免野指針
**pobj:指向待釋放內存的指針(void*)
**/
extern void sh_free(void** pobj);
/**
* 獲取 當前時間串,並塞入tstr中長度並返回
** 使用舉例
char tstr[64];
puts(gettimes(tstr, LEN(tstr)));
**tstr : 保存最後生成的最後串
**len : tstr數組的長度
** : 返回tstr首地址
**/
extern int sh_times(char tstr[], int len);
#endif/* ! _H_CHEAD */
主要是跨平台的一些幫助宏,開發中用到的通用宏.具體schead.c實現如下
#include <schead.h>
//簡單通用的等待函數
void
sh_pause(void)
{
rewind(stdin);
printf(_STR_PAUSEMSG);
getchar();
}
//12.0 判斷是大端序還是小端序,大端序返回true
bool
sh_isbig(void)
{
static union {
unsigned short _s;
unsigned char _cs[sizeof(unsigned short)];
} __ut = { 1 };
return __ut._cs[0] == 0;
}
/**
* sh_free - 簡單的釋放內存函數,對free再封裝了一下
**可以避免野指針
**@pobj:指向待釋放內存的指針(void*)
**/
void
sh_free(void** pobj)
{
if (pobj == NULL || *pobj == NULL)
return;
free(*pobj);
*pobj = NULL;
}
#if defined(_MSC_VER)
/**
* Linux sys/time.h 中獲取時間函數在Windows上一種移植實現
**tv : 返回結果包含秒數和微秒數
**tz : 包含的時區,在window上這個變量沒有用不返回
** : 默認返回0
**/
int
gettimeofday(struct timeval* tv, void* tz)
{
time_t clock;
struct tm tm;
SYSTEMTIME wtm;
GetLocalTime(&wtm);
tm.tm_year = wtm.wYear - 1900;
tm.tm_mon = wtm.wMonth - 1; //window的計數更好寫
tm.tm_mday = wtm.wDay;
tm.tm_hour = wtm.wHour;
tm.tm_min = wtm.wMinute;
tm.tm_sec = wtm.wSecond;
tm.tm_isdst = -1; //不考慮夏令時
clock = mktime(&tm);
tv->tv_sec = (long)clock; //32位使用,接口已經老了
tv->tv_usec = wtm.wMilliseconds * 1000;
return _RT_OK;
}
#endif
/**
* 獲取 當前時間串,並塞入tstr中C長度並返回
** 使用舉例
char tstr[64];
puts(gettimes(tstr, LEN(tstr)));
**tstr : 保存最後生成的最後串
**len : tstr數組的長度
** : 返回tstr首地址
**/
int
sh_times(char tstr[], int len)
{
struct tm st;
time_t t = time(NULL);
localtime_r(&t, &st);
return (int)strftime(tstr, len, "%F %X", &st);
}
後面是list.c的具體實現了
#include <list.h>
/*
* 采用頭查法插入結點, 第一使用需要 list_t head = NULL;
*返回 _RT_OK 表示成功!
* ph : 指向頭結點的指針
* node : 待插入的結點對象
*/
int
list_add(list_t* ph, void* node)
{
if (ph == NULL || node == NULL){
CERR("list_add 檢查到(pal == NULL || node == NULL)!");
return _RT_EP;
}
list_next(node) = *ph;
*ph = node;
return _RT_OK;
}
/*
* 鏈表中查找函數,查找失敗返回NULL,查找成功直接返回那個結點,推薦不要亂改,否則就崩了.
*如果需要改的話,推薦 用 list_findpop, 找到並彈出
* h : 鏈表頭結點
* cmp : 查找的比較函數
* left : cmp(left, right) 用的左結點
* : 返回查找的結點對象
*/
void*
list_find(list_t h, icmp_f cmp, const void* left)
{
struct __lnode* head;
if(cmp == NULL || left == NULL){
CERR("list_find 檢查到(cmp == NULL || left == NULL)!");
return NULL;
}
//找到結果直接結束
for(head = h; head; head = head->next)
if(cmp(left, head) == 0)
break;
return head;
}
/*
* 查找到要的結點,並彈出,需要你自己回收
* ph : 指向頭結點的指針
* cmp : 比較函數,將left同 *ph中對象按個比較
* left : cmp(left, x) 比較返回 0 >0 <0
* : 找到了退出/返回結點, 否則返回NULL
*/
void*
list_findpop(list_t *ph, icmp_f cmp, const void* left)
{
struct __lnode *head, *tmp;
if((!ph) || (!cmp) || (!left) || !(head = *ph)){
CERR("check find {(!ph) || (!cmp) || (!left) || !(head = *ph)}!");
return NULL;
}
//頭部檢測
if(cmp(left, head) == 0){
*ph = head->next;
return head;
}
//後面就是普通的
while((tmp = head->next)){
if(cmp(left, tmp) == 0){
head->next = tmp->next;
break;
}
head = tmp;
}
return tmp; //仍然沒有找見
}
/*
