SM(Streaming Multiprocessors)是GPU架構中非常重要的部分,GPU硬件的並行性就是由SM決定的。
以Fermi架構為例,其包含以下主要組成部分:
GPU中每個SM都設計成支持數以百計的線程並行執行,並且每個GPU都包含了很多的SM,所以GPU支持成百上千的線程並行執行,當一個kernel啟動後,thread會被分配到這些SM中執行。大量的thread可能會被分配到不同的SM,但是同一個block中的thread必然在同一個SM中並行執行。
CUDA采用Single Instruction Multiple Thread(SIMT)的架構來管理和執行thread,這些thread以32個為單位組成一個單元,稱作warps。warp中所有線程並行的執行相同的指令。每個thread擁有它自己的instruction address counter和狀態寄存器,並且用該線程自己的數據執行指令。
SIMT和SIMD(Single Instruction, Multiple Data)類似。二者都通過將同樣的指令廣播給多個執行官單元來實現並行。一個主要的不同就是,SIMD要求所有的vector element在一個統一的同步組裡同步的執行,而SIMT允許線程們在一個warp中獨立的執行。SIMT有三個SIMD沒有的主要特征:
一個block只會由一個SM調度,block一旦被分配好SM,該block就會一直駐留在該SM中,直到執行結束。一個SM可以同時擁有多個block。下圖顯示了軟件硬件方面的術語:
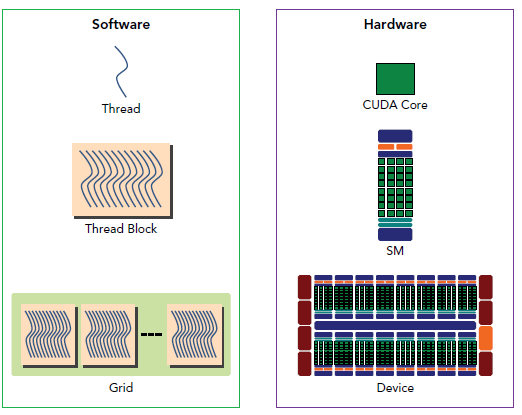
需要注意的是,大部分thread只是邏輯上並行,並不是所有的thread可以在物理上同時執行。這就導致,同一個block中的線程可能會有不同步調。
並行thread之間的共享數據回導致競態:多個線程請求同一個數據會導致未定義行為。CUDA提供了API來同步同一個block的thread以保證在進行下一步處理之前,所有thread都到達某個時間點。盡管如此,我們是沒有什麼原子操作來保證block內部的同步的。
