一下內容僅是個人理解,有錯誤之處,望大家諒解和指正。
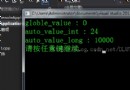
a[i][j]使用時間:94s
for( k = 0 ; k <10000 ; k++ )
for( i = 0 ; i<MAX; i++ )
for( j = 0;j < MAX; j++ )
a[i][j] = 0;
a[j][i]使用時間:488s
for( k = 0 ; k < 10000 ; k++ )
for( i = 0 ; i<MAX; i++ )
for( j = 0;j < MAX; j++ )
a[j][i] = 0;
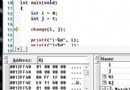
我將兩種方法使用gcc生成了匯編代碼。使用diff比較只發現了一下四句匯編代碼的不同
1c1
< .file
"array.c"
---
> .file
"array1.c"
31c31
< movl
4194352(%esp), %eax
---
> movl
4194356(%esp), %eax
33c33
< addl
4194356(%esp), %eax
---
> addl www.2cto.com
4194352(%esp), %eax
並且,這四句匯編在這行的時候不會產生性能差別,那性能差別出現在那裡。可定不是循環、計算數據產生的差別。差別會出現在內存的訪問位置上嗎?不會的,內存是隨機訪問,訪問任何一個位置內存的地址的時間應該是一樣的。我們現在考慮一下是不是操作系統的緩存的功能。首先,本程序在加載到內存執行、以後除了cpu訪問內存之外沒有任何的資源消耗。所以說不是系統的問題。想了很久,想到cpu訪問數據的時候是以塊進行訪問的,將取來的數據放到緩存中。因為a[i][i]是順序訪問,所以cpu緩存中的數據可以直接使用,無需再訪問內存。而a[j][i]非順序訪問,下一個訪問的位置,不在cpu的緩存中。
提議:在寫代碼的時候
1. 對數組、結構體進行順序訪問。提高緩存的命中率。
2. 減少不必要的判斷,提高cpu的分支預測的命中率