摘要:本篇主要介紹在靜態鏈接中多個文件合並、地址確定、符號解析和重定位相關問題,以GCC編譯器為例。
首先,鏈接器鏈接多個文件時,采用何種方式合並為一個文件?方式一,按序疊加,即多個文件依次疊加起來;方式二,相似段合並。采用何種方式就要看哪種方式利大於弊。 方式一:這種方式實現簡單,鏈接速度快,基本不需要太多操作。但是,通常簡單的東西往往是粗暴的。我們知道gcc編譯後得到的可重定位目標文件是由各種段(section)組成的,這樣簡單疊加會產生大量零散的段,項目越大這樣的段越多,而且還是大量相同名稱的段。並且由於每個段都有地址和空間的對齊要求,這樣做勢必會浪費大量的內存空間(內部碎片)。所以這種方案並不好,可謂小甜頭換大痛苦。1 int shared = 1;
2 void swap(int* a, int* b)
3 {
4 *a ^= *b ^= *a ^= *b;
5 }
代碼a.c
1 extern int shared;
2 int main(int argc, char** argv)
3 {
4 int a = 100;
5 swap(&a, &shared);
6 return 0;
7 }
8 ~
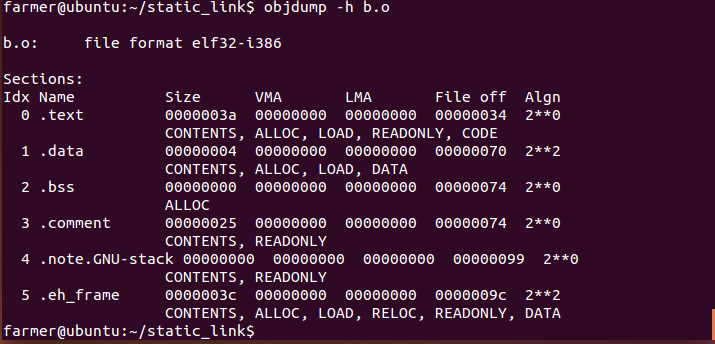
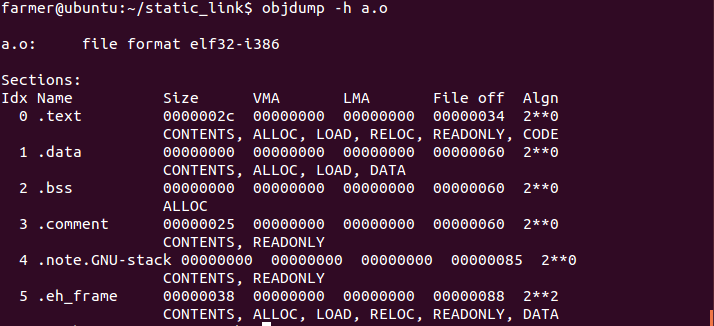
編譯後輸出a.o,b.o,cc -c a.c b.c,使用objdump查看a.o、b.o如下:


 連接a.o b.o,的到可執行文件ab
連接a.o b.o,的到可執行文件ab
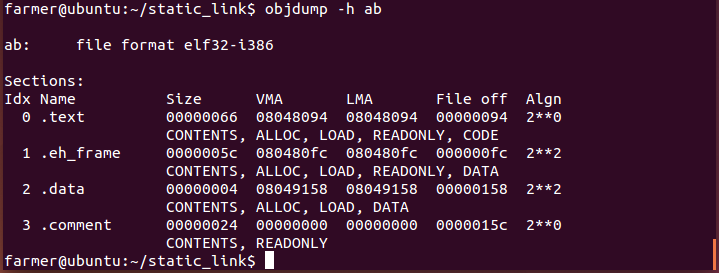
可以看到a.o和b.o他們的起始地址都為0,而可執行文件ab的起始地址則是從0x0804000起(.text段之前還有文件頭)。
重點和難點在於符號解析和重定位,即要更新文件合並後的總全局符號表,在構建全局符號表時即完成符號解析,重定位需要在符號解析後完成。在目標文件的結構中有一種section叫重定位表,各個段中如果有需要重定位的符號那麼就會有相應的重定位表,如.text的重定位表是.rel.text。由於在a.c代碼中用到了shared和swap這兩個符號都屬於b.c文件中的定義,鏈接時需要重定位,所以a.o中的的text段就會有相應的重定位表。同樣用objdump可以查看目標文件的重定位表內容: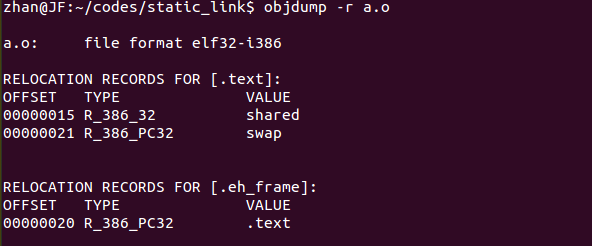

