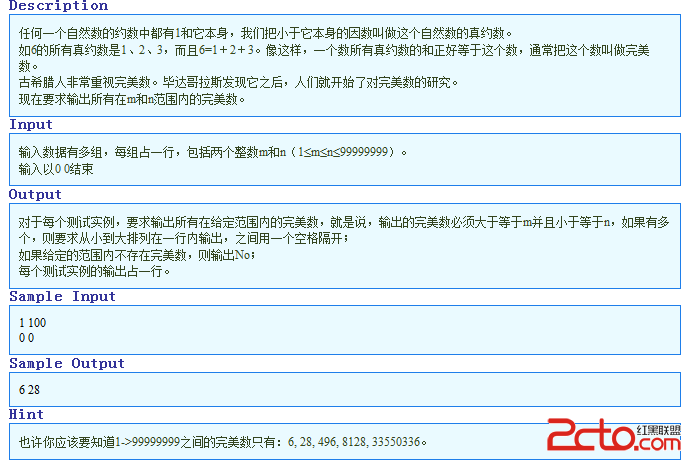
下面的六個程序片段主要完成這些事情:
下面的所有程序都可以在GCC下編譯通過,只有最後一個需要動用C++的編譯器g++才能編程通過。
hello1.c
1 2 3 4 5 6 7 8 9 10 11 #define _________ }
#define ________putchar
#define _______ main
#define _(a) ________(a);
#define ______ _______(){
#define __ ______ _(0x48)_(0x65)_(0x6C)_(0x6C)
#define ___ _(0x6F)_(0x2C)_(0x20)_(0x77)_(0x6F)
#define ____ _(0x72)_(0x6C)_(0x64)_(0x21)
#define _____ __ ___ ____ _________
#include
_____
hello2.c
1 2 3 4 5 6 7 8 9 #include
main(){
intx=0,y[14],*z=&y;*(z++)=0x48;*(z++)=y[x++]+0x1D;
*(z++)=y[x++]+0x07;*(z++)=y[x++]+0x00;*(z++)=y[x++]+0x03;
*(z++)=y[x++]-0x43;*(z++)=y[x++]-0x0C;*(z++)=y[x++]+0x57;
*(z++)=y[x++]-0x08;*(z++)=y[x++]+0x03;*(z++)=y[x++]-0x06;
*(z++)=y[x++]-0x08;*(z++)=y[x++]-0x43;*(z++)=y[x]-0x21;
x=*(--z);while(y[x]!=NULL)putchar(y[x++]);
}
hello3.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include
#define __(a)goto
a;
#define ___(a)putchar(a);
#define _(a,b) ___(a) __(b);
main()
{ _:__(t)a:_('r',g)b:_('$',p)
c:_('l',f)d:_('
',s)e:_('a',s)
f:_('o',q)g:_('l',h)h:_('d',n)
i:_('e',w)j:_('e',x)k:_('\n',z)
l:_('H',l)m:_('X',i)n:_('!',k)
o:_('z',q)p:_('q',b)q:_(',',d)
r:_('i',l)s:_('w',v)t:_('H',j)
u:_('a',a)v:_('o',a)w:_(')',k)
x:_('l',c)y:_('\t',g)z:___(0x0)}
hello4.c
1 2 3 4 5 6 7 8 9 intn[]={0x48,
0x65,0x6C,0x6C,
0x6F,0x2C,0x20,
0x77,0x6F,0x72,
0x6C,0x64,0x21,
0x0A,0x00},*m=n;
main(n){putchar
(*m)!='\0'?main
(m++):exit(n++);}
hello5.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 main(){inti,n[]={(((1<<1)<<(1<<1)<<(1<<
1)<<(1<<(1>>1)))+((1<<1)<<(1<<1))), (((1
<<1)<<(1<<1)<<(1<<1)<<(1<<1))-((1<<1)<<(
1<<1)<<(1<<1))+((1<<1)<<(1<<(1>>1)))+ (1
<<(1>>1))),(((1<<1)<<(1<<1)<<(1<<1)<< (1
<<1))-((1<<1)<<(1<<1)<<(1<<(1>>1)))- ((1
<<1)<<(1<<(1>>1)))),(((1<<1)<<(1<<1)<<(1
<<1)<<(1<<1))-((1<<1)<<(1<<1)<<(1<<(1>>1
)))-((1<<1)<<(1<<(1>>1)))),(((1<<1)<< (1
<<1)<<(1<<1)<<(1<<1))-((1<<1)<<(1<<1)<<(
1<<(1>>1)))-(1<<(1>>1))),(((1<<1)<<(1<<1
)<<(1<<1))+((1<<1)<<(1<<1)<<(1<<(1>>1)))
-((1<<1)<<(1<<(1>>1)))),((1<<1)<< (1<<1)
<<(1<<1)),(((1<<1)<<(1<<1)<<(1<<1)<<(1<<
1))-((1<<1)<<(1<<1))-(1<<(1>>1))),(((1<<
1)<<(1<<1)<<(1<<1)<<(1<<1))-((1<<1)<< (1
