我們先通過下圖,來了解可以跨平台使用的整數類型:
之所以我們需要以上各種明確指定寬度的int類型是因為int類型本身比較特殊,其具體的字節數同機器字長和編譯器有關(標准並沒有規定其具體所占的字節數)。
因此如果要保證移植性,我們應該盡量使用上圖中帶寬度的int類型。這種數據類型在所有平台下都分配相同的字節,因此在移植上不存在問題。
我們以整數類型int64_t為例來說明。我們都知道,int64_t用來表示64位整數,在32位系統中是long long int,在64位系統中是long int,所以打印int64_t的格式化方法如下:
printf("%ld" , value); // 64bit OS
printf("%lld", value); // 32bit OS
那麼這樣在32位系統和64位系統中,編譯相同的代碼,就有可能會出錯。跨平台的方法是使用PRId64來格式化輸出,如下:
#ifndef __STDC_FORMAT_MACROS
#define __STDC_FORMAT_MACROS
#endif
#include <inttypes.h>
printf("%" PRId64 "\n", value);
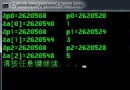
具體可以參看下圖:
注意:上述宏定義針對C語言,如果C++需要使用PRId64等宏,需要定義一個__STDC_FORMAT_MACROS宏顯示打開它。具體可以參見/usr/include/inttypes.h中宏__STDC_FORMAT_MACROS的定義,如下:
/* The ISO C99 standard specifies that these macros must only be defined if explicitly requested. */ #if !defined __cplusplus || defined __STDC_FORMAT_MACROS # if __WORDSIZE == 64 # define __PRI64_PREFIX "l" # define __PRIPTR_PREFIX "l" # else # define __PRI64_PREFIX "ll" # define __PRIPTR_PREFIX # endif /* Macros for printing format specifiers. */ /* Decimal notation. */ # define PRId8 "d" # define PRId16 "d" # define PRId32 "d" # define PRId64 __PRI64_PREFIX "d"
MUDUO開源庫中也使用了上文所提到的方式,源碼如下:
#include <muduo/base/Timestamp.h>
#include <sys/time.h>
#include <stdio.h>
#ifndef __STDC_FORMAT_MACROS
#define __STDC_FORMAT_MACROS
#endif
#include <inttypes.h>
#include <boost/static_assert.hpp>
using namespace muduo;
BOOST_STATIC_ASSERT(sizeof(Timestamp) == sizeof(int64_t));
Timestamp::Timestamp(int64_t microseconds)
: microSecondsSinceEpoch_(microseconds)
{
}
string Timestamp::toString() const
{
char buf[32] = {0};
int64_t seconds = microSecondsSinceEpoch_ / kMicroSecondsPerSecond;
int64_t microseconds = microSecondsSinceEpoch_ % kMicroSecondsPerSecond;
snprintf(buf, sizeof(buf)-1, "%" PRId64 ".%06" PRId64 "", seconds, microseconds);
return buf;
}
string Timestamp::toFormattedString(bool showMicroseconds) const
{
char buf[32] = {0};
time_t seconds = static_cast<time_t>(microSecondsSinceEpoch_ / kMicroSecondsPerSecond);
struct tm tm_time;
gmtime_r(&seconds, &tm_time);
if (showMicroseconds)
{
int microseconds = static_cast<int>(microSecondsSinceEpoch_ % kMicroSecondsPerSecond);
snprintf(buf, sizeof(buf), "%4d%02d%02d %02d:%02d:%02d.%06d",
tm_time.tm_year + 1900, tm_time.tm_mon + 1, tm_time.tm_mday,
tm_time.tm_hour, tm_time.tm_min, tm_time.tm_sec,
microseconds);
}
else
{
snprintf(buf, sizeof(buf), "%4d%02d%02d %02d:%02d:%02d",
tm_time.tm_year + 1900, tm_time.tm_mon + 1, tm_time.tm_mday,
tm_time.tm_hour, tm_time.tm_min, tm_time.tm_sec);
}
return buf;
}
Timestamp Timestamp::now()
{
struct timeval tv;
gettimeofday(&tv, NULL);
int64_t seconds = tv.tv_sec;
return Timestamp(seconds * kMicroSecondsPerSecond + tv.tv_usec);
}
Timestamp Timestamp::invalid()
{
return Timestamp();
}
對於支持C++11標准的編譯器,不用添加宏__STDC_FORMAT_MACROS,也可以直接編譯通過。
1. http://www.cplusplus.com/reference/cinttypes/?kw=inttypes.h
2. http://www.cprogramdevelop.com/4787258/
3. https://github.com/chenshuo/muduo/blob/master/muduo/base/Timestamp.cc
c語言能跨平台是因為各個平台有相應的c編譯器,只要源代碼相同,編譯器編譯出來的二進制文件就會實現相同的功能,但是這些二進制文件本身是不一樣的
exe就是2進制的,但不完全是原來程序的代碼,還包括了windows系統的一些代碼
科普一下,C最早是出現在Unix下的,Windows那都是後話了,C出現的時候Windows還沒開發出來呢。
C有個比較特別的稱呼,叫中級語言,因為它有高級語言的特性又能跟底層硬件很好的交互所以才有這麼個說法。DOS時代在C裡面嵌上一段匯編直接從並口讀個數上來那是很流行的,現在沒見誰在VC裡面這麼干吧。Windows也不讓啊。想訪問硬件怎麼也得通過驅動。
說遠了,C在多種平台下可以實現代碼級的共享,跨平台就需要重新編譯了。
但是,我也見過有的軟件是可以在多種平台上運行了,可能有什麼特別的技術,可以先識別一下操作系統,再運行相應的代碼。這個應該是在編譯的時候有特殊的技巧。
C編譯、連接器網上有現成的代碼,一般不是很專業的技術人員沒有去研究它。我一直把玩編譯原理的視為天人,有能力把編譯原理那本書看完的就很不容易了,再要能領會其中精要那就成才了,能把龍書虎書鯨書都搞明白的那就是一流專家了。
1. 對於C/C++來說VS和GCC編譯出的東西不可以跨平台(.Net平台除外), 首先你要明白,要實現跨平台除了你的程序代碼要考慮兼容性以外,最主要的是你的代碼要在什麼平台下面運行。在不同的平台下面有不同的編譯器,比如,windows平台下面可以用VC進行編譯,在linux下面可以用gcc/g++進行編譯,在嵌入式平台下面還需要針對不同的CPU類型采用相應的編譯器。因此,編譯器的作用就是把你寫的代碼翻譯成CPU可以識別的代碼。
2.單純從編程的角度考慮的話,標准的代碼都是跨平台的,只是如果要編譯+運行,這就需要不同平台下面的編譯器了
3.像JAVA .Net這種中跨平台的實現,可以做到一次編譯處處運行,但是C/C++只能做到一次編寫處處編譯後才能處處運行
4.GNU下面的庫都是免費的 www.gnu.org/software/
5.對於PKCS,本人沒用過,如果該標准標明其支持跨平台,那它所信賴的庫應該是C/C++標准庫了,win/unix兩個平台下的編譯器對標准庫都是支持的,所以應該可以實現一次編寫處處編譯