* 這裡獲取當前鏈表長度, 推薦調用一次就記住len
* h : 當前鏈表的頭結點
* : 返回 鏈表長度 >=0
*/
int list_len(list_t h)
{
int len = 0;
while(h){
++len;
h = list_next(h);
}
return len;
}
/*
* 查找索引位置為idx的結點,找不見返回NULL
* h : 當前結點
* idx : 查找的索引值[0,len)
* : 返回查到的結點,如果需要刪除的推薦調用 list_pop(&h, idx);
*/
void*
list_get(list_t h, int idx)
{
if(h==NULL || idx < 0){
CERR("check is {h==NULL || idx < 0}");
return NULL;
}
//主要查找函數,代碼還是比較精簡的還是值得學習的
while(h){
if(idx-- == 0)
return h;
h = list_next(h);
}
if(idx > 0)
CERR("check is idx >= length!, idx-length=%d.", idx);
return NULL;
}
/*
* 按照索引彈出並返回結點, 需要自己回收這個結點 推薦 free(list_pop...);
* ph : 指向鏈表結點的指針
* idx : 彈出的索引
* return : 無效的彈出,返回NULL
*/
void*
list_pop(list_t* ph, int idx)
{
struct __lnode *head, *front;//第一個是要找的結點,後面是它的前驅結點
if((!ph) || (idx<0) || !(head=*ph)){
CERR("check is {(!ph) || (idx<0) || !(head=*ph)}");
return NULL;
}
for(front = NULL; head && idx>0; --idx){
front = head;
head = head->next;
--idx;
}
if(idx>0){
CERR("check is idx>length, idx-length = %d.", idx);
return NULL;
}
//下面就是找到的請況,返回結果
if(front == NULL)
*ph = head->next;
else
front->next = head->next;
return head;
}
/*
* 返回結點node 的上一個結點,如果node = NULL, 返回最後一個結點
* h : 當前鏈表結點
* node : 待查找的結點信息
* return : 返回查找到的結點,不存在返回NULL
*/
void*
list_front(list_t h, void* node)
{
struct __lnode* head = h; //直接跑到崩潰同strcpy
while(head->next && head->next != node)
head = head->next;
return head->next == node ? head : NULL;
}
/*
* 和 list_add 功能相似,但是插入位置在尾巴那
* ph : 待插入結點的指針
* node : 待插入的當前結點
*/
int
list_addlast(list_t* ph, void* node)
{
struct __lnode* head;
if(!ph || !node){
CERR("check is {!ph || !node}! not nothing in it!");
return _RT_EP;
}
list_next(node) = NULL;//將這個結點的置空
if(!(head=*ph)){ //插入的是頭結點直接返回
*ph = node;
return _RT_OK;
}
while(head->next)
head = head->next;
head->next = node;
return _RT_OK;
}
/*
* 在鏈表的第idx索引處插入結點,也必須需要 list_t head = NULL; 在idx過大的時候
*插入尾巴處,如果<0直接返回 _RT_EP. 成功了返回 _RT_OK
* ph : 指向頭結點的指針
* idx : 結點的索引處
* node : 待插入的結點
*/
int
list_addidx(list_t* ph, int idx, void* node)
{
struct __lnode* head;
if(!ph || idx<0 || !node){ //以後可能加入 idx < 0的尾巴插入細則
CERR("check is {!ph || idx<0 || !node}! Don't naughty again!");
return _RT_EP;
}
//插入做為頭結點
if(!(head=*ph) || idx == 0){
list_next(node) = *ph;
*ph = node;
return _RT_OK;
}
while(head->next && idx>1){
--idx;
head = head->next;
}
list_next(node) = head->next;
head->next = node;
return _RT_OK;
}
/*
* 這裡的銷毀函數,只有這些數據都是棧上的才推薦這麼做,會自動讓其指向NULL
* ph : 指向當前鏈表結點的指針
*/
void
list_destroy(list_t* ph)
{
struct __lnode *head, *next;
if((!ph) || !(head=*ph))
return;
do{ //do 循環可以省略一次判斷,但是有點丑陋
next = head->next;
free(head);
}while((head=next));
*ph = NULL;
}
關於list寫的比較多,也有一點簡單理解,上面雖然簡陋,但是很精簡,很指導不知道朋友學習使用,很通用的實在庫. 到這裡我們的一些都
這麼隨意的介紹完了.
再次分享個人學習習慣,別人說的太多,還是不懂,直接讓我看代碼就可以了,每次都是對著代碼敲明白了.當然老外的書說的很明白,不得不服.
一下就懂了. 每一個大功能都是一個個小模塊組成了, 沒經過坑坑窪窪, 自己都不相信自己可以. 不管怎麼選擇都很公平,需要是 用 高付出, 在第8號當鋪典當
你想要的東西.
共勉.希望的我的家人常快樂, 兒子在外對不住您們了, 目送飛雲,一切安好!

後記
錯誤是難免的,歡迎交流技術. 其實這個框架整體代碼去年早就寫好了, 後面有了點項目感悟,重新構建一下,提升性能,
就簡單分享在這,值得和我一樣菜的人學習交流. 設計很重要,但絕壁不是設計模式. 拜~,有機會 下次再分享感悟.