一、簡介
跳表(skiplist)是一個非常優秀的數據結構,實現簡單,插入、刪除、查找的復雜度均為O(logN)。LevelDB的核心數據結構是用跳表實現的,redis的sorted set數據結構也是有跳表實現的。代碼在這裡:http://flyingsnail.blog.51cto.com/5341669/1020034
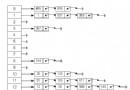
二、跳表圖解
考慮一個有序表:
從該有序表中搜索元素 < 23, 43, 59 > ,需要比較的次數分別為 < 2, 4, 6 >,總共比較的次數
為 2 + 4 + 6 = 12 次。有沒有優化的算法嗎? 鏈表是有序的,但不能使用二分查找。類似二叉
搜索樹,我們把一些節點提取出來,作為索引。得到如下結構:
這裡我們把 < 14, 34, 50, 72 > 提取出來作為一級索引,這樣搜索的時候就可以減少比較次數了。
我們還可以再從一級索引提取一些元素出來,作為二級索引,變成如下結構:
這裡元素不多,體現不出優勢,如果元素足夠多,這種索引結構就能體現出優勢來了。
這基本上就是跳表的核心思想,其實也是一種通過“空間來換取時間”的一個算法,通過在每個節點中增加了向前的指針,從而提升查找的效率。
跳表
下面的結構是就是跳表:
其中 -1 表示 INT_MIN, 鏈表的最小值,1 表示 INT_MAX,鏈表的最大值。
跳表具有如下性質:
(1) 由很多層結構組成
(2) 每一層都是一個有序的鏈表
(3) 最底層(Level 1)的鏈表包含所有元素
(4) 如果一個元素出現在 Level i 的鏈表中,則它在 Level i 之下的鏈表也都會出現。
(5) 每個節點包含兩個指針,一個指向同一鏈表中的下一個元素,一個指向下面一層的元素。
三、源碼實現
https://github.com/begeekmyfriend/skiplist