一、何謂字節對齊?
現代計算機中內存空間都是按照字節(byte)劃分的,從理論上講,似乎對任何類型變量的訪問都可以從任何地址開始,但實際情況是在訪問特定變量的時候,經常在特定的內存地址訪問,而不是順序的一個接一個的排放。為了使CPU能夠對變量進行快速訪問,變量的起始地址應該具有某些特性,即所謂的“字節對齊”。比如4字節的int型,其起始地址應該位於4字節的邊界上,即起始地址能夠被4整除。
在C語言中,結構體是一種復合數據類型,其構成元素既可以是基本數據類型(如int、long、float等)的變量,也可以是一些復合數據類型(如數組、結構體、聯合等)的數據單元。在結構體中,編譯器為結構體的每個成員按其自然邊界(alignment)分配空間,各個成員按照它們被聲明的順序在內存中順序存儲,第一個成員的地址和整個結構的地址相同。
二、字節對齊的作用和原因
各個硬件平台對存儲空間的處理上有很大的不同。一些平台(例如sparc系統對字節對齊非常嚴格)對某些特定類型的數據只能從某些特定地址開始存取。其他平台可能沒有這種情況, 但是如果不按照適合其平台的要求對數據存放進行對齊,會在存取效率上帶來損失。比如有些平台(例如x86)每次讀都是從偶地址開始,如果一個int型(假設為32位)如果存放在偶地址開始的地方,那麼一個讀周期就可以讀出;而如果存放在奇地址開始的地方,就需要2個讀周期,並對兩次讀出的結果的高低字節進行拼湊才能得到該int型數據。後者顯然在讀取效率上會下降很多,但存儲空間上可能比前者更緊湊,這也是空間和時間的取捨。
三、字節對齊原則
編譯器是按照什麼樣的原則進行對齊的?在我們繼續分析具體字節對齊問題之前,先讓我們看幾個重要的基本概念:
1.數據類型自身的對齊值:在32位x86機器上,對於char型數據,其自身對齊值為1字節;對於short型,其自身對齊為2字節;對於 int,long, float類型,其自身對齊值為4字節;
對於long long,double類型為8字節;對於基本類型的指針類型(其本質是 unsigned long型),其自身對齊為4字節。
2.結構體或者類的自身對齊值:其成員中自身對齊值最大的那個值。
3.指定對齊值:#pragma pack (value)時的指定對齊值value。
4.編譯器默認對齊值:一般與CPU字長位數相同,在32位機器上為4字節,64位機器上為8字節。未指定對齊值時,編譯器使用默認對齊值。
5.數據成員、結構體和類的有效對齊值:自身對齊值和指定對齊值中小的那個值。
有了這些值,我們就可以很方便的來討論具體數據結構的成員和其自身的對齊方式。有效對齊值N是最終用來決定數據存放地址方式的值,最重要。有效對齊N,就 是表示“對齊在N上”,也就是說該數據的"存放起始地址%N=0".而數據結構中的數據變量都是按定義的先後順序來排放的。第一個數據變量的起始地址就是 數據結構的起始地址。結構體的成員變量要對齊排放,結構體本身也要根據自身的有效對齊值圓整(就是結構體成員變量占用總長度需要是對結構體有效對齊值的整 數倍。
四、字節對齊舉例分析
根據字節對齊原則,結合下面例子理解,就明白了。
例子分析:
分析例子B;
struct B {
char b;
int a;
short c;
};
假設B從地址空間0x0000開始排放。該例子中沒有定義指定對齊值,在筆者環境下,該值默認為4。第一個成員變量b的自身對齊值是1,比指定或者默認指 定對齊值4小,所以其有效對齊值為1,所以其存放地址0x0000符合0x0000%1=0.第二個成員變量a,其自身對齊值為4,所以有效對齊值也為 4,所以只能存放在起始地址為0x0004到0x0007這四個連續的字節空間中,復核0x0004%4=0,且緊靠第一個變量。第三個變量c,自身對齊 值為2,所以有效對齊值也是2,可以存放在0x0008到0x0009這兩個字節空間中,符合0x0008%2=0。所以從0x0000到0x0009存 放的都是B內容。再看數據結構B的自身對齊值為其變量中最大對齊值(這裡是b)所以就是4,所以結構體的有效對齊值也是4。根據結構體圓整的要求, 0x0009到0x0000=10字節,(10+2)%4=0。所以0x0000A到0x000B也為結構體B所占用。故B從0x0000到0x000B 共有12個字節,sizeof(struct B)=12;
同理,分析上面例子C:
#pragma pack (2) /*指定按2字節對齊*/
struct C {
char b;
int a;
short c;
};
#pragma pack () /*取消指定對齊,恢復缺省對齊*/
第一個變量b的自身對齊值為1,指定對齊值為2,所以,其有效對齊值為1,假設C從0x0000開始,那麼b存放在0x0000,符合0x0000%1= 0;第二個變量,自身對齊值為4,指定對齊值為2,所以有效對齊值為2,所以順序存放在0x0002、0x0003、0x0004、0x0005四個連續 字節中,符合0x0002%2=0。第三個變量c的自身對齊值為2,所以有效對齊值為2,順序存放
在0x0006、0x0007中,符合0x0006%2=0。所以從0x0000到0x00007共八字節存放的是C的變量。又C的自身對齊值為4,所以 C的有效對齊值為2。又8%2=0,C只占用0x0000到0x0007的八個字節。所以sizeof(struct C)=8.
五、總結
有 了以上的解釋,相信你對C語言的字節對齊概念應該有了清楚的認識了吧。在網絡程序中,掌握這個概念可是很重要的喔,在不同平台之間(比如在Windows 和Linux之間)傳遞2進制流(比如結構體),那麼在這兩個平台間必須要定義相同的對齊方式,還要注意字節大端和小端的問題,否則會莫名其妙地出現一些詭異的錯誤,可是很難排查的哦^_^。
六、附源代碼
[cpp] view plaincopyprint?
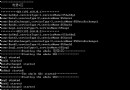
/****************************************************************************** Copyright by Javacode007, All rights reserved! Filename : structsize.c Author : Javacode007 Date : 2012-8-5 Version : 1.0 Description : 結構體類型大小測試 ******************************************************************************/ #includestruct A { char c; short s; int i; }; #pragma pack(1) /*指定按1字節對齊*/ struct PA { char c; short s; int i; }; #pragma pack() /*取消指定對齊,恢復缺省對齊*/ struct B { char c; int i; short s; }; #pragma pack(2) /*指定按2字節對齊*/ struct PB { char c; int i; short s; }; #pragma pack() /*取消指定對齊,恢復缺省對齊*/ int main() { struct A stA; struct PA stPA; struct B stB; struct PB stPB; printf("sizeof(A) = %d, &c = %p, &s = %p, &i = %p\r\n", sizeof(stA), &stA.c, &stA.s, &stA.i); printf("sizeof(PA) = %d, &c = %p, &s = %p, &i = %p\r\n", sizeof(stPA), &stPA.c, &stPA.s, &stPA.i); printf("sizeof(B) = %d, &c = %p, &s = %p, &i = %p\r\n", sizeof(stB), &stB.c, &stB.s, &stB.i); printf("sizeof(PB) = %d, &c = %p, &s = %p, &i = %p\r\n", sizeof(stPB), &stPB.c, &stPB.s, &stPB.i); return 0; }
輸出結果: