原文地址:
http://onevcat.com/2014/01/black-magic-in-macro/

宏定義在C系開發中可以說占有舉足輕重的作用。底層框架自不必說,為了編譯優化和方便,以及跨平台能力,宏被大量使用,可以說底層開發離開define將寸步難行。而在更高層級進行開發時,我們會將更多的重心放在業務邏輯上,似乎對宏的使用和依賴並不多。但是使用宏定義的好處是不言自明的,在節省工作量的同時,代碼可讀性大大增加。如果想成為一個能寫出漂亮優雅代碼的開發者,宏定義絕對是必不可少的技能(雖然宏本身可能並不漂亮優雅XD)。但是因為宏定義對於很多人來說,並不像業務邏輯那樣是每天會接觸的東西。即使是能偶爾使用到一些宏,也更多的僅僅只停留在使用的層級,卻並不會去探尋背後發生的事情。有一些開發者確實也有探尋的動力和意願,但卻在點開一個定義之後發現還有宏定義中還有其他無數定義,再加上滿屏幕都是不同於平時的代碼,既看不懂又不變色,於是乎心生煩惱,怒而回退。本文希望通過循序漸進的方式,通過幾個例子來表述C系語言宏定義世界中的一些基本規則和技巧,從0開始,希望最後能讓大家至少能看懂和還原一些相對復雜的宏。考慮到我自己現在objc使用的比較多,這個站點的讀者應該也大多是使用objc的,所以有部分例子是選自objc,但是本文的大部分內容將是C系語言通用。
如果您完全不知道宏是什麼的話,可以先來熱個身。很多人在介紹宏的時候會說,宏嘛很簡單,就是簡單的查找替換嘛。嗯,只說對了的一半。C中的宏分為兩類,對象宏(object-like macro)和函數宏(function-like macro)。對於對象宏來說確實相對簡單,但卻也不是那麼簡單的查找替換。對象宏一般用來定義一些常數,舉個例子:
//This defines PI #define M_PI 3.14159265358979323846264338327950288
#define關鍵字表明即將開始定義一個宏,緊接著的M_PI是宏的名字,空格之後的數字是內容。類似這樣的#define X A的宏是比較簡單的,在編譯時編譯器會在語義分析認定是宏後,將X替換為A,這個過程稱為宏的展開。比如對於上面的M_PI
#define M_PI 3.14159265358979323846264338327950288
double r = 10.0;
double circlePerimeter = 2 * M_PI * r;
// => double circlePerimeter = 2 * 3.14159265358979323846264338327950288 * r;
printf("Pi is %0.7f",M_PI);
//Pi is 3.1415927
那麼讓我們開始看看另一類宏吧。函數宏顧名思義,就是行為類似函數,可以接受參數的宏。具體來說,在定義的時候,如果我們在宏名字後面跟上一對括號的話,這個宏就變成了函數宏。從最簡單的例子開始,比如下面這個函數宏
//A simple function-like macro #define SELF(x) x NSString *name = @"Macro Rookie"; NSLog(@"Hello %@",SELF(name)); // => NSLog(@"Hello %@",name); // => Hello Macro Rookie
這個宏做的事情是,在編譯時如果遇到SELF,並且後面帶括號,並且括號中的參數個數與定義的相符,那麼就將括號中的參數換到定義的內容裡去,然後替換掉原來的內容。 具體到這段代碼中,SELF接受了一個name,然後將整個SELF(name)用name替換掉。嗯..似乎很簡單很沒用,身經百戰閱碼無數的你一定會認為這個宏是寫出來賣萌的。那麼接受多個參數的宏肯定也不在話下了,例如這樣的:
#define PLUS(x,y) x + y
printf("%d",PLUS(3,2));
// => printf("%d",3 + 2);
// => 5
相比對象宏來說,函數宏要復雜一些,但是看起來也相當簡單吧?嗯,那麼現在熱身結束,讓我們正式開啟宏的大門吧。
因為宏展開其實是編輯器的預處理,因此它可以在更高層級上控制程序源碼本身和編譯流程。而正是這個特點,賦予了宏很強大的功能和靈活度。但是凡事都有兩面性,在獲取靈活的背後,是以需要大量時間投入以對各種邊界情況進行考慮來作為代價的。可能這麼說並不是很能讓人理解,但是大部分宏(特別是函數宏)背後都有一些自己的故事,挖掘這些故事和設計的思想會是一件很有意思的事情。另外,我一直相信在實踐中學習才是真正掌握知識的唯一途徑,雖然可能正在看這篇博文的您可能最初並不是打算親自動手寫一些宏,但是這我們不妨開始動手從實際的書寫和犯錯中進行學習和挖掘,因為只有肌肉記憶和大腦記憶協同起來,才能說達到掌握的水准。可以說,寫宏和用宏的過程,一定是在在犯錯中學習和深入思考的過程,我們接下來要做的,就是重現這一系列過程從而提高進步。
第一個題目是,讓我們一起來實現一個MIN宏吧:實現一個函數宏,給定兩個數字輸入,將其替換為較小的那個數。比如MIN(1,2)出來的值是1。嗯哼,simple enough?定義宏,寫好名字,兩個輸入,然後換成比較取值。比較取值嘛,任何一本入門級別的C程序設計上都會有講啊,於是我們可以很快寫出我們的第一個版本:
//Version 1.0 #define MIN(A,B) A < B ? A : B
Try一下
int a = MIN(1,2);
// => int a = 1 < 2 ? 1 : 2;
printf("%d",a);
// => 1
輸出正確,打包發布!

但是在實際使用中,我們很快就遇到了這樣的情況
int a = 2 * MIN(3, 4);
printf("%d",a);
// => 4
看起來似乎不可思議,但是我們將宏展開就知道發生什麼了
int a = 2 * MIN(3, 4); // => int a = 2 * 3 < 4 ? 3 : 4; // => int a = 6 < 4 ? 3 : 4; // => int a = 4;
嘛,寫程序這個東西,bug出來了,原因知道了,事後大家就都是諸葛亮了。因為小於和比較符號的優先級是較低的,所以乘法先被運算了,修正非常簡單嘛,加括號就好了。
//Version 2.0 #define MIN(A,B) (A < B ? A : B)
這次2 * MIN(3, 4)這樣的式子就輕松愉快地拿下了。經過了這次修改,我們對自己的宏信心大增了...直到,某一天一個怒氣沖沖的同事跑來摔鍵盤,然後給出了一個這樣的例子:
int a = MIN(3, 4 < 5 ? 4 : 5);
printf("%d",a);
// => 4
簡單的相比較三個數字並找到最小的一個而已,要怪就怪你沒有提供三個數字比大小的宏,可憐的同事只好自己實現4和5的比較。在你開始著手解決這個問題的時候,你首先想到的也許是既然都是求最小值,那寫成MIN(3, MIN(4, 5))是不是也可以。於是你就隨手這樣一改,發現結果變成了3,正是你想要的..接下來,開始懷疑之前自己是不是看錯結果了,改回原樣,一個4赫然出現在屏幕上。你終於意識到事情並不是你想像中那樣簡單,於是還是回到最原始直接的手段,展開宏。
int a = MIN(3, 4 < 5 ? 4 : 5); // => int a = (3 < 4 < 5 ? 4 : 5 ? 3 : 4 < 5 ? 4 : 5); //希望你還記得運算符優先級 // => int a = ((3 < (4 < 5 ? 4 : 5) ? 3 : 4) < 5 ? 4 : 5); //為了您不太糾結,我給這個式子加上了括號 // => int a = ((3 < 4 ? 3 : 4) < 5 ? 4 : 5) // => int a = (3 < 5 ? 4 : 5) // => int a = 4
找到問題所在了,由於展開時連接符號和被展開式子中的運算符號優先級相同,導致了計算順序發生了變化,實質上和我們的1.0版遇到的問題是差不多的,還是考慮不周。那麼就再嚴格一點吧,3.0版!