我們可以看到有兩行是關於需要重定位符號shared和swap的描述,其中OFFSET表示它們在a.o文件中的偏移值,TYPE表示重定位時對指令的修正方式,下面是書中對其解釋的相應的圖表:


上面提到的r_offset和r_info是重定位表的結構中的變量,摘取書中的解釋:


所以我的理解是A就是還未重定位時,符號shared和swap的地址,P即是在可執行文件ab中需要修改處的偏移值,而S是b.o和a.o合並後符號shared和swap的實際地址。具體該怎麼算繼續往下面看。
我們將a.o進行反匯編得到:
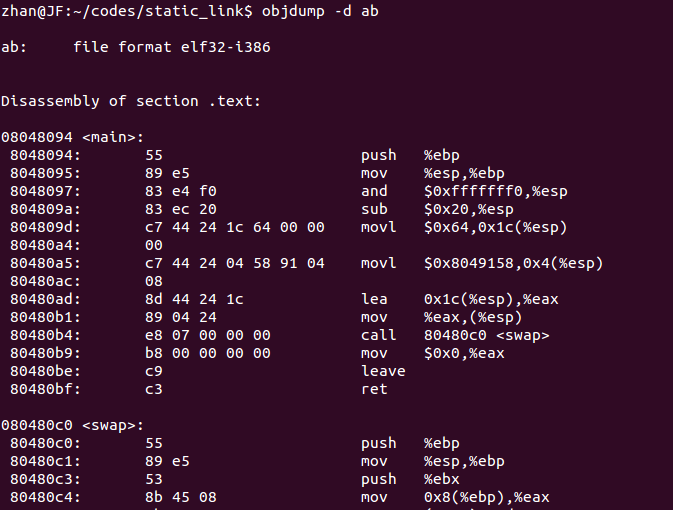

那麼怎樣找到代碼a.c中對shared和swap的使用是上圖哪兩條指令呢?因為shared和swap是在b.c中定義的,在鏈接時a.o中對符號shared和swap必然要重定位,因此a.o中需要重定位的位置即是使用這兩個符號的位置,所以由上面text段的重定位表中信息可知在偏移量為11和20處的兩條指令即是使用它們地方(因為需要重定位的偏移量剛好在這兩條指令中間)。
我們來分析這兩條指令,寄存器esp是專門用來作為棧頂指針使用的,所以mov $0x0, 0x4(%esp)是把0儲存在偏移棧頂4個字節的位置,那這個0值又是什麼呢?當然不是shared值啦,shared值是已知的只是不知道它存儲在什麼地方,為什麼不知道它在什麼地方呢?是因為在鏈接之前還沒有對它重定位,所以這個0值應該是未重定位之前shared地址的默認值(這裡這樣解釋只是我自認為的一種通俗表達,我的另一種理解是在編譯層面和語言層面shared是不同的東西,在語言層面shared是一個變量,對它的操作是直接對它所在內存區域的操作,而在編譯層面shared是內存中某塊地址空間的引用,所以在符號表中shared的值是那塊內存的地址,因此0值就是shared的值)。這個0又是怎麼來的,注意上圖是反匯編,所以匯編代碼是由機器指令反編譯得到的,偏移量11處的機器指令是0xc7 44 24 04 00 00 00 00,前4個字節是指令碼,後四個字節是符號shared對應的值,即0。另外一條指令call 21 <...>,在匯編(其他語言也是)中函數名就是函數在內存中的起始地址,所以假設21就是swap的起始地址,那麼call 21和call swap是等價的,現在是swap不在代碼a.c中定義,這樣的話就不能使用call swap了,而是給swap起始地址一個默認值(21),使用call 21。這個21又是怎樣得到的呢?看與這條指令對應的機器指令,e8 fc ff ff ff(5個字節長度),書中對這條機器指令的解釋是:0xe8是操作碼,在Intel的IA-32體系中表示這是一條近址相對位移調用指令,操作碼後面的四個字節就是被調用函數的相對於調用指令的下一條指令的偏移量,在沒有重定位前默認為0xfc ff ff ff(小端字節表示法,代表-4的補碼),所以21是(25-4)得來的,這是個假地址。
現在再對鏈接a.o b.o 輸出的可執行文件ab進行反匯編。

