作者:July、wuliming、pkuoliver
出處:http://blog.csdn.net/v_JULY_v。
說明:本文分為三部分內容,
第一部分為一道百度面試題Top K算法的詳解;第二部分為關於Hash表算法的詳細闡述;第三部分為打造一個最快的Hash表算法。
------------------------------------
第一部分:Top K 算法詳解
問題描述
百度面試題:
搜索引擎會通過日志文件把用戶每次檢索使用的所有檢索串都記錄下來,每個查詢串的長度為1-255字節。
假設目前有一千萬個記錄(這些查詢串的重復度比較高,雖然總數是1千萬,但如果除去重復後,不超過3百萬個。一個查詢串的重復度越高,說明查詢它的用戶越多,也就是越熱門。),請你統計最熱門的10個查詢串,要求使用的內存不能超過1G。
必備知識:
什麼是哈希表?
哈希表(Hash table,也叫散列表),是根據關鍵碼值(Key value)而直接進行訪問的數據結構。也就是說,它通過把關鍵碼值映射到表中一個位置來訪問記錄,以加快查找的速度。這個映射函數叫做散列函數,存放記錄的數組叫做散列表。
哈希表的做法其實很簡單,就是把Key通過一個固定的算法函數既所謂的哈希函數轉換成一個整型數字,然後就將該數字對數組長度進行取余,取余結果就當作數組的下標,將value存儲在以該數字為下標的數組空間裡。
而當使用哈希表進行查詢的時候,就是再次使用哈希函數將key轉換為對應的數組下標,並定位到該空間獲取value,如此一來,就可以充分利用到數組的定位性能進行數據定位(文章第二、三部分,會針對Hash表詳細闡述)。
問題解析:
要統計最熱門查詢,首先就是要統計每個Query出現的次數,然後根據統計結果,找出Top 10。所以我們可以基於這個思路分兩步來設計該算法。
即,此問題的解決分為以下倆個步驟:
第一步:Query統計
Query統計有以下倆個方法,可供選擇:
1、直接排序法
首先我們最先想到的的算法就是排序了,首先對這個日志裡面的所有Query都進行排序,然後再遍歷排好序的Query,統計每個Query出現的次數了。
但是題目中有明確要求,那就是內存不能超過1G,一千萬條記錄,每條記錄是225Byte,很顯然要占據2.55G內存,這個條件就不滿足要求了。
讓我們回憶一下數據結構課程上的內容,當數據量比較大而且內存無法裝下的時候,我們可以采用外排序的方法來進行排序,這裡我們可以采用歸並排序,因為歸並排序有一個比較好的時間復雜度O(NlgN)。
排完序之後我們再對已經有序的Query文件進行遍歷,統計每個Query出現的次數,再次寫入文件中。
綜合分析一下,排序的時間復雜度是O(NlgN),而遍歷的時間復雜度是O(N),因此該算法的總體時間復雜度就是O(N+NlgN)=O(NlgN)。
2、Hash Table法
在第1個方法中,我們采用了排序的辦法來統計每個Query出現的次數,時間復雜度是NlgN,那麼能不能有更好的方法來存儲,而時間復雜度更低呢?
題目中說明了,雖然有一千萬個Query,但是由於重復度比較高,因此事實上只有300萬的Query,每個Query255Byte,因此我們可以考慮把他們都放進內存中去,而現在只是需要一個合適的數據結構,在這裡,Hash Table絕對是我們優先的選擇,因為Hash Table的查詢速度非常的快,幾乎是O(1)的時間復雜度。
那麼,我們的算法就有了:維護一個Key為Query字串,Value為該Query出現次數的HashTable,每次讀取一個Query,如果該字串不在Table中,那麼加入該字串,並且將Value值設為1;如果該字串在Table中,那麼將該字串的計數加一即可。最終我們在O(N)的時間復雜度內完成了對該海量數據的處理。
本方法相比算法1:在時間復雜度上提高了一個數量級,為O(N),但不僅僅是時間復雜度上的優化,該方法只需要IO數據文件一次,而算法1的IO次數較多的,因此該算法2比算法1在工程上有更好的可操作性。
第二步:找出Top 10
算法一:普通排序
我想對於排序算法大家都已經不陌生了,這裡不在贅述,我們要注意的是排序算法的時間復雜度是NlgN,在本題目中,三百萬條記錄,用1G內存是可以存下的。
算法二:部分排序
題目要求是求出Top 10,因此我們沒有必要對所有的Query都進行排序,我們只需要維護一個10個大小的數組,初始化放入10個Query,按照每個Query的統計次數由大到小排序,然後遍歷這300萬條記錄,每讀一條記錄就和數組最後一個Query對比,如果小於這個Query,那麼繼續遍歷,否則,將數組中最後一條數據淘汰,加入當前的Query。最後當所有的數據都遍歷完畢之後,那麼這個數組中的10個Query便是我們要找的Top10了。
不難分析出,這樣,算法的最壞時間復雜度是N*K, 其中K是指top多少。
算法三:堆
在算法二中,我們已經將時間復雜度由NlogN優化到NK,不得不說這是一個比較大的改進了,可是有沒有更好的辦法呢?