//Version 3.0 #define MIN(A,B) ((A) < (B) ? (A) : (B))
至於為什麼2.0版本中的MIN(3, MIN(4, 5))沒有出問題,可以正確使用,這裡作為練習,大家可以試著自己展開一下,來看看發生了什麼。
經過兩次悲劇,你現在對這個簡單的宏充滿了疑惑。於是你跑了無數的測試用例而且它們都通過了,我們似乎徹底解決了括號問題,你也認為從此這個宏就妥妥兒的哦了。不過如果你真的這麼想,那你就圖樣圖森破了。生活總是殘酷的,該來的bug也一定是會來的。不出意外地,在一個霧霾陰沉的下午,我們又收到了一個出問題的例子。
float a = 1.0f;
float b = MIN(a++, 1.5f);
printf("a=%f, b=%f",a,b);
// => a=3.000000, b=2.000000
拿到這個出問題的例子你的第一反應可能和我一樣,這TM的誰這麼二貨還在比較的時候搞++,這簡直亂套了!但是這樣的人就是會存在,這樣的事就是會發生,你也不能說人家邏輯有錯誤。a是1,a++表示先使用a的值進行計算,然後再加1。那麼其實這個式子想要計算的是取a和b的最小值,然後a等於a加1:所以正確的輸出a為2,b為1才對!嘛,滿眼都是淚,讓我們這些久經摧殘的程序員淡定地展開這個式子,來看看這次又發生了些什麼吧:
float a = 1.0f; float b = MIN(a++, 1.5f); // => float b = ((a++) < (1.5f) ? (a++) : (1.5f))
其實只要展開一步就很明白了,在比較a++和1.5f的時候,先取1和1.5比較,然後a自增1。接下來條件比較得到真以後又觸發了一次a++,此時a已經是2,於是b得到2,最後a再次自增後值為3。出錯的根源就在於我們預想的是a++只執行一次,但是由於宏展開導致了a++被多執行了,改變了預想的邏輯。解決這個問題並不是一件很簡單的事情,使用的方式也很巧妙。我們需要用到一個GNU C的賦值擴展,即使用({...})的形式。這種形式的語句可以類似很多腳本語言,在順次執行之後,會將最後一次的表達式的賦值作為返回。舉個簡單的例子,下面的代碼執行完畢後a的值為3,而且b和c只存在於大括號限定的代碼域中
int a = ({
int b = 1;
int c = 2;
b + c;
});
// => a is 3
有了這個擴展,我們就能做到之前很多做不到的事情了。比如徹底解決MIN宏定義的問題,而也正是GNU C中MIN的標准寫法
//GNUC MIN
#define MIN(A,B) ({ __typeof__(A) __a = (A); __typeof__(B) __b = (B); __a < __b ? __a : __b; })
這裡定義了三個語句,分別以輸入的類型申明了__a和__b,並使用輸入為其賦值,接下來做一個簡單的條件比較,得到__a和__b中的較小值,並使用賦值擴展將結果作為返回。這樣的實現保證了不改變原來的邏輯,先進行一次賦值,也避免了括號優先級的問題,可以說是一個比較好的解決方案了。如果編譯環境支持GNU C的這個擴展,那麼毫無疑問我們應該采用這種方式來書寫我們的MIN宏,如果不支持這個環境擴展,那我們只有人為地規定參數不帶運算或者函數調用,以避免出錯。
關於MIN我們討論已經夠多了,但是其實還存留一個懸疑的地方。如果在同一個scope內已經有__a或者__b的定義的話(雖然一般來說不會出現這種悲劇的命名,不過誰知道呢),這個宏可能出現問題。在申明後賦值將因為定義重復而無法被初始化,導致宏的行為不可預知。如果您有興趣,不妨自己動手試試看結果會是什麼。Apple在Clang中徹底解決了這個問題,我們把Xcode打開隨便建一個新工程,在代碼中輸入MIN(1,1),然後Cmd+點擊即可找到clang中 MIN的寫法。為了方便說明,我直接把相關的部分抄錄如下:
//CLANG MIN
#define __NSX_PASTE__(A,B) A##B
#define MIN(A,B) __NSMIN_IMPL__(A,B,__COUNTER__)
#define __NSMIN_IMPL__(A,B,L) ({ __typeof__(A) __NSX_PASTE__(__a,L) = (A); __typeof__(B) __NSX_PASTE__(__b,L) = (B); (__NSX_PASTE__(__a,L) < __NSX_PASTE__(__b,L)) ? __NSX_PASTE__(__a,L) : __NSX_PASTE__(__b,L); })
似乎有點長,看起來也很吃力。我們先美化一下這宏,首先是最後那個__NSMIN_IMPL__內容實在是太長了。我們知道代碼的話是可以插入換行而不影響含義的,宏是否也可以呢?答案是肯定的,只不過我們不能使用一個單一的回車來完成,而必須在回車前加上一個反斜槓\。改寫一下,為其加上換行好看些:
#define __NSX_PASTE__(A,B) A##B
