閒著沒事測試下if-else的執行效率
測試環境:Mac pro i7 2.3Ghz 。。。編譯器gcc 4.9,代碼沒有進行優化-O0;
測試代碼:c代碼1:
int main(){
int n=100000000;
int b=-1;
int a=0;
while(n-->0){
if(b<0) b--;else b--;
if(b<0) b--;else b--;
if(b<0) b--;else b--;
if(b<0) b--;else b--;
if(b<0) b--;else b--;
if(b<0) b--;else b--;
if(b<0) b--;else b--;
if(b<0) b--;else b--;
if(b<0) b--;else b--;
if(b<0) b--;else b--;
}
return 0;
}匯編代碼1:
_main: LFB0: pushl %ebp LCFI0: movl %esp, %ebp LCFI1: subl $16, %esp movl $100000000, -4(%ebp) movl $-1, -8(%ebp) movl $0, -12(%ebp) jmp L2 L22: cmpl $0, -8(%ebp) jns L3 subl $1, -8(%ebp) jmp L4 L3: subl $1, -8(%ebp) L4: cmpl $0, -8(%ebp) jns L5 subl $1, -8(%ebp) jmp L6 L5: subl $1, -8(%ebp) L6: cmpl $0, -8(%ebp) jns L7 subl $1, -8(%ebp) jmp L8 L7: subl $1, -8(%ebp) L8: cmpl $0, -8(%ebp) jns L9 subl $1, -8(%ebp) jmp L10 L9: subl $1, -8(%ebp) L10: cmpl $0, -8(%ebp) jns L11 subl $1, -8(%ebp) jmp L12 L11: subl $1, -8(%ebp) L12: cmpl $0, -8(%ebp) jns L13 subl $1, -8(%ebp) jmp L14 L13: subl $1, -8(%ebp) L14: cmpl $0, -8(%ebp) jns L15 subl $1, -8(%ebp) jmp L16 L15: subl $1, -8(%ebp) L16: cmpl $0, -8(%ebp) jns L17 subl $1, -8(%ebp) jmp L18 L17: subl $1, -8(%ebp) L18: cmpl $0, -8(%ebp) jns L19 subl $1, -8(%ebp) jmp L20 L19: subl $1, -8(%ebp) L20: cmpl $0, -8(%ebp) jns L21 subl $1, -8(%ebp) jmp L2 L21: subl $1, -8(%ebp) L2: movl -4(%ebp), %eax leal -1(%eax), %edx movl %edx, -4(%ebp) testl %eax, %eax jg L22 movl $0, %eax leave
c代碼2:
int main(){
int n=100000000;
int b=-1;
int a=0;
while(n-->0){
if(b>0) b--;else b--;
if(b>0) b--;else b--;
if(b>0) b--;else b--;
if(b>0) b--;else b--;
if(b>0) b--;else b--;
if(b>0) b--;else b--;
if(b>0) b--;else b--;
if(b>0) b--;else b--;
if(b>0) b--;else b--;
if(b>0) b--;else b--;
}
return 0;
}匯編代碼2:
_main: LFB0: pushl %ebp LCFI0: movl %esp, %ebp LCFI1: subl $16, %esp movl $100000000, -4(%ebp) movl $-1, -8(%ebp) movl $0, -12(%ebp) jmp L2 L22: cmpl $0, -8(%ebp) jle L3 subl $1, -8(%ebp) jmp L4 L3: subl $1, -8(%ebp) L4: cmpl $0, -8(%ebp) jle L5 subl $1, -8(%ebp) jmp L6 L5: subl $1, -8(%ebp) L6: cmpl $0, -8(%ebp) jle L7 subl $1, -8(%ebp) jmp L8 L7: subl $1, -8(%ebp) L8: cmpl $0, -8(%ebp) jle L9 subl $1, -8(%ebp) jmp L10 L9: subl $1, -8(%ebp) L10: cmpl $0, -8(%ebp) jle L11 subl $1, -8(%ebp) jmp L12 L11: subl $1, -8(%ebp) L12: cmpl $0, -8(%ebp) jle L13 subl $1, -8(%ebp) jmp L14 L13: subl $1, -8(%ebp) L14: cmpl $0, -8(%ebp) jle L15 subl $1, -8(%ebp) jmp L16 L15: subl $1, -8(%ebp) L16: cmpl $0, -8(%ebp) jle L17 subl $1, -8(%ebp) jmp L18 L17: subl $1, -8(%ebp) L18: cmpl $0, -8(%ebp) jle L19 subl $1, -8(%ebp) jmp L20 L19: subl $1, -8(%ebp) L20: cmpl $0, -8(%ebp) jle L21 subl $1, -8(%ebp) jmp L2 L21: subl $1, -8(%ebp) L2: movl -4(%ebp), %eax leal -1(%eax), %edx movl %edx, -4(%ebp) testl %eax, %eax jg L22 movl $0, %eax leave執行結果:

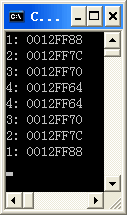
看來else執行的效率高一些。。。。