由重定位表的偏移量計算可知,現在關於符號shared和swap的使用指令對應上圖的偏移量為80480a5和80480b4兩條指令。上圖我們看到的結果是重定位後的,重定位時我們要修改的值是偏移量80480a5處的後四個字節和偏移量804800b4處後四個字節。根據上文提到的公式S+A和S+A-P,就可以算出重定位後的值。
首先看符號shared重定位後的值怎麼算。先查看可執行文件ab得到合並後變量shared的地址,如圖
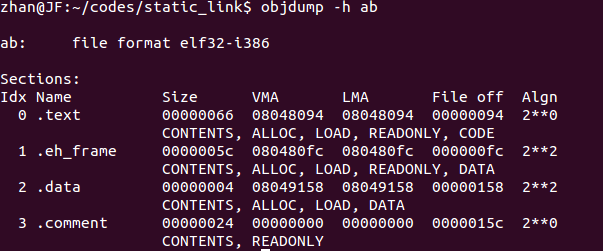

上圖數據段在虛擬地址空間中起始地址是0x08049158,因為這個可執行文件中data段中就只有一個數據變量所以這個地址也是shared的地址,即S=0x08049158,重定位前地址是0x0,即A=0x0,所以S+A=0x08049158,在內存中以小端表示法存儲時即為58 91 04 08。你可能會問如果不只一個全局變量時,我又怎麼知道他們合並後的地址,注意合並後的地址都在符號解析後的全局符號表中,鏈接器是知道的。
再看swap重定位後的值怎麼算,在上面對可執行文件ab反匯編時我們看到函數swap的入口地址為0x080480c0,即S=0x080480c0,重定位前call匯編代碼對應的機器指令後四個字節的值是ff ff ff fc(-4),即A=-4,P是被修正的位置,為0x080480b5,由公式S+A-P(c0-4-b5=7)得重定位後修改為07 00 00 00(小端表示法)。
以上是我在看《程序員的自我修養--鏈接、裝載與庫》一書中第四章前2節的個人理解,限於個人水平問題,有些地方的理解可能有偏差,歡迎指正。
靜態、共享和動態庫
C語言中有一些函數不需要進行編譯,有一些函數也可以在多個文件中使用。一般來說,這些函數都會執行一些標准任務,如數據庫輸入/輸出操作或屏幕控制等。可以事先對這些函數進行編譯,然後將它們放置在一些特殊的目標代碼文件中,這些目標代碼文件就稱為庫。庫文件中的函數可以通過連接程序與應用程序進行連接。這樣就不必在每次開發程序時都對這些通用的函數進行編譯了。
庫可以有三種使用的形式:靜態、共享和動態。靜態庫的代碼在編譯時就已連接到開發人員開發的應用程序中,而共享庫只是在程序開始運行時才載入,在編譯時,只是簡單地指定需要使用的庫函數。動態庫則是共享庫的另一種變化形式。動態庫也是在程序運行時載入,但與共享庫不同的是,使用的庫函數不是在程序運行開始,而是在程序中的語句需要使用該函數時才載入。動態庫可以在程序運行期間釋放動態庫所占用的內存,騰出空間供其它程序使用。由於共享庫和動態庫並沒有在程序中包括庫函數的內容,只是包含了對庫函數的引用,因此代碼的規模比較小。
1, 靜態庫可以認為是一些目標代碼的集合。按照習慣,一般以".a"做為文件後綴名。使用ar(archiver)命令可以創建靜態庫。因為共享庫有著更大的優勢,靜態庫已經不被經常使用。但靜態庫使用簡單,仍有使用的余地,並會一直存在。
靜態庫在應用程序生成時,可以不必再編譯,節省再編譯時間。但在編譯器越來越快的今天,這一點似乎已不重要。如果其他開發人員要使用你的代碼,而你又不想給其源碼,提供靜態庫是一種選擇。從理論上講,應用程序使用了靜態庫,要比使用動態加載庫速度快1-5%,但由於莫名的原因,實際上可能並非如此。由此看來,除了使用方便外,靜態庫可能並非一種好的選擇。
2,共享庫
共享庫是在程序啟動時被裝載。當一個應用程序裝載了一個共享庫後,其它應用程序仍可以裝載同一個共享庫。基於linux的使用方法,共享庫還有其它靈活的而又精妙的特性:
更新庫並不影響應用程序使用舊的,非向後兼容的版本;在執行特定程序時,可以覆蓋整個庫或更新庫中的特定函數;以上操作不會影響已經運行的程序,他們仍會使用已經裝載的庫。
編譯成靜態庫就行了 和調用其他代碼有什麼關系 其他代碼不論是動態鏈接或者靜態鏈接都可以