同一個warp中的thread可以以任意順序執行,active warps被SM資源限制。當一個warp空閒時,SM就可以調度駐留在該SM中另一個可用warp。在並發的warp之間切換是沒什麼消耗的,因為硬件資源早就被分配到所有thread和block,所以該新調度的warp的狀態已經存儲在SM中了。
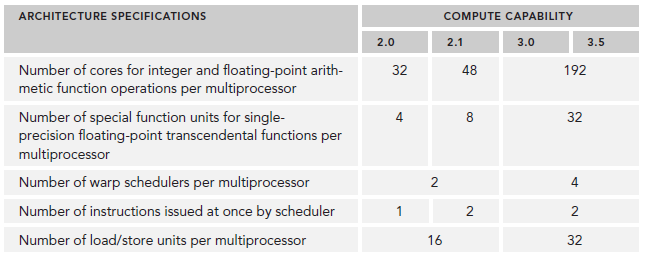
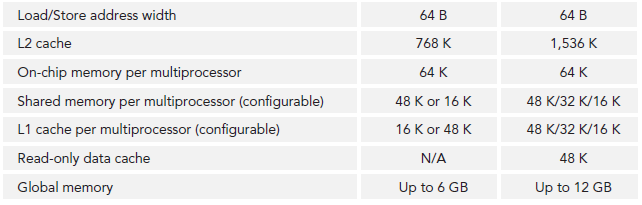
SM可以看做GPU的心髒,寄存器和共享內存是SM的稀缺資源。CUDA將這些資源分配給所有駐留在SM中的thread。因此,這些有限的資源就使每個SM中active warps有非常嚴格的限制,也就限制了並行能力。所以,掌握部分硬件知識,有助於CUDA性能提升。
Fermi是第一個完整的GPU計算架構。
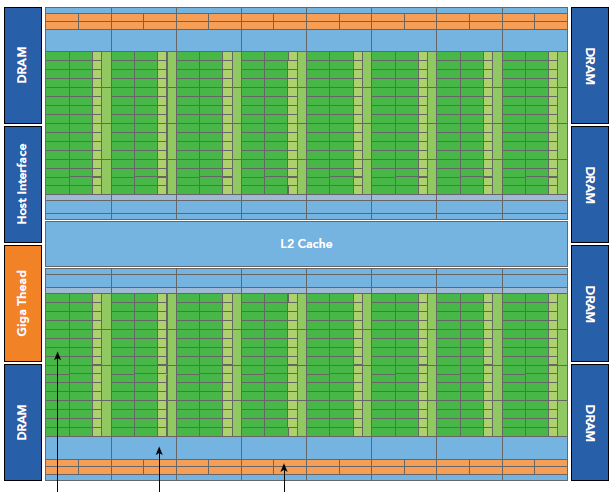
每個SM由一下幾部分組成:
Kepler相較於Fermi更快,效率更高,性能更好。
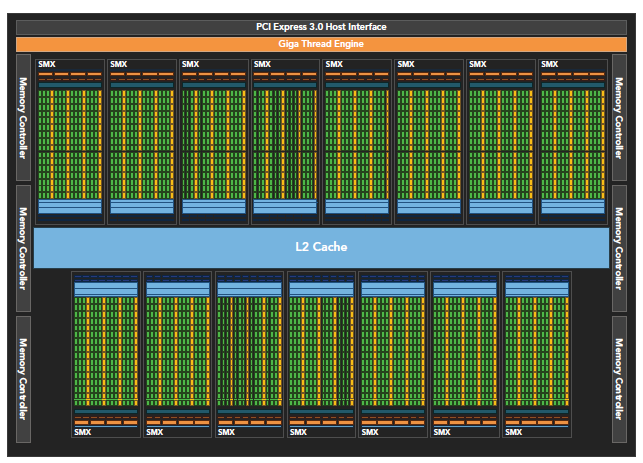
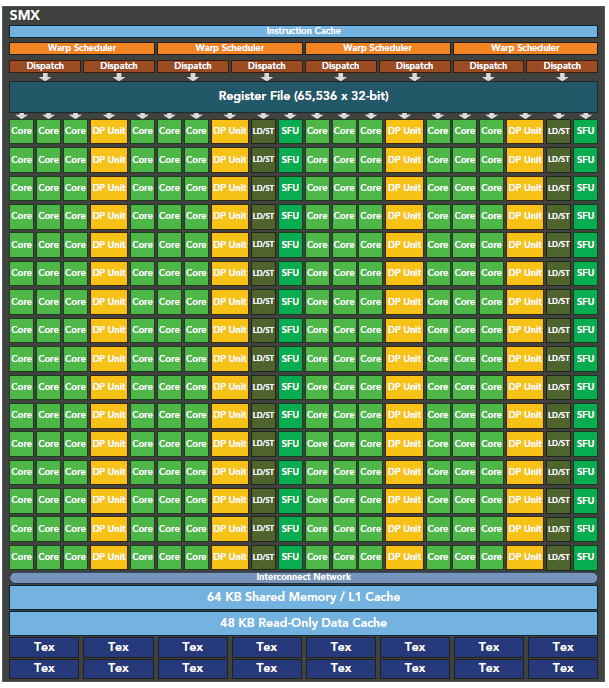
Dynamic Parallelism是Kepler的新特性,允許GPU動態的啟動新的Grid。有了這個特性,任何kernel內都可以啟動其它的kernel了。這樣直接實現了kernel的遞歸以及解決了kernel之間數據的依賴問題。也許D3D中光的散射可以用這個實現。
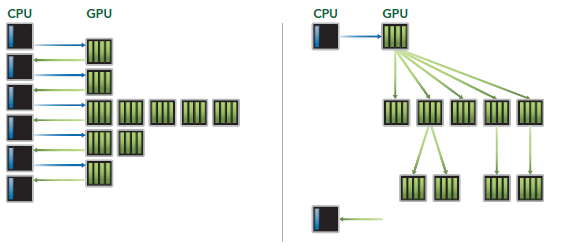
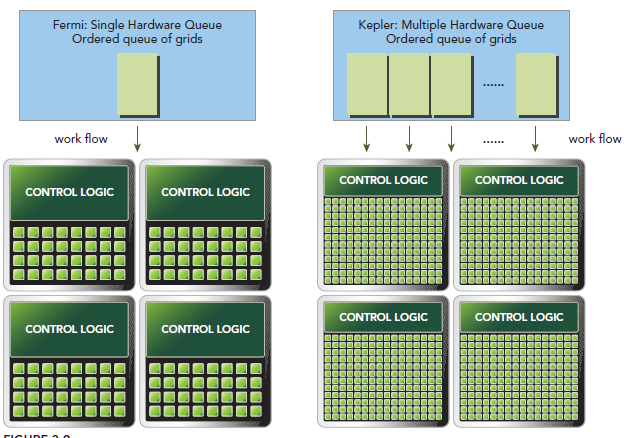
Hyper-Q是Kepler的另一個新特性,增加了CPU和GPU之間硬件上的聯系,使CPU可以在GPU上同時運行更多的任務。這樣就可以增加GPU的利用率減少CPU的閒置時間。Fermi依賴一個單獨的硬件上的工作隊列來從CPU傳遞任務給GPU,這樣在某個任務阻塞時,會導致之後的任務無法得到處理,Hyper-Q解決了這個問題。相應的,Kepler為GPU和CPU提供了32個工作隊列。