C語言中兩個標准IO fputs和fgets都是針對行來進行數據的讀取的!這裡關於這兩個IO函數我有幾個小細節想在這裡和大家分享一下,希望能夠對大家產生幫助!
首先貼上這兩個函數的函數聲明,下面以這兩個函數聲明為基礎進行討論:

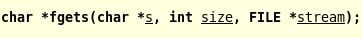
我用於調試的代碼如下:
1 /* 本程序的輸入為nihaoa,然後通過gdb調試來查看fputs的緩沖區內的內容
2 */
3 #include<stdio.h>
4 #include<string.h>
5 #include<stdlib.h>
6 #include<errno.h>
7
8 #define MAXLINE 4
9
10 int main(int argc,char *argv[])
11 {
12 char buffer[MAXLINE];
13 memset(buffer,1,MAXLINE);
14 char buffer_o[BUFSIZ];
15 memset(buffer_o,1,BUFSIZ);
16
17 setbuf(stdout,buffer_o);
18
19 while(NULL != fgets(buffer,MAXLINE,stdin))
20 {
21 if(EOF == fputs(buffer,stdout))
22 {
23 printf("[fputs]: %s",strerror(errno));
24 exit(EXIT_FAILURE);
25 }
26 }
27
28 if(ferror(stdin)) //檢查上面循環停止是否是因為出錯
29 {
30 printf("[fgets]: %s",strerror(errno));
31 exit(EXIT_FAILURE);
32 }
33
34 buffer_o[6] = 'k';
35 buffer_o[7] = 'j';
36 /* 這裡我把fputs的緩沖區的內容調整了一下,最後一個換行字符變成了k,換行字符的後一個變成了j,但是fputs輸
37 * 出的時候還是輸出了到k的內容,後面那個j並沒有輸出。所以fputs輸出的時候並不是根據字符的最後一個'\0'來確
38 * 定的,而是在這個程序內有個計數器,來計量一共輸入了多少個字符,然後再來輸出的。
39 */
40
41 return 0;
42 }
首先說第一個問題,fgets每回從其緩沖區內讀的數據的長度為SIZE-1個字節,然後它會自動在字符串末尾添加一個'\0'符號!而fgets將字符串存入其緩沖區的時候,會自動忽略末尾的'\0'符號!如下圖所示:
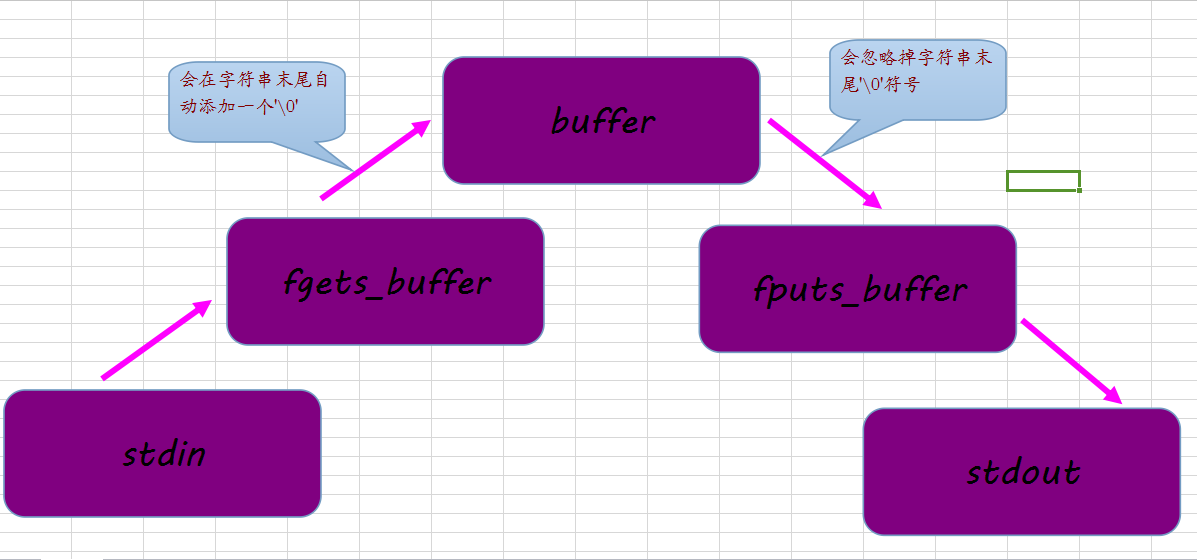
就比如上面的那個程序!字符數組buffer用來充當這個程序的緩沖區!而那個buffer_o我通過setbuf函數來讓它變成了標准輸出的緩沖區!為了便於區分,我把這兩個數組的數據初始化全部設置為1.
舉個例子,比如我在上面那個程序的19行和21行設置兩個個斷點!然後運行查看buffer的內存!
首先是第19行的,此時buffer的內存全部都是1:
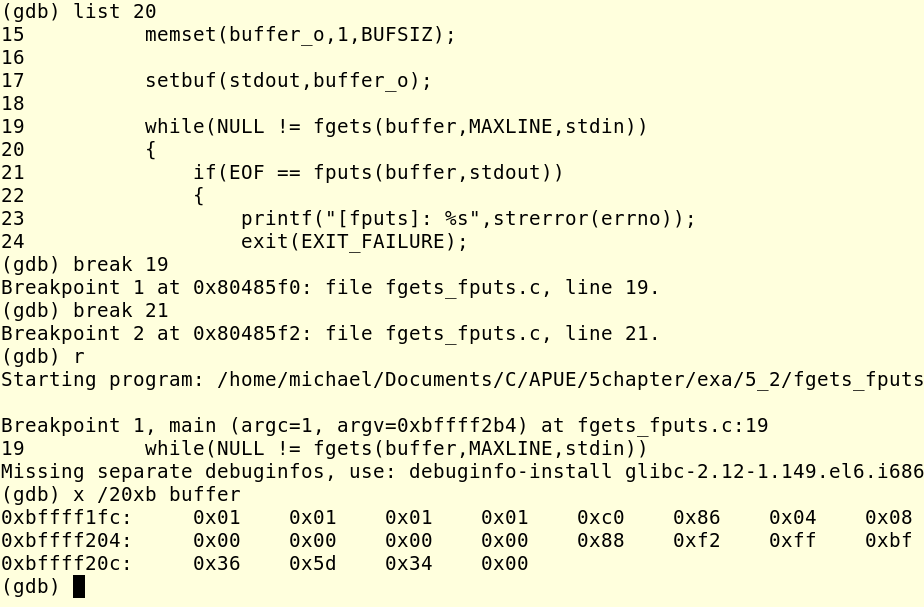
然後運行一句,我輸入的數據是nihaoa<CR>,由於buffer的內容不夠大,所有它只會讀size-1也就是3個字節的內容,最後一個字節填充為0,如下圖所示:

