邏輯上,所有thread是並行的,但是,從硬件的角度來說,實際上並不是所有的thread能夠在同一時刻執行,接下來我們將解釋有關warp的一些本質。
warp是SM的基本執行單元。一個warp包含32個並行thread,這32個thread執行於SMIT模式。也就是說所有thread執行同一條指令,並且每個thread會使用各自的data執行該指令。
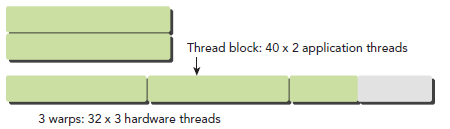
block可以是一維二維或者三維的,但是,從硬件角度看,所有的thread都被組織成一維,每個thread都有個唯一的ID。ID的計算可以在之前的博文查看。
每個block的warp數量可以由下面的公式計算獲得:
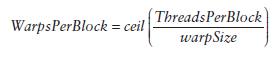
一個warp中的線程必然在同一個block中,如果block所含線程數目不是warp大小的整數倍,那麼多出的那些thread所在的warp中,會剩余一些inactive的thread,也就是說,即使湊不夠warp整數倍的thread,硬件也會為warp湊足,只不過那些thread是inactive狀態,需要注意的是,即使這部分thread是inactive的,也會消耗SM資源。
控制流語句普遍存在於各種編程語言中,GPU支持傳統的,C-style,顯式控制流結構,例如if…else,for,while等等。
CPU有復雜的硬件設計可以很好的做分支預測,即預測應用程序會走哪個path。如果預測正確,那麼CPU只會有很小的消耗。和CPU對比來說,GPU就沒那麼復雜的分支預測了(CPU和GPU這方面的差異的原因不是我們關心的,了解就好,我們關心的是由這差異引起的問題)。
這樣我們的問題就來了,因為所有同一個warp中的thread必須執行相同的指令,那麼如果這些線程在遇到控制流語句時,如果進入不同的分支,那麼同一時刻除了正在執行的分之外,其余分支都被阻塞了,十分影響性能。這類問題就是warp divergence。
請注意,warp divergence問題只會發生在同一個warp中。
下圖展示了warp divergence問題:
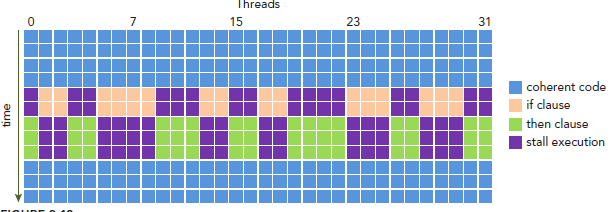
為了獲得最好的性能,就需要避免同一個warp存在不同的執行路徑。避免該問題的方法很多,比如這樣一個情形,假設有兩個分支,分支的決定條件是thread的唯一ID的奇偶性:
__global__ void mathKernel1(float *c) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a, b;
a = b = 0.0f;
if (tid % 2 == 0) {
a = 100.0f;
} else {
b = 200.0f;
}
c[tid] = a + b;
}
一種方法是,將條件改為以warp大小為步調,然後取奇偶,如下:
__global__ void mathKernel2(void) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a, b;
a = b = 0.0f;
if ((tid / warpSize) % 2 == 0) {
a = 100.0f;
} else {
b = 200.0f;
}
c[tid] = a + b;
}
代碼:

編譯運行:
$ nvcc -O3 -arch=sm_20 simpleDivergence.cu -o simpleDivergence $./simpleDivergence
輸出:
$ ./simpleDivergence using Device 0: Tesla M2070 Data size 64 Execution Configuration (block 64 grid 1) Warmingup elapsed 0.000040 sec mathKernel1 elapsed 0.000016 sec mathKernel2 elapsed 0.000014 sec
我們也可以直接使用nvprof(之後會詳細介紹)這個工具來度量性能:
$ nvprof --metrics branch_efficiency ./simpleDivergence
輸出為:
Kernel: mathKernel1(void) 1 branch_efficiency Branch Efficiency 100.00% 100.00% 100.00% Kernel: mathKernel2(void) 1 branch_efficiency Branch Efficiency 100.00% 100.00% 100.00%
Branch Efficiency的定義如下:
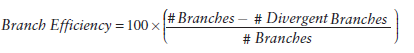
到這裡你應該在奇怪為什麼二者表現相同呢,實際上當我們的代碼很簡單,可以被預測時,CUDA的編譯器會自動幫助優化我們的代碼。稍微提一下GPU分支預測(理解的有點暈,不過了解下就好),這裡,一個被稱為預測變量的東西會被設置成1或者0,所有分支都會得到執行,但是只有預測值為1時,才會得到執行。當條件狀態少於某一個阈值時,編譯器會將一個分支指令替換為預測指令,因此,現在回到自動優化問題,一份較長的代碼就會導致warp divergence了。
可以使用下面的命令強制編譯器不優化(貌似不怎麼管用):
$ nvcc -g -G -arch=sm_20 simpleDivergence.cu -o simpleDivergence
一個warp的context包括以下三部分:
再次重申,在同一個執行context中切換是沒有消耗的,因為在整個warp的生命期內,SM處理的每個warp的執行context都是on-chip的。
每個SM有一個32位register集合放在register file中,還有固定數量的shared memory,這些資源都被thread瓜分了,由於資源是有限的,所以,如果thread比較多,那麼每個thread占用資源就叫少,thread較少,占用資源就較多,這需要根據自己的要求作出一個平衡。
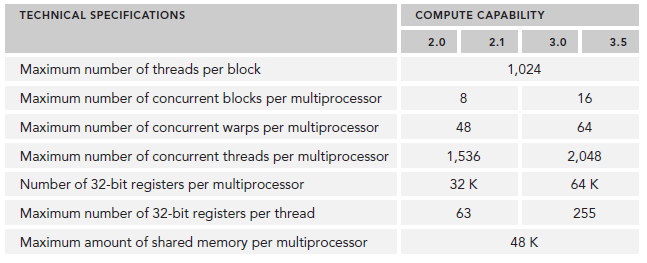
資源限制了駐留在SM中blcok的數量,不同的device,register和shared memory的數量也不同,就像之前介紹的Fermi和Kepler的差別。如果沒有足夠的資源,kernel的啟動就會失敗。
當一個block或得到足夠的資源時,就成為active block。block中的warp就稱為active warp。active warp又可以被分為下面三類:
SM中warp調度器每個cycle會挑選active warp送去執行,一個被選中的warp稱為selected warp,沒被選中,但是已經做好准備被執行的稱為Eligible warp,沒准備好要執行的稱為Stalled warp。warp適合執行需要滿足下面兩個條件:
例如,Kepler任何時刻的active warp數目必須少於或等於64個(GPU架構篇有介紹)。selected warp數目必須小於或等於4個(因為scheduler有4個?不確定)。如果一個warp阻塞了,調度器會挑選一個Eligible warp准備去執行。
CUDA編程中應該重視對計算資源的分配:這些資源限制了active warp的數量。因此,我們必須掌握硬件的一些限制,為了最大化GPU利用率,我們必須最大化active warp的數目。
指令從開始到結束消耗的clock cycle稱為指令的latency。當每個cycle都有eligible warp被調度時,計算資源就會得到充分利用,基於此,我們就可以將每個指令的latency隱藏於issue其它warp的指令的過程中。
和CPU編程相比,latency hiding對GPU非常重要。CPU cores被設計成可以最小化一到兩個thread的latency,但是GPU的thread數目可不是一個兩個那麼簡單。
當涉及到指令latency時,指令可以被區分為下面兩種:
顧名思義,Arithmetic instruction latency是一個算數操作的始末間隔。另一個則是指load或store的始末間隔。二者的latency大約為:
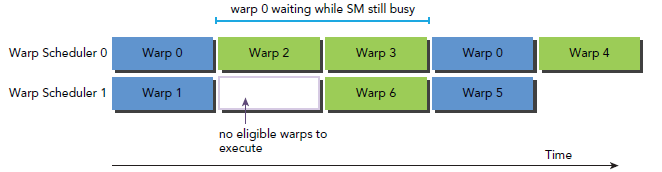
下圖是一個簡單的執行流程,當warp0阻塞時,執行其他的warp,當warp變為eligible時從新執行。
你可能想要知道怎樣評估active warps 的數量來hide latency。Little’s Law可以提供一個合理的估計:
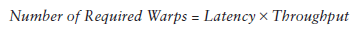
對於Arithmetic operations來說,並行性可以表達為用來hide Arithmetic latency的操作的數目。下表顯示了Fermi和Kepler相關數據,這裡是以(a + b * c)作為操作的例子。不同的算數指令,throughput(吞吐)也是不同的。
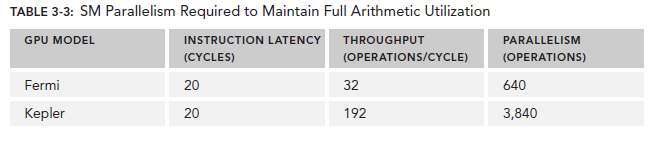
這裡的throughput定義為每個SM每個cycle的操作數目。由於每個warp執行同一種指令,因此每個warp對應32個操作。所以,對於Fermi來說,每個SM需要640/32=20個warp來保持計算資源的充分利用。這也就意味著,arithmetic operations的並行性可以表達為操作的數目或者warp的數目。二者的關系也對應了兩種方式來增加並行性:
對於Memory operations,並行性可以表達為每個cycle的byte數目。
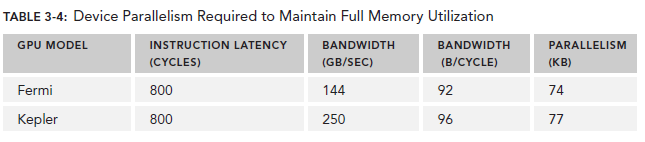
因為memory throughput總是以GB/Sec為單位,我們需要先作相應的轉化。可以通過下面的指令來查看device的memory frequency:
$ nvidia-smi -a -q -d CLOCK | fgrep -A 3 "Max Clocks" | fgrep "Memory"
以Fermi為例,其memory frequency可能是1.566GHz,Kepler的是1.6GHz。那麼轉化過程為:
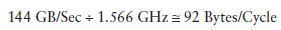
乘上這個92可以得到上圖中的74,這裡的數字是針對整個device的,而不是每個SM。
有了這些數據,我們可以做一些計算了,以Fermi為例,假設每個thread的任務是將一個float(4 bytes)類型的數據從global memory移至SM用來計算,你應該需要大約18500個thread,也就是579個warp來隱藏所有的memory latency。

Fermi有16個SM,所以每個SM需要579/16=36個warp來隱藏memory latency。
當一個warp阻塞了,SM會執行另一個eligible warp。理想情況是,每時每刻到保證cores被占用。Occupancy就是每個SM的active warp占最大warp數目的比例:
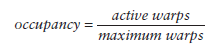
我們可以使用的device篇提到的方法來獲取warp最大數目:
cudaError_t cudaGetDeviceProperties(struct cudaDeviceProp *prop, int device);
然後用maxThreadsPerMultiProcessor來獲取具體數值。
grid和block的配置准則:
Occupancy專注於每個SM中可以並行的thread或者warp的數目。不管怎樣,Occupancy不是唯一的性能指標,Occupancy達到當某個值是,再做優化就可能不在有效果了,還有許多其它的指標需要調節,我們會在之後的博文繼續探討。
同步是並行編程的一個普遍的問題。在CUDA的世界裡,有兩種方式實現同步:
因為CUDA API和host代碼是異步的,cudaDeviceSynchronize可以用來停住CUP等待CUDA中的操作完成:
cudaError_t cudaDeviceSynchronize(void);
因為block中的thread執行順序不定,CUDA提供了一個function來同步block中的thread。
__device__ void __syncthreads(void);
當該函數被調用,block中的每個thread都會等待所有其他thread執行到某個點來實現同步。