C語言標准庫之setjmp
協程的介紹
協程(coroutine),意思就是“協作的例程”(co-operative routines),最早由Melvin Conway在1963年提出並實現。跟主流程序語言中的線程不一樣,線程屬於侵入式組件,線程實現的系統稱之為搶占式多任務系統,而協程實現的多任務系統成為協作式多任務系統。線程由於缺乏yield語義,所以運行過程中不可避免需要調度,休眠掛起,上下文切換等系統開銷,還需要小心使用同步機制保證多線程正常運行。而協程的運行指令系列是固定的,不需要同步機制,協程之間切換也只涉及到控制權的交換,相比較線程來說是非常輕便的。不過同一時刻可以有多個線程運行,但卻只能有一個協程運行。
實際上協程的概念比線程還要早,按照 Knuth 的說法“子例程是協程的特例”,一個子例程就是一次子函數調用,那麼實際上協程就是類函數一樣的程序組件,你可以在一個線程裡面輕松創建數十萬個協程,就像數十萬次函數調用一樣。只不過子例程只有一個調用入口起始點,返回之後就結束了,而協程入口既可以是起始點,又可以從上一個返回點繼續執行,也就是說協程之間可以通過 yield 方式轉移執行權,對稱(symmetric)、平級地調用對方,而不是像例程那樣上下級調用關系。當然 Knuth 的“特例”指的是協程也可以模擬例程那樣實現上下級調用關系,這就叫非對稱協程(asymmetric coroutines)。
setjmp.h
setjmp/longjmp 其實是C語言標准庫中的內容,它被定義在<setjmp.h>頭文件中,我認識的相當部分的人包括寫過很多年C/C++的都表示沒聽過,並且他們在了解了一些setjmp的特性和功能之後還不以為然,說我又不會用到它;然而你們想過為什麼標准庫中會去實現一個相對這麼怪異特性的語法支持?原因很簡單,就是為了實現協程(coroutine),如果你一開始就給自己定位成協程的使用者,不關心它具體怎麼實現的,甚至給自己定位成從不用協程,後面的內容你放心可以直接略過。
我們首先來看 setjmp/longjmp 這兩個函數的定義。
int setjmp( jmp_buf _Buf );
void longjmp( jmp_buf _Buf, int _Value);
使用注意事項:
1、setjmp與longjmp結合使用時,它們必須有嚴格的先後執行順序,也即先調用setjmp函數,之後再調用longjmp函數,以恢復到先前被保存的“程序執行點”。否則,如果在setjmp調用之前,執行longjmp函數,將導致程序的執行流變的不可預測,很容易導致程序崩潰而退出
2、longjmp必須在setjmp調用之後,而且longjmp必須在setjmp的作用域之內。具體來說,在一個函數中使用setjmp來初始化一個全局標號,然後只要該函數未曾返回,那麼在其它任何地方都可以通過longjmp調用來跳轉到 setjmp的下一條語句執行。實際上setjmp函數將發生調用處的局部環境保存在了一個jmp_buf的結構當中,只要主調函數中對應的內存未曾釋放 (函數返回時局部內存就失效了),那麼在調用longjmp的時候就可以根據已保存的jmp_buf參數恢復到setjmp的地方執行。
說白一點就是:在使用 setjmp 時,最常見的一個錯誤用法就是對它做封裝,不應該封裝在一個函數中。比如:
復制代碼
int try(breakpoint bp)
{
return setjmp(bp->jb);
}
void throw(breakpoint bp)
{
longjmp(bp->jb,1);
}
復制代碼
這樣寫並不會引起編譯錯誤,但是極易容易發生運行時錯誤,因為setjmp的棧是在try函數中,而下一次調用longjmp的時候try函數可能已經不在棧中被清除了。
來個簡單的例子:
復制代碼
#include <stdio.h>
#include <setjmp.h>
jmp_buf buf;
void second()
{
printf("second\n");
longjmp(buf, 1);
}
void first()
{
second();
printf("first\n");
}
int coro_main()
{
if ( !(setjmp(buf)) )
{
first();
}
else
{
printf("main\n");
}
return 0;
}
復制代碼
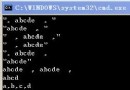
輸出結果:
second
main
除此之外還有廣為使用的C語言協程非標准庫有 ucontext,據我所知ucontext應用更廣泛一些,網上絕大多數 C 協程庫也是基於 ucontext 組件實現的。有空下次再去研究研究它。。。