上面這個就說明了關於fgets的內容,它只從它的緩沖區中讀取size-1個字節,然後在字符串的尾部加上一個0;
接下來我們接著調試,繼續來向下運行一步,其結果如下圖所示:

這裡這個buffer_o是stdout的緩沖區,此時它裡面只有3個字節的內容,這正好說明了關於fputs的部分,從目標內存中讀取字符串,並且忽略掉字符串尾部的'\0'。
接著我們再來說第二個問題,那就是fputs程序內部應該有一個計數器,用來統計stdout的緩沖區中一共有多少個字符,fputs輸出的時候就是根據這個計數器來輸出!我們還是以上面那段代碼為例,這回我們在34行和40行設置一個斷點。再來看buffer_o這片內存中的內容!如下圖所示:
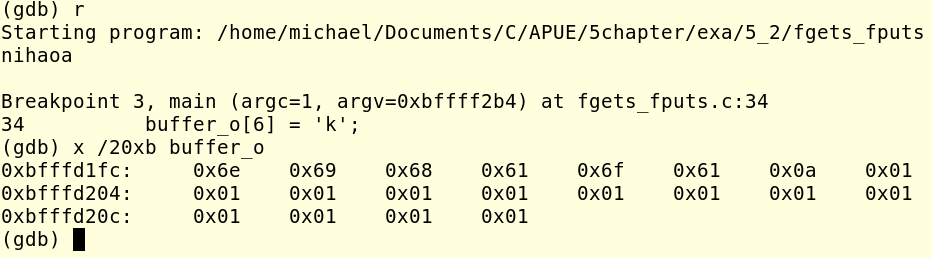
這回我的輸入還是nihaoa<CR>,這回stdout的緩沖區中放的內容就是nihaoa<CR>的ASCII碼了!然後我把那個回車和回車的下一個的ASCII碼改一下,如下圖所示:

回車字符變成了k,它的下一個變成了j。然後我們再來查看輸出的結果!
由於gdb自動添加了一個換行符,所以我就以普通方式運行查看了!如下圖所示:

最後的輸入是nihaoak,並沒有多,這裡就說明fgets的輸出是根據它的那個計數器來的!