#define MIN(A,B) __NSMIN_IMPL__(A,B,__COUNTER__)
#define __NSMIN_IMPL__(A,B,L) ({ __typeof__(A) __NSX_PASTE__(__a,L) = (A); \
__typeof__(B) __NSX_PASTE__(__b,L) = (B); \
(__NSX_PASTE__(__a,L) < __NSX_PASTE__(__b,L)) ? __NSX_PASTE__(__a,L) : __NSX_PASTE__(__b,L); \
})
但可以看出MIN一共由三個宏定義組合而成。第一個__NSX_PASTE__裡出現的兩個連著的井號##在宏中是一個特殊符號,它表示將兩個參數連接起來這種運算。注意函數宏必須是有意義的運算,因此你不能直接寫AB來連接兩個參數,而需要寫成例子中的A##B。宏中還有一切其他的自成一脈的運算符號,我們稍後還會介紹幾個。接下來是我們調用的兩個參數的MIN,它做的事是調用了另一個三個參數的宏__NSMIN_IMPL__,其中前兩個參數就是我們的輸入,而第三個__COUNTER__我們似乎不認識,也不知道其從何而來。其實__COUNTER__是一個預定義的宏,這個值在編譯過程中將從0開始計數,每次被調用時加1。因為唯一性,所以很多時候被用來構造獨立的變量名稱。有了上面的基礎,再來看最後的實現宏就很簡單了。整體思路和前面的實現和之前的GNUC MIN是一樣的,區別在於為變量名__a和__b添加了一個計數後綴,這樣大大避免了變量名相同而導致問題的可能性(當然如果你執拗地把變量叫做__a9527並且出問題了的話,就只能說不作死就不會死了)。
花了好多功夫,我們終於把一個簡單的MIN宏徹底搞清楚了。宏就是這樣一類東西,簡單的表面之下隱藏了很多玄機,可謂小有乾坤。作為練習大家可以自己嘗試一下實現一個SQUARE(A),給一個數字輸入,輸出它的平方的宏。雖然一般這個計算現在都是用inline來做了,但是通過和MIN類似的思路我們是可以很好地實現它的,動手試一試吧 :)
Log人人愛,它為我們指明前進方向,它為我們抓蟲提供幫助。在objc中,我們最多使用的log方法就是NSLog輸出信息到控制台了,但是NSLog的標准輸出可謂殘廢,有用信息完全不夠,比如下面這段代碼:
NSArray *array = @[@"Hello", @"My", @"Macro"]; NSLog (@"The array is %@", array);
打印到控制台裡的結果是類似這樣的
2014-01-20 11:22:11.835 TestProject[23061:70b] The array is (
Hello,
My,
Macro
)
我們在輸出的時候關心什麼?除了結果以外,很多情況下我們會對這行log的所在的文件位置方法什麼的會比較關心。在每次NSLog裡都手動加上方法名字和位置信息什麼的無疑是個笨辦法,而如果一個工程裡已經有很多NSLog的調用了,一個一個手動去改的話無疑也是噩夢。我們通過宏,可以很簡單地完成對NSLog原生行為的改進,優雅,高效。只需要在預編譯的pch文件中加上
//A better version of NSLog
#define NSLog(format, ...) do { \
fprintf(stderr, "<%s : %d> %s\n", \
[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], \
__LINE__, __func__); \
(NSLog)((format), ##__VA_ARGS__); \
fprintf(stderr, "-------\n"); \
} while (0)
嘛,這是我們到現在為止見到的最長的一個宏了吧...沒關系,一點一點來分析就好。首先是定義部分,第2行的NSLog(format, ...)。我們看到的是一個函數宏,但是它的參數比較奇怪,第二個參數是...,在宏定義(其實也包括函數定義)的時候,寫為...的參數被叫做可變參數(variadic)。可變參數的個數不做限定。在這個宏定義中,除了第一個參數format將被單獨處理外,接下來輸入的參數將作為整體一並看待。回想一下NSLog的用法,我們在使用NSLog時,往往是先給一個format字符串作為第一個參數,然後根據定義的格式在後面的參數裡跟上寫要輸出的變量之類的。這裡第一個格式化字符串即對應宏裡的format,後面的變量全部映射為...作為整體處理。
接下來宏的內容部分。上來就是一個下馬威,我們遇到了一個do while語句...想想看你上次使用do while是什麼時候吧?也許是C程序設計課的大作業?或者是某次早已被遺忘的算法面試上?總之雖然大家都是明白這個語句的,但是實際中可能用到它的機會少之又少。乍一看似乎這個do while什麼都沒做,因為while是0,所以do肯定只會被執行一次。那麼它存在的意義是什麼呢,我們是不是可以直接簡化一下這個宏,把它給去掉,變成這個樣子呢?