<<1)<<(1<<(1>>1)))-(1<<(1>>1))), (((1<<1
)<<(1<<1)<<(1<<1)<<(1<<1))- ((1<<1)<< (1
<<1)<<(1<<(1>>1)))+(1<<1)), (((1<<1)<< (
1<<1)<<(1<<1)<< (1<<1))-((1<<1)<< (1<<1)
<<(1<<(1>>1)))-((1<<1) <<(1<< (1>>1)))),
(((1<<1)<< (1<<1)<<(1<<1)<< (1<<1))- ((1
<<1)<<(1<<1)<<(1<<1))+((1<<1)<< (1<<(1>>
1)))), (((1<<1)<<(1<<1) <<(1<<1))+(1<<(1
>>1))),(((1<<1)<<(1<<1))+((1<<1)<< (1<<(
1>>1))) + (1<< (1>>1)))};for(i=(1>>1);i
<(((1<<1) <<(1<<1))+((1 <<1)<< (1<<(1>>1
))) + (1<<1)); i++)printf("%c",n[i]);
}
hello6.cpp
下面的程序只能由C++的編譯器編譯(比如:g++)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include
#define _(_)putchar(_);
intmain(void){inti
= 0;_(
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++i)_(++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++i)_(++++++++++++++
i)_(--++i)_(++++++i)_(------
----------------------------
----------------------------
----------------------------
----------------------------
----------------i)_(--------
----------------i)_(++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++i)
_(----------------i)_(++++++
i)_(------------i)_(--------
--------i)_(----------------
----------------------------
----------------------------
----------------------------
----------------------------
------i)_(------------------
----------------------------
i)returni;}
這個世界從來都不會缺少另類的東西,人類自然世界如此,計算機世界也一樣。編程語言方面,看過本站《6個變態的C語言Hello World程序》的朋友們一定對BT和另類不會陌生,但那都是些小兒科,真正的BT和另類要是從語言級上來完成。讓我們來看看其中一個比較另類的語言BrainFuck。看到這個程序語言的名字,請不要以為這是一個搞笑的語言,這是一個“嚴肅事情”,請大家用“最虔誠的態度”來閱讀本文。
Brainfuck,是一種極小化的計算機語言,它是由Urban Müller在1993年創建的。由於“綠王八”的原因,這種語言有時被稱為brainf**k或brainf***,甚至被簡稱為BF。這種 語言,是一種按照“Turing complete(完整圖靈機)”思想設計的語言,它的主要設計思路是:用最小的概念實現一種“簡單”的語言,BrainF**k 語言只有八種符號,所有的操作都由這八種符號的組合來完成。
BF基於一個簡單的機器模型,除了八個指令,這個機器還包括:一個以字節為單位、被初始化為零的數組、一個指向該數組的指針(初始時指向數組的第一個字節)、以及用於輸入輸出的兩個字節流。
下面是這八種指令的描述,其中每個指令由一個字符標識:
>
指針加一
<
指針減一
+
指針指向的字節的值加一
-
指針指向的字節的值減一
.
輸出指針指向的單元內容(ASCII碼)
,
輸入內容到指針指向的單元(ASCII碼)
[
如果指針指向的單元值為零,向後跳轉到對應的]指令的次一指令處
]
如果指針指向的單元值不為零,向前跳轉到對應的[指令的次一指令處
(按照更節省時間的簡單說法,]也可以說成“向後跳轉到對應的[狀態”。這兩解釋是一樣的。)
(第三種同價的說法,[意思是"向前跳轉到對應的]“,]意思是”向後跳轉到對應的[指令的次一指令處,如果指針指向的字節非零。")
Brainfuck程序可以用下面的替換方法翻譯成C語言(假設ptr是char*類型):
>
++ptr;
<
--ptr;
+
++*ptr;
-
--*ptr;
.
