每當我看到經典的算法題,就懷念高中,感覺很多算法題就是高中的題目,誰叫哥只讀了個專科,高數基本相當沒學。
有空要看看高數啊,想當年數學那是相當的......
#include <iostream>
using namespace std;
class FindTheOne
{
public:
方法一
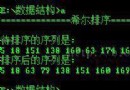
第一個想到的方法是見一個二維數組,一維存數組中的數據,二維存這個數出現的次數。出現次數最多的那個數就是要找的那個數
由於某個數出現的次數超過數組長度的一半,所以二維數組的長度只需要這個數組的一半。代碼實現如下,
當然這個方法很糟糕,時間復雜度和空間復雜度都比較大,想練手的我還是寫了一下。
方法一
void Search(int A[],int len,int& theOne)
{
if(NULL==A || len<=0)
{
return ;
}
int (*B)[2]=new int[len/2][2];
B[0][0]=A[0];
B[0][1]=1;
int t=0;
bool notExist=true;
for(int i=1;i<len;++i)
{
for(int j=0;j<t;++j)
{
if(A[i]==B[j][0])
{
B[j][1]++;
notExist=false;
break;
}
}
if(notExist)
{
B[t++][0]=A[i];
}
}
int max=1;
int k=0;
for(int i=0;i<len/2;++i)
{
if(B[i][1]>max)
{
max=B[i][1];
k=i;
}
}
theOne=B[k][0];
}
方法二
將數組排序,最中間的那個數就是您要找的數。
如果出現最多的那個數是最小的,那麼1至(n+1)/2都是那個數
如果出現最多的那個數是最大的,那麼(n-1)/2至n都是那個數
如果不是最小也不是最大,當這個數由最小慢慢變成最大的最大的數時,你會發現中間的那個數的值是不變的。
綜上所述,中間的那個數就是你要找的那個數。
時間復雜度就是你排序用的時間。排序真的不想寫了(可以參考《我的另一篇博客》)。大家都知道排序還是相當費時的,當然這個方法還是不太好。
方法三
這個方法借用了別人的思路。
在這裡我做一下簡單的分析。
這個算法的時間復雜度是O(n),另外用了兩個輔助變量。
k用於臨時存儲數組中的數據,j用於存儲某個數出現的次數。
開始時k存儲數組中的第一個數,j為0,如果數組出現的數於k相等,則j加1,否則就減1,如果j為0,就把當前數組中的數賦給k
因為指定的數出現的次數大於數組長度的一半,所有j++與j--相抵消之後,最後j的值是大於等於1的,k中存的那個數就是出現最多的那個數。
下面這個算法只適合數組中數組中某個數的出現次數超過數組長度一半的數組,符合題意。
方法三
int Search(int A[],int len)
{
if(NULL==A || len<=0)
{
return -1;
}
int k, j=0;
for(int i=0;i<len;++i)
{
if(j==0)
{
k=A[i];
}
if(k==A[i])
{
++j;
//有人說++j比j++有先天的優勢,不知你是否聽說,如果你也聽說,有沒有想過More Effective C++(C++程序員必看書籍)
}
else
{
--j;
}
}
return k;
}
}
;