//A wrong version of NSLog
#define NSLog(format, ...) fprintf(stderr, "<%s : %d> %s\n", \
[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], \
__LINE__, __func__); \
(NSLog)((format), ##__VA_ARGS__); \
fprintf(stderr, "-------\n");
答案當然是否定的,也許簡單的測試裡你沒有遇到問題,但是在生產環境中這個宏顯然悲劇了。考慮下面的常見情況
if (errorHappend)
NSLog(@"Oops, error happened");
展開以後將會變成
if (errorHappend)
fprintf((stderr, "<%s : %d> %s\n",[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], __LINE__, __func__);
(NSLog)((format), ##__VA_ARGS__); //I will expand this later
fprintf(stderr, "-------\n");
注意..C系語言可不是靠縮進來控制代碼塊和邏輯關系的。所以說如果使用這個宏的人沒有在條件判斷後加大括號的話,你的宏就會一直調用真正的NSLog輸出東西,這顯然不是我們想要的邏輯。當然在這裡還是需要重新批評一下認為if後的單條執行語句不加大括號也沒問題的同學,這是陋習,無需理由,請改正。不論是不是一條語句,也不論是if後還是else後,都加上大括號,是對別人和自己的一種尊重。
好了知道我們的宏是如何失效的,也就知道了修改的方法。作為宏的開發者,應該力求使用者在最大限度的情況下也不會出錯,於是我們想到直接用一對大括號把宏內容括起來,大概就萬事大吉了?像這樣:
//Another wrong version of NSLog
#define NSLog(format, ...) {
fprintf(stderr, "<%s : %d> %s\n", \
[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], \
__LINE__, __func__); \
(NSLog)((format), ##__VA_ARGS__); \
fprintf(stderr, "-------\n"); \
}
展開剛才的那個式子,結果是
//I am sorry if you don't like { in the same like. But I am a fan of this style :P
if (errorHappend) {
fprintf((stderr, "<%s : %d> %s\n",[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], __LINE__, __func__);
(NSLog)((format), ##__VA_ARGS__);
fprintf(stderr, "-------\n");
};
編譯,執行,正確!因為用大括號標識代碼塊是不會嫌多的,所以這樣一來的話我們的宏在不論if後面有沒有大括號的情況下都能工作了!這麼看來,前面例子中的do while果然是多余的?於是我們又可以愉快地發布了?如果你夠細心的話,可能已經發現問題了,那就是上面最後的一個分號。雖然編譯運行測試沒什麼問題,但是始終稍微有些刺眼有木有?沒錯,因為我們在寫NSLog本身的時候,是將其當作一條語句來處理的,後面跟了一個分號,在宏展開後,這個分號就如同噩夢一般的多出來了。什麼,你還沒看出哪兒有問題?試試看展開這個例子吧:
if (errorHappend)
NSLog(@"Oops, error happened");
else
//Yep, no error, I am happy~ :)
No! I am not haapy at all! 因為編譯錯誤了!實際上這個宏展開以後變成了這個樣子:
if (errorHappend) {
fprintf((stderr, "<%s : %d> %s\n",[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], __LINE__, __func__);
(NSLog)((format), ##__VA_ARGS__);
fprintf(stderr, "-------\n");
}; else {
//Yep, no error, I am happy~ :)
}
因為else前面多了一個分號,導致了編譯錯誤,很惱火..要是寫代碼的人乖乖寫大括號不就啥事兒沒有了麼?但是我們還是有巧妙的解決方法的,那就是上面的do while。把宏的代碼塊添加到do中,然後之後while(0),在行為上沒有任何改變,但是可以巧妙地吃掉那個悲劇的分號,使用do while的版本展開以後是這個樣子的
if (errorHappend)
do {
fprintf((stderr, "<%s : %d> %s\n",[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], __LINE__, __func__);
(NSLog)((format), ##__VA_ARGS__);
fprintf(stderr, "-------\n");
