線程的組織形式對程序的性能影響是至關重要的,本篇博文主要以下面一種情況來介紹線程組織形式:
一般,一個矩陣以線性存儲在global memory中的,並以行來實現線性:

在kernel裡,線程的唯一索引非常有用,為了確定一個線程的索引,我們以2D為例:
首先可以將thread和block索引映射到矩陣坐標:
ix = threadIdx.x + blockIdx.x * blockDim.x
iy = threadIdx.y + blockIdx.y * blockDim.y
之後可以利用上述變量計算線性地址:
idx = iy * nx + ix
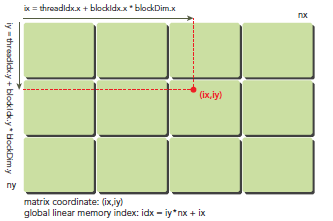
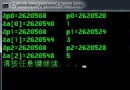
上圖展示了block和thread索引,矩陣坐標以及線性地址之間的關系。
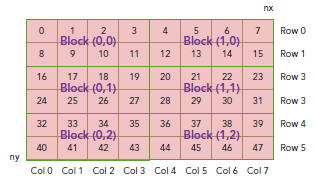
現在可以驗證出下面的關系:
thread_id(2,1)block_id(1,0) coordinate(6,1) global index 14 ival 14
下圖顯示了三者之間的關系:
int main(int argc, char **argv) {
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set up date size of matrix
int nx = 1<<14;
int ny = 1<<14;
int nxy = nx*ny;
int nBytes = nxy * sizeof(float);
printf("Matrix size: nx %d ny %d\n",nx, ny);
// malloc host memory
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
double iStart = cpuSecond();
initialData (h_A, nxy);
initialData (h_B, nxy);
double iElaps = cpuSecond() - iStart;
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// add matrix at host side for result checks
iStart = cpuSecond();
sumMatrixOnHost (h_A, h_B, hostRef, nx,ny);
iElaps = cpuSecond() - iStart;
// malloc device global memory
float *d_MatA, *d_MatB, *d_MatC;
cudaMalloc((void **)&d_MatA, nBytes);
cudaMalloc((void **)&d_MatB, nBytes);
cudaMalloc((void **)&d_MatC, nBytes);
// transfer data from host to device
cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice);
// invoke kernel at host side
int dimx = 32;
int dimy = 32;
dim3 block(dimx, dimy);
dim3 grid((nx+block.x-1)/block.x, (ny+block.y-1)/block.y);
iStart = cpuSecond();
sumMatrixOnGPU2D <<< grid, block >>>(d_MatA, d_MatB, d_MatC, nx, ny);
cudaDeviceSynchronize();
iElaps = cpuSecond() - iStart;
printf("sumMatrixOnGPU2D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid.x,
grid.y, block.x, block.y, iElaps);
// copy kernel result back to host side
cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost);
// check device results
checkResult(hostRef, gpuRef, nxy);
// free device global memory
cudaFree(d_MatA);
cudaFree(d_MatB);
cudaFree(d_MatC);
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
// reset device
cudaDeviceReset();
return (0);
}
編譯運行:
$ nvcc -arch=sm_20 sumMatrixOnGPU-2D-grid-2D-block.cu -o matrix2D $ ./matrix2D
輸出:
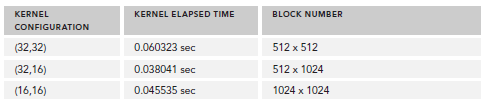
./a.out Starting... Using Device 0: Tesla M2070 Matrix size: nx 16384 ny 16384 sumMatrixOnGPU2D <<<(512,512), (32,32)>>> elapsed 0.060323 sec Arrays match.
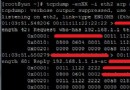
接下來,我們更改block配置為32x16,重新編譯,輸出為:
sumMatrixOnGPU2D <<<(512,1024), (32,16)>>> elapsed 0.038041 sec
可以看到,性能提升了一倍,直觀的來看,我們會認為第二個配置比第一個多了一倍的block所以性能提升一倍,實際上也確實是因為block增加了。但是,如果你繼續增加block的數量,則性能又會降低:
sumMatrixOnGPU2D <<< (1024,1024), (16,16) >>> elapsed 0.045535 sec
下圖展示了不同配置的性能;
關於性能的分析將在之後的博文中總結,現在只是了解下,本文在於掌握線程組織的方法。
代碼下載:CodeSamples.zip