C語言正則表達式使用詳解
%[ ] 的用法: %[ ] 表示要讀入一個字符集合 , 如果 [ 後面第一個字符是 ”^” ,則表示反意思。
[ ] 內的字符串可以是 1 或更多字符組成。空字符集( %[] )是違反規定的,可
導致不可預知的結果。 %[^] 也是違反規定的。
%[a-z] 讀取在 a-z 之間的字符串,如果不在此之前則停止,如
char s[]=hello, my friend” ; // 注意 : , 逗號在不 a-z 之間
sscanf( s, “%[a-z]”, string ) ; // string=hello
/*sscanf()是從緩存區s讀取數據到string中;而scanf,fscanf是從標准輸入文件(stdin)和
用戶自定義文件中讀取格式化數*/
%[^a-z] 讀取不在 a-z 之間的字符串,如果碰到 a-z 之間的字符則停止,如
char s[]=HELLOkitty” ; // 注意 : , 逗號在不 a-z 之間
sscanf( s, “%[^a-z]”, string ) ; // string=HELLO
%*[^=] 前面帶 * 號表示不保存變量。跳過符合條件的字符串。
char s[]=notepad=1.0.0.1001 ;
char szfilename [32] = ;
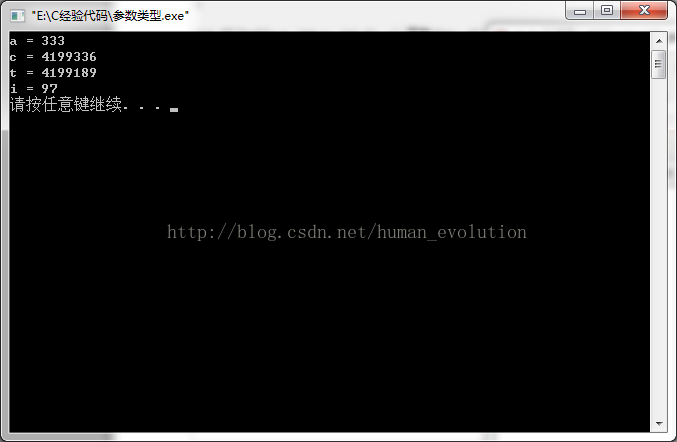
int i = sscanf( s, %*[^=], szfilename ) ; // szfilename=NULL, 因為沒保存
int i = sscanf( s, %*[^=]=%s, szfilename ) ; // szfilename=1.0.0.1001
%40c 讀取 40 個字符
The run-time
library does not automatically append a null terminator
to the string, nor does reading 40 characters
automatically terminate the scanf() function. Because the
library uses buffered input, you must press the ENTER key
to terminate the string scan. If you press the ENTER before
the scanf() reads 40 characters, it is displayed normally,
and the library continues to prompt for additional input
until it reads 40 characters
%[^=] 讀取字符串直到碰到 ’=’ 號, ’^’ 後面可以帶更多字符 , 如:
char s[]=notepad=1.0.0.1001 ;
char szfilename [32] = ;
int i = sscanf( s, %[^=], szfilename ) ; // szfilename=notepad
如果參數格式是: %[^=:] ,那麼也可以從 notepad:1.0.0.1001 讀取 notepad
使用例子:
char s[]=notepad=1.0.0.1001 ;
char szname [32] = ;
char szver [32] = “” ;
sscanf( s, %[^=]=%s, szname , szver ) ; // szname=notepad, szver=1.0.0.1001
總結: %[] 有很大的功能,但是並不是很常用到,主要因為:
1 、許多系統的 scanf 函數都有漏洞 . ( 典型的就是 TC 在輸入浮點型時有時會出錯 ).
2 、用法復雜 , 容易出錯 .
3 、編譯器作語法分析時會很困難 , 從而影響目標代碼的質量和執行效率 .
個人覺得第 3 點最致命,越復雜的功能往往執行效率越低下。而一些簡單的字符串分析我們可以自已處理。
補充:
sscanf,scanf,fscanf中的正則表達式C/C++
每種語言都對正則表達式有著不同程度的支持,在C語言中,有輸入功能的這三個函數對正則表達式的支持並不強大,但是我們還是有必要了解一下。
首先來看看他們的原型:
#include
int scanf(const char *format, ...);
int fscanf(FILE *stream, const char *format, ...);
int sscanf(const char *str, const char *format, ...);
均可以接受變參,sscanf與scanf類似,可以將標准輸入(stdin)作為輸入源。最關鍵的部分,就是format這個參數了。它可以是一個或者多個 {%[*] [width] [{h | l | I64 | L}]type | ' ' | ' ' | ' ' | 非%符號}。
參數解釋:
1、 * 亦可用於格式中, (即 %*d 和 %*s) 加了星號 (*) 表示跳過此數據不讀入. (也就是不把此數據讀入參數中) 2、{a|b|c}表示a,b,c中選一,[d],表示可以有d也可以沒有d。 3、width表示讀取寬度。 4、{h | l | I64 | L}:參數的size,通常h表示單字節size,I表示2字節 size,L表示4字節size(double例外),l64表示8字節size。 5、type : 就是%s,%d之類。 6、特別的:%*[width] [{h | l | I64 | L}]type 表示滿足該條件的被過濾掉,不會向目標參數中寫入值
支持的集合操作:%[a-z] 表示匹配a到z中任意字符,貪婪性(盡可能多的匹配)%[aB'] 匹配a、B、'中一員,貪婪性%[^a] 匹配非a的任意字符,貪婪性
返回值
這三個函數返回成功匹配和分配的輸入項。意思就是你在format參數列表中的格式,返回值可以比你提供的匹配項目數少(有些將會匹配失敗)。提前匹配失敗則返回0。如果達到文件末尾,則返回EOF,當發生錯誤的時候也將返回EOF。你可以通過輸出errno來查看錯誤代碼。
如果使用fscanf來判斷文件是否結束,將會存在安全隱患,如果每次讀取的時候都是匹配失敗,那麼返回值永遠都不會是EOF。scanf族的函數都是要先將數據讀入緩沖區,然後在沖緩沖裡讀取。
注意:scanf族函數會忽略一行開始的空白