} while (0);
else {
//Yep, no error, I am really happy~ :)
}
這個吃掉分號的方法被大量運用在代碼塊宏中,幾乎已經成為了標准寫法。而且while(0)的好處在於,在編譯的時候,編譯器基本都會為你做好優化,把這部分內容去掉,最終編譯的結果不會因為這個do while而導致運行效率上的差異。在終於弄明白了這個奇怪的do while之後,我們終於可以繼續深入到這個宏裡面了。宏本體內容的第一行沒有什麼值得多說的fprintf(stderr, "<%s : %d> %s\n",,簡單的格式化輸出而已。注意我們使用了\將這個宏分成了好幾行來寫,實際在最後展開時會被合並到同一行內,我們在剛才MIN最後也用到了反斜槓,希望你還能記得。接下來一行我們填寫這個格式輸出中的三個token,
[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], __LINE__, __func__);
這裡用到了三個預定義宏,和剛才的__COUNTER__類似,預定義宏的行為是由編譯器指定的。__FILE__返回當前文件的絕對路徑,__LINE__返回展開該宏時在文件中的行數,__func__是改宏所在scope的函數名稱。我們在做Log輸出時如果帶上這這三個參數,便可以加快解讀Log,迅速定位。關於編譯器預定義的Log以及它們的一些實現機制,感興趣的同學可以移步到gcc文檔的PreDefine頁面和clang的Builtin Macro進行查看。在這裡我們將格式化輸出的三個參數分別設定為文件名的最後一個部分(因為絕對路徑太長很難看),行數,以及方法名稱。
接下來是還原原始的NSLog,(NSLog)((format), ##__VA_ARGS__);中出現了另一個預定義的宏__VA_ARGS__(我們似乎已經找出規律了,前後雙下槓的一般都是預定義)。__VA_ARGS__表示的是宏定義中的...中的所有剩余參數。我們之前說過可變參數將被統一處理,在這裡展開的時候編譯器會將__VA_ARGS__直接替換為輸入中從第二個參數開始的剩余參數。另外一個懸疑點是在它前面出現了兩個井號##。還記得我們上面在MIN中的兩個井號麼,在那裡兩個井號的意思是將前後兩項合並,在這裡做的事情比較類似,將前面的格式化字符串和後面的參數列表合並,這樣我們就得到了一個完整的NSLog方法了。之後的幾行相信大家自己看懂也沒有問題了,最後輸出一下試試看,大概看起來會是這樣的。
-------
<AppDelegate.m : 46> -[AppDelegate application:didFinishLaunchingWithOptions:]
2014-01-20 16:44:25.480 TestProject[30466:70b] The array is (
Hello,
My,
Macro
)
-------
帶有文件,行號和方法的輸出,並且用橫槓隔開了(請原諒我沒有質感的設計,也許我應該畫一只牛,比如這樣?),debug的時候也許會輕松一些吧 :)
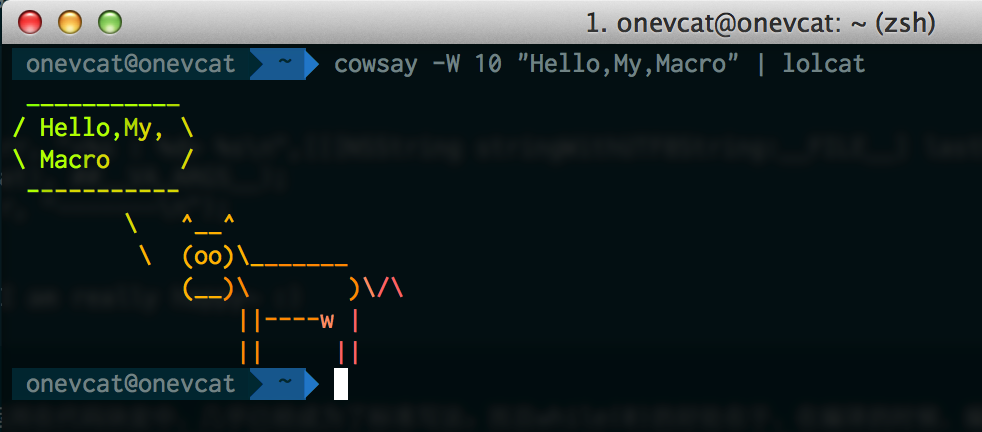
這個Log有三個懸念點,首先是為什麼我們要把format單獨寫出來,然後吧其他參數作為可變參數傳遞呢?如果我們不要那個format,而直接寫成NSLog(...)會不會有問題?對於我們這裡這個例子來說的話是沒有變化的,但是我們需要記住的是...是可變參數列表,它可以代表一個、兩個,或者是很多個參數,但同時它也能代表零個參數。如果我們在申明這個宏的時候沒有指定format參數,而直接使用參數列表,那麼在使用中不寫參數的NSLog()也將被匹配到這個宏中,導致編譯無法通過。如果你手邊有Xcode,也可以看看Cocoa中真正的NSLog方法的實現,可以看到它也是接收一個格式參數和一個參數列表的形式,我們在宏裡這麼定義,正是為了其傳入正確合適的參數,從而保證使用者可以按照原來的方式正確使用這個宏。
第二點是既然我們的可變參數可以接受任意個輸入,那麼在只有一個format輸入,而可變參數個數為零的時候會發生什麼呢?不妨展開看一看,記住##的作用是拼接前後,而現在##之後的可變參數是空:
NSLog(@"Hello");
=> do {
fprintf((stderr, "<%s : %d> %s\n",[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], __LINE__, __func__);
(NSLog)((@"Hello"), );
fprintf(stderr, "-------\n");
} while (0);
中間的一行(NSLog)(@"Hello", );似乎是存在問題的,你一定會有疑惑,這種方式怎麼可能編譯通過呢?!原來大神們其實早已想到這個問題,並且進行了一點特殊的處理。這裡有個特殊的規則,在逗號和__VA_ARGS__之間的雙井號,除了拼接前後文本之外,還有一個功能,那就是如果後方文本為空,那麼它會將前面一個逗號吃掉。這個特性當且僅當上面說的條件成立時才會生效,因此可以說是特例。加上這條規則後,我們就可以將剛才的式子展開為正確的(NSLog)((@"Hello"));了。