分析一下,在算法二中,每次比較完成之後,需要的操作復雜度都是K,因為要把元素插入到一個線性表之中,而且采用的是順序比較。這裡我們注意一下,該數組是有序的,一次我們每次查找的時候可以采用二分的方法查找,這樣操作的復雜度就降到了logK,可是,隨之而來的問題就是數據移動,因為移動數據次數增多了。不過,這個算法還是比算法二有了改進。
基於以上的分析,我們想想,有沒有一種既能快速查找,又能快速移動元素的數據結構呢?回答是肯定的,那就是堆。
借助堆結構,我們可以在log量級的時間內查找和調整/移動。因此到這裡,我們的算法可以改進為這樣,維護一個K(該題目中是10)大小的小根堆,然後遍歷300萬的Query,分別和根元素進行對比。
思想與上述算法二一致,只是算法在算法三,我們采用了最小堆這種數據結構代替數組,把查找目標元素的時間復雜度有O(K)降到了O(logK)。
那麼這樣,采用堆數據結構,算法三,最終的時間復雜度就降到了N‘logK,和算法二相比,又有了比較大的改進。
總結:
至此,算法就完全結束了,經過上述第一步、先用Hash表統計每個Query出現的次數,O(N);然後第二步、采用堆數據結構找出Top 10,N*O(logK)。所以,我們最終的時間復雜度是:O(N) + N*O(logK)。(N為1000萬,N’為300萬)。如果各位有什麼更好的算法,歡迎留言評論。第一部分,完。
第二部分、Hash表 算法的詳細解析
什麼是Hash
Hash,一般翻譯做“散列”,也有直接音譯為“哈希”的,就是把任意長度的輸入(又叫做預映射, pre-image),通過散列算法,變換成固定長度的輸出,該輸出就是散列值。這種轉換是一種壓縮映射,也就是,散列值的空間通常遠小於輸入的空間,不同的輸入可能會散列成相同的輸出,而不可能從散列值來唯一的確定輸入值。簡單的說就是一種將任意長度的消息壓縮到某一固定長度的消息摘要的函數。
HASH主要用於信息安全領域中加密算法,它把一些不同長度的信息轉化成雜亂的128位的編碼,這些編碼值叫做HASH值. 也可以說,hash就是找到一種數據內容和數據存放地址之間的映射關系。
數組的特點是:尋址容易,插入和刪除困難;而鏈表的特點是:尋址困難,插入和刪除容易。那麼我們能不能綜合兩者的特性,做出一種尋址容易,插入刪除也容易的數據結構?答案是肯定的,這就是我們要提起的哈希表,哈希表有多種不同的實現方法,我接下來解釋的是最常用的一種方法——拉鏈法,我們可以理解為“鏈表的數組”,如圖:
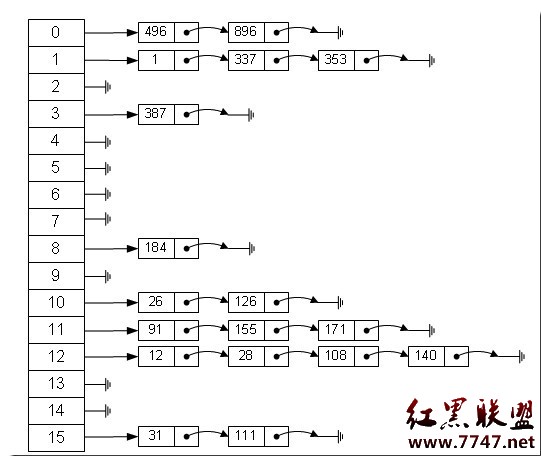
左邊很明顯是個數組,數組的每個成員包括一個指針,指向一個鏈表的頭,當然這個鏈表可能為空,也可能元素很多。我們根據元素的一些特征把元素分配到不同的鏈表中去,也是根據這些特征,找到正確的鏈表,再從鏈表中找出這個元素。
元素特征轉變為數組下標的方法就是散列法。散列法當然不止一種,下面列出三種比較常用的:
1,除法散列法
最直觀的一種,上圖使用的就是這種散列法,公式:
index = value % 16
學過匯編的都知道,求模數其實是通過一個除法運算得到的,所以叫“除法散列法”。
2,平方散列法
求index是非常頻繁的操作,而乘法的運算要比除法來得省時(對現在的CPU來說,估計我們感覺不出來),所以我們考慮把除法換成乘法和一個位移操作。公式:
index = (value * value) >> 28 (右移,除以2^28。記法:左移變大,是乘。右移變小,是除。)
如果數值分配比較均勻的話這種方法能得到不錯的結果,但我上面畫的那個圖的各個元素的值算出來的index都是0——非常失敗。也許你還有個問題,value如果很大,value * value不會溢出嗎?