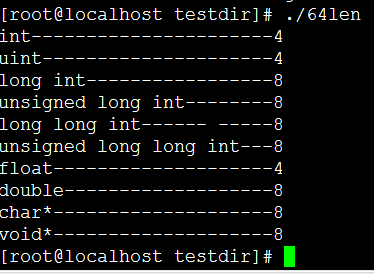
對於索引查找,或者連續表查找,都要進行關鍵字和查找值的比較,有沒有不用比較,通過關鍵字,按一定的計算,得到關鍵字對應的地址,那就是散列表查找。
存儲位置=F(關鍵字);
散列技術是在記錄的存儲位置和它的關鍵字之間建立一個確定的對應關系F,使得每個關鍵字key對應一個存儲位置F(key);
把這種對應關系F稱為散列函數,又稱哈希函數。采用散列技術將記錄存儲在一塊連續的空間上,這塊連續空間稱為散列表或哈希表。那麼關鍵字對應的記錄位置我們稱為散列地址。
沖突:若兩個關鍵字key1!=key2,但是卻有Fkey1)==f(key2),這種現象我們稱為沖突,並把key1和key2稱為這個散列函數的同義詞。
8.7.1散列函數的構造方法
如何評價一個好的散列函數
1)計算簡單
2)散列地址分布均勻,而不是分布在少數幾個地址上。
1、直接定址法。
2、數字分析法。
3、平法取中法。
4、折疊法。
5、除留余數法。
F(key)=key mod pp<=m)
mod是取模的意思。
通常p為小於或等於表長的最小質數。
6、隨機數法,具體是偽隨機數法。
8.7.2處理散列沖突的方法
如果在使用散列函數後發現兩個關鍵字key1!=key2,但是卻有f(key1)=f(key2),即有沖突時怎麼辦。
1、開放定址法
一旦發生了沖突,就去尋找下一個空的散列地址,只要散列表足夠大,空的散列地址總能找到,並將記錄存入。
f1(key) = (f(key) + d1) mod m(d1=1,2,3,4......,m-1)
查找效率比較低,會產生堆積現象。
2、鏈地址法
有沖突了也不換地方,在散列表中增加頭指針,接到和它沖突的後面,假如關鍵字 3和關鍵字6發生了沖突,都要存在地址9中,可以這樣設計。
地址9: 3 數據指針—————> 6 數據NULL
本文出自 “李海川” 博客,請務必保留此出處http://lihaichuan.blog.51cto.com/498079/1282378