最後一個值得討論的地方是(NSLog)((format), ##__VA_ARGS__);的括號使用。把看起來能去掉的括號去掉,寫成NSLog(format, ##__VA_ARGS__);是否可以呢?在這裡的話應該是沒有什麼大問題的,首先format不會被調用多次也不太存在誤用的可能性(因為最後編譯器會檢查NSLog的輸入是否正確)。另外你也不用擔心展開以後式子裡的NSLog會再次被自己展開,雖然展開式中NSLog也滿足了我們的宏定義,但是宏的展開非常聰明,展開後會自身無限循環的情況,就不會再次被展開了。
作為一個您讀到了這裡的小獎勵,附送三個debug輸出rect,size和point的宏,希望您能用上(嗯..想想曾經有多少次你需要打印這些結構體的某個數字而被折磨致死,讓它們玩兒蛋去吧!當然請先加油看懂它們吧)
#define NSLogRect(rect) NSLog(@"%s x:%.4f, y:%.4f, w:%.4f, h:%.4f", #rect, rect.origin.x, rect.origin.y, rect.size.width, rect.size.height) #define NSLogSize(size) NSLog(@"%s w:%.4f, h:%.4f", #size, size.width, size.height) #define NSLogPoint(point) NSLog(@"%s x:%.4f, y:%.4f", #point, point.x, point.y)
當然不是說上面介紹的宏實際中不能用。它們相對簡單,但是裡面坑不少,所以顯得很有特點,非常適合作為入門用。而實際上在日常中很多我們常用的宏並沒有那麼多奇怪的問題,很多時候我們按照想法去實現,再稍微注意一下上述介紹的可能存在的共通問題,一個高質量的宏就可以誕生。如果能寫出一些有意義價值的宏,小了從對你的代碼的使用者來說,大了從整個社區整個世界和減少碳排放來說,你都做出了相當的貢獻。我們通過幾個實際的例子來看看,宏是如何改變我們的生活,和寫代碼的習慣的吧。
先來看看這兩個宏
#define XCTAssertTrue(expression, format...) \
_XCTPrimitiveAssertTrue(expression, ## format)
#define _XCTPrimitiveAssertTrue(expression, format...) \
({ \
@try { \
BOOL _evaluatedExpression = !!(expression); \
if (!_evaluatedExpression) { \
_XCTRegisterFailure(_XCTFailureDescription(_XCTAssertion_True, 0, @#expression),format); \
} \
} \
@catch (id exception) { \
_XCTRegisterFailure(_XCTFailureDescription(_XCTAssertion_True, 1, @#expression, [exception reason]),format); \
}\
})
如果您常年做蘋果開發,卻沒有見過或者完全不知道XCTAssertTrue是什麼的話,強烈建議補習一下測試驅動開發的相關知識,我想應該會對您之後的道路很有幫助。如果你已經很熟悉這個命令了,那我們一起開始來看看幕後發生了什麼。
有了上面的基礎,相信您大體上應該可以自行解讀這個宏了。({...})的語法和##都很熟悉了,這裡有三個值得注意的地方,在這個宏的一開始,我們後面的的參數是format...,這其實也是可變參數的一種寫法,和...與__VA_ARGS__配對類似,{NAME}...將於{NAME}配對使用。也就是說,在這裡宏內容的format指代的其實就是定義的先對expression取了兩次反?我不是科班出身,但是我還能依稀記得這在大學程序課上講過,兩次取反的操作可以確保結果是BOOL值,這在objc中還是比較重要的(關於objc中BOOL的討論已經有很多,如果您還沒能分清BOOL, bool和Boolean,可以參看NSHisper的這篇文章)。然後就是@#expression這個式子。我們接觸過雙井號##,而這裡我們看到的操作符是單井號#,注意井號前面的@是objc的編譯符號,不屬於宏操作的對象。單個井號的作用是字符串化,簡單來說就是將替換後在兩頭加上"",轉為一個C字符串。這裡使用@然後緊跟#expression,出來後就是一個內容是expression的內容的NSString。然後這個NSString再作為參數傳遞給_XCTRegisterFailure和_XCTFailureDescription等,繼續進行展開,這些是後話。簡單一瞥,我們大概就可以想象宏幫助我們省了多少事兒了,如果各位看官要是寫個斷言還要來個十多行的話,想象都會瘋掉的吧。
另外一個例子,找了人民群眾喜聞樂見的ReactiveCocoa(RAC)中的一個宏定義。對於RAC不熟悉或者沒聽過的朋友,可以簡單地看看Limboy的一系列相關博文(搜索ReactiveCocoa),介紹的很棒。如果覺得“哇哦這個好酷我很想學”的話,不妨可以跟隨raywenderlich上這個系列的教程做一些實踐,裡面簡單地用到了RAC,但是都已經包含了RAC的基本用法了。RAC中有幾個很重要的宏,它們是保證RAC簡潔好用的基本,可以說要是沒有這幾個宏的話,是不會有人喜歡RAC的。其中RACObserve就是其中一個,它通過KVC來為對象的某個屬性創建一個信號返回(如果你看不懂這句話,不要擔心,這對你理解這個宏的寫法和展開沒有任何影響)。對於這個宏,我決定不再像上面那樣展開和講解,我會在最後把相關的宏都貼出來,大家不妨拿它練練手,看看能不能將其展開到代碼的狀態,並且明白其中都發生了些什麼。如果你遇到什麼問題或者在展開過程中有所心得,歡迎在評論裡留言分享和交流 :)
