過去寫iphone程序一直都沒有用過自動解析,都是手動按著字典一層一層的解析,這樣費時費力,還容易出錯。後來公司來了新朋友帶來了自動解析的jastor庫,著實不錯。
jastor是一個基於oc運行時的庫,它可以將字典對象轉換成NSObject對象。它支持NSString, NSNumber,NSArray, NSDictionary以及它們的嵌套類型。例如現在需要將dict轉換為model。 dict為NSDictionary對象, model為繼承於Jastor的NSObject對象。 Jastor通過遍歷model對象的所有屬性, 以屬性作的名字作為dict的key,得到字典的value值。 然後根據value值的類型,進行不同的處理。 如果value是NSArray類型,那麼就進入NSArray的解析流程; 如果value是NSDictionary類型,那麼開始進行遞歸調用,如果是其他普通類型,則直接setvalue:forKey。當進入NSArray的處理流程時候,調用類的“屬性_class”方法獲取到數組對象的類型,然後對數組對象進行逐步解析,數組對象也必須是字典類型。
Jastor確實可以大大簡化代碼的解析流程,當然效率肯定沒有手動解析的效率高,這個可以從代碼的遞歸流程以及使用Runtime的各種遍歷方法中可以看出。 但是作為開發人員,這麼點的效率損失可以帶來大量代碼的簡潔,減少開發人員的出錯幾率,它的益處是顯而易見的。當第一次使用Jastor時候,著實為它的代碼的簡潔所吸引,主要的有遞歸解析思想,rumtime的相關內容, 組合模式,緩存機制。後來加入到代碼中後,總會有一些崩潰的情況,主要是一些容錯性的問題,畢竟我們沒有辦法要求服務器下發的json數據每次都是和我們要求的一直,總有一些不一致的情況引起意想不到的問題。
Jastor本身是一個基類,它可以將字典轉換成model, 如果字典的某一個成員又是字典,那麼它可以遞歸進去繼續解析,直到遇到的是一個普通的單一數據類型例如NSString,NSNumber等等為止,通過這樣層層的遞歸,深入到最裡層後也就是Jastor解析的結束。它通過for循環遍歷當前類的所有屬性,逐一尋找屬性在字典裡面的value值,根據value值的不同類型以及屬性的類型決定下一步進行遞歸解析還是直接setValueForKey。
if ([dictOrArray isKindOfClass:nsDictionaryClass]) {
value = [dictOrArray valueForKey:jsonKey];
if (value == [NSNull null] || value == nil) {
continue;
}
if ([JastorRuntimeHelper isPropertyReadOnly:[self class] propertyName:classAttrName]) {
continue;
}
// handle dictionary
if ([value isKindOfClass:nsDictionaryClass]) {
Class klass = [JastorRuntimeHelper propertyClassForPropertyName:classAttrName ofClass:[self class]];
if (![klass isSubclassOfClass:[Jastor class]]) {
NSLog(@"服務器返回的數據類型和客戶端不一致");
continue;
}
value = [[[klass alloc] initWithDictOrArray:value] autorelease];
}
// handle array
else if ([value isKindOfClass:nsArrayClass]) {
value = [self dealWithArrayValue:value attrName:classAttrName jsonKey:jsonKey];
}
// handle nsnumber
else if([value isKindOfClass:[NSNumber class]]){
value = [(NSNumber *)value stringValue];
}
} // handle all others
if (value) {
[self setValue:value forKey:classAttrName];
}Runtime用的比較好, 其實裡面也就幾個方法而已,不過由於用的比較少,可能感覺它有些高大上了,其實仔細看看,也是普通的屬性遍歷而已。總共就幾個方法: 判斷屬性是否可讀,獲取一個類對象的所有屬性列表數組,判斷指定類對象的給定屬性的類型。所有的方法基於一個基本的思想: 遍歷類對象的所有objc_property_t的屬性進行處理。 這裡面效率肯定比較低,但是這裡面作者用了緩存的思想,無緩沖就遍歷並寫入緩存,下次直接讀緩存。
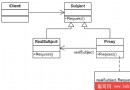
派生類的model繼承於Jastor,派生類model的某一個屬性可能也繼承於Jastor。一個大的model是一堆Jastor的子類的組合, 通過這種類似於組合模式的思想,貫穿到遞歸數據解析中,只是通常的組合模式不是類和屬性的組合,而且集合和單品元素的組合,其實原理的精髓是一樣的。
可以看到裡面有各種緩存,包括獲取屬性列表,是否可讀,獲取指定屬性的類對象,獲取常用類的類對象等等,都進行的緩存操作,只用了幾個簡簡單單的字典,卻可以大大提高程序的執行效率,相當不錯。
Jastor本身已經進行了各種容錯,不過對於應用來說還是有些缺陷的,畢竟程序可以出錯,但不可以崩潰,這是一個基本准則。因此,我主要通過猜,試驗,發現了幾個崩潰點,和同事一起進行了修正,加入了幾個容錯,至少在我們的應用中,並沒有出現崩潰的情況。
新版的Jastor加入了map,屬性名稱可以任意,賦予程序以最大的靈活性。原來我們使用的這一版沒有這種內容,我們組的牛人波波同志加入了map機制,剛開始我感覺必要性不是很大,但是隨著後期的項目的推進,確實用處極大。
對於Jastor,代碼我就不貼了,Github有庫,GitHub地址。 對於Jastor出現崩潰的情況,一定要跟進Jastor裡面,找到問題,加入保護即可。