putchar(*ptr);
,
*ptr =getchar();
[
while (*ptr) {
]
}
因為 BrainFuck 只有八種指令,並且沒有關鍵字,也不允許自定義標識符,因此它的編譯器實現起來非常簡單,初學 C 語言不久的人都可以自己編出來,盡管在座的各位每人都可以自己編一個,不過為了引起大家的興趣,我這裡還是給出大家一個官方發布的版本。這個程序只有短短 50 多行,並且完全由 ANSI C 寫成,因此你隨便找個 C 語言編譯器,把它編譯一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58#include ;
int
p, r, q;
char
a[5000], f[5000], b, o, *s=f;
void
interpret(char
*c)
{
char
*d;
r++;
while( *c ) {
//if(strchr("<>;+-,.[]\n",*c))printf("%c",*c);
switch(o=1,*c++) {
case
'<': p--;
break;
case
'>;': p++;
break;
case
'+': a[p]++;
break;
case
'-': a[p]--;
break;
case
'.':
putchar(a[p]);
fflush(stdout);
break;
case
',': a[p]=getchar();fflush(stdout);
break;
case
'[':
for( b=1,d=c; b && *c; c++ )
b+=*c=='[', b-=*c==']';
if(!b) {
c[-1]=0;
while( a[p] )
interpret(d);
c[-1]=']';
break;
}
case
']':
puts("UNBALANCED BRACKETS"),
exit(0);
case
'#':
if(q>;2)
printf("%2d %2d %2d %2d %2d
%2d %2d %2d %2d %2d\n%*s\n",
*a,a[1],a[2],a[3],a[4],a[5],a[6],a[7],a[8],a[9],3*p+2,"^");
break;
default: o=0;
}
if( p<0 || p>;100)
puts("RANGE ERROR"),
exit(0);
}
r--;
// chkabort();
}
main(int
argc,char
*argv[])
{
FILE
*z;
q=argc;
if(z=fopen(argv[1],"r"))
{
while( (b=getc(z))>;0
)
*s++=b;
*s=0;
interpret(f);
}
}
當然,如果你覺得用C語言來實現BrainFuck語言的解釋器是對BrainFuck這種語言的一種侮辱的話,我們的BrainFuck社區是絕對不能容忍你有這種想法的。因為我們有一個使用100%純brainfuck寫成的一個編譯器awib:http://code.google.com/p/awib/
++++++++++[>+++++++>++++++++++>+++>+<<<<-] >++.>+.+++++++..+++.>++.<<+++++++++++++++. >.+++.------.--------.>+.>.
怎麼?看不懂嗎?下面是解釋:
+++ +++ +++ + initialize counter (cell #0) to 10
[ use loop to set the next four cells to 70/100/30/10
> +++ +++ + add 7 to cell #1
> +++ +++ +++ + add 10 to cell #2
> +++ add 3 to cell #3
> + add 1 to cell #4
<<< < - decrement counter (cell #0)
]
>++ . print 'H'
>+. print 'e'
+++ +++ +. print 'l'
. print 'l'
+++ . print 'o'
>++ . print ' '
<<+ +++ +++ +++ +++ ++. print 'W'
>. print 'o'
+++ . print 'r'
--- --- . print 'l'
--- --- --. print 'd'
>+. print '!'
>. print '\n'
相關鏈接:
如果你要覺得BF已經很BT了,那麼你就錯了,下面這些程序語言更BT。
WhiteSpace語言
這是一種只用空白字符(空格,TAB和回車)編程的語言,而其它可見字符統統為注釋。下面是它的一個示例:
什麼?你什麼也沒有看見,這就對了,因為這正是這門語言的獨特之處。訪問下面這個鏈接查看Hello,World示例。記得按Ctrl+A來查看程序。
官網:http://compsoc.dur.ac.uk/whitespace/index.php。
LOLCODE語言
LOLCODE是一種建立在高度縮寫的網絡英語之上的編程語言,一般來說如果一個人能理解這種網絡英語就能在未經訓練的情況下讀懂LOLCODE程序源代碼。下面是其Hello,World例程:
HAI CAN HAS STDIO? VISIBLE "HAI WORLD!" KTHXBYE
翻譯成中文就是:
嗨 我可以用 STDIO 麼? 顯示一下 “HAI WORLD!” 謝謝啊,再見
官網:http://lolcode.com/
中文編程語言
不要以為只有老外才那麼BT,咱們中國也有自己的BT編程語言。
中文Basic
中文指令 對應於的Applesoft BASIC 10 卜=0 10 Y=0 20 入 水, 火 20 INPUT E, F 30 從 日 = 水 到 火 30 FOR A = E TO F 40 卜 = 卜+對數(日) 40 Y = Y + LOG (A) 50 下一 日 50 NEXT A 60 印 卜 60 PRINT Y官網無法訪問了,只能看看Wikipedia了:http://en.wikipedia.org/wiki/Chinese_BASIC
中蟒語言(中文Python)
下面的程序是不是很Cool?
#!/usr/local/bin/cpython
回答 = 讀入('你認為中文程式語言有存在價值嗎 ? (有/沒有)')
如 回答 == '有':
寫 '好吧, 讓我們一起努力!'
不然 回答 == '沒有':
寫 '好吧,中文並沒有作為程式語言的價值.'
否則:
寫 '請認真考慮後再回答.'
官網:http://www.chinesepython.org/
差不多了,該結束了,再次說明,這是一篇很嚴肅的文章。
(全文完)