好了,這篇文章已經夠長了。希望在看過以後您在看到宏的時候不再發怵,而是可以很開心地說這個我會這個我會這個我也會。最終目標當然是寫出漂亮高效簡潔的宏,這不論對於提高生產力還是~震懾你的同事~提升自己實力都會很有幫助。
另外,在這裡一定要宣傳一下關注了很久的@hangcom 吳航前輩的新書《iOS應用逆向工程》。很榮幸能夠在發布之前得到前輩的允許拜讀了整本書,可以說看的暢快淋漓。我之前並沒有越獄開發的任何基礎,也對相關領域知之甚少,在這樣的前提下跟隨書中的教程和例子進行探索的過程可以說是十分有趣。我也得以能夠用不同的眼光和高度來審視這幾年所從事的iOS開發行業,獲益良多。可以說《iOS應用逆向工程》是我近期所愉快閱讀到的很cool的一本好書。現在這本書還在預售中,但是距離1月28日的正式發售已經很近,有興趣的同學可以前往亞馬遜或者ChinaPub的相關頁面預定,相信這本書將會是iOS技術人員非常棒的春節讀物。
最後是我們說好的留給大家玩的練習,我加了一點注釋幫助大家稍微理解每個宏是做什麼的,在文章後面留了一塊試驗田,大家可以隨便填寫玩弄。總之,加油!
//調用 RACSignal是類的名字
RACSignal *signal = RACObserve(self, currentLocation);
//以下開始是宏定義
//rac_valuesForKeyPath:observer:是方法名
#define RACObserve(TARGET, KEYPATH) \
[(id)(TARGET) rac_valuesForKeyPath:@keypath(TARGET, KEYPATH) observer:self]
#define keypath(...) \
metamacro_if_eq(1, metamacro_argcount(__VA_ARGS__))(keypath1(__VA_ARGS__))(keypath2(__VA_ARGS__))
//這個宏在取得keypath的同時在編譯期間判斷keypath是否存在,避免誤寫
//您可以先不用介意這裡面的巫術..
#define keypath1(PATH) \
(((void)(NO && ((void)PATH, NO)), strchr(# PATH, '.') + 1))
#define keypath2(OBJ, PATH) \
(((void)(NO && ((void)OBJ.PATH, NO)), # PATH))
//A和B是否相等,若相等則展開為後面的第一項,否則展開為後面的第二項
//eg. metamacro_if_eq(0, 0)(true)(false) => true
// metamacro_if_eq(0, 1)(true)(false) => false
#define metamacro_if_eq(A, B) \
metamacro_concat(metamacro_if_eq, A)(B)
#define metamacro_if_eq1(VALUE) metamacro_if_eq0(metamacro_dec(VALUE))
#define metamacro_if_eq0(VALUE) \
metamacro_concat(metamacro_if_eq0_, VALUE)
#define metamacro_if_eq0_1(...) metamacro_expand_
#define metamacro_expand_(...) __VA_ARGS__
#define metamacro_argcount(...) \
metamacro_at(20, __VA_ARGS__, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1)
#define metamacro_at(N, ...) \
metamacro_concat(metamacro_at, N)(__VA_ARGS__)
#define metamacro_concat(A, B) \
metamacro_concat_(A, B)
#define metamacro_concat_(A, B) A ## B
#define metamacro_at2(_0, _1, ...) metamacro_head(__VA_ARGS__)
#define metamacro_at20(_0, _1, _2, _3, _4, _5, _6, _7, _8, _9, _10, _11, _12, _13, _14, _15, _16, _17, _18, _19, ...) metamacro_head(__VA_ARGS__)
#define metamacro_head(...) \
metamacro_head_(__VA_ARGS__, 0)
#define metamacro_head_(FIRST, ...) FIRST
#define metamacro_dec(VAL) \
metamacro_at(VAL, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19)
//調用 RACSignal是類的名字 RACSignal *signal = RACObserve(self, currentLocation);