用C語言產生隨機數重要用到rand函數、srand函數、及宏RAND_MAX(32767),它們均在stdlib.h中進行了聲明。
int rand(void);//生成一個隨機數
voidsrand(unsigned int seed); //為rand設置“種子”的值
srand()就是給rand()提供種子seed,如果srand每次輸入的數值是一樣的,那麼每次運行產生的隨機數也是一樣的。通常的做法是以這樣一句代碼:
srand((unsigned)time(NULL));
來取代,這樣將使得種子為一個不固定的數,這樣產生的隨機數就不會每次執行都一樣了。先看一個例子:
#include
#include
#include
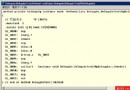
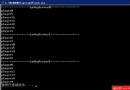
int test_rand()
{
int i;
/* Seed therandom-number generator with current time so that
* thenumbers will be different every time we run.
*/
srand((unsigned)time( NULL ) );
/* Display10 numbers. */
for( i = 0;i < 10; i++ )
printf("%6d\n", rand());
return 0;
}
C的函數庫之所以沒有把使用系統時鐘初始化隨機種子這步重要的操作直接放進rand函數的實現中,可能有如下原因:
1.可以高效產生連續的隨機數,不用每次都初始化;
2.給程序員以更高的靈活性,因為可能在要求較高的場合,應該使用更好的的數據做種子,而不是系統時鐘;
3.對於只是想產生大量偽隨機數來盡興某種驗證或者統計,未必需要初始化,大不了程序每次運行都產生同樣的一系列隨機數而已——有些情況下,這是無所謂的。
4.作為偽隨機序列產生器的rand()函數,必須具備的一個重要特性就是:產生的序列必須是可重現的。這不僅僅是一個算法,相當大的程度上,它關系到代碼測試的准確性。如果算法中使用了和rand()的結果相關的數據,通過一個可控的可重現序列,我們就有機會再現每一次測試的過程,從而更有效的找到問題的所在。所以這裡提出一個建議,代碼中,如果rand()的函數結果關系到算法的結果,那麼,必須保證你的rand()調用是可重現的。
另外使用rand還用幾個問題:
如何生成 0到 100之間的隨機數?
用"int x = rand() % 100;"這種方法是不或取的,會使產生的隨機數不在隨機。產生一個0到n之間的隨機數的比較好的做法是:
j=(int)(n*rand()/(RAND_MAX+1.0));
如何產生一個范圍在(a,b)之間的隨機數?
先計算a與b的差值,設c=b-a;產生一個介於0和b-a的數值,設
d=(int)((b-a)*rand())/(RAND_MAX+1.0)
讓上面產生的值d加上a就可以了。
如果你使用C++11編程,請使用C++11自己的隨機數生成方法!
雖然前面介紹了那麼多,但是我還是想說C語言的隨機數生成方法有很多缺陷,很容易被引入非隨機性,而且功能單一,如果可以的話去,你最好避免使用它。