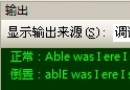
目前,我們接觸的漢字編碼主要包括GBK和GB2312。其中,GB2312又稱國標碼,它是一個簡化字的編碼規范,也包括其他的符號、字母、日文假名等,共7445個圖形字符,其中漢字占6763個。我們平時說6768個漢字,實際上裡邊有5個編碼為空白,所以總共有6763個漢字。GB2312規定“對任意一個圖形字符都采用兩個字節表示,每個字節均采用七位編碼表示”,習慣上稱第一個字節為“高字節”,第二個字節為“低字節”。GB2312中漢字的編碼范圍為,第一字節0xB0-0xF7(對應十進制為176-247),第二個字節0xA0-0xFE(對應十進制為160-254)。而GBK是GB2312的擴展,是向上兼容的,GB2312中的漢字的編碼與GBK中漢字的相同,只不過GBK中還包含繁體字的編碼。GBK中每個漢字仍然占用兩個字節,第一個字節的范圍是0x81-0xFE(即129-254),第二個字節的范圍是0x40-0xFE(即64-254)。GBK中有碼位23940個,包含漢字21003個。因此,下面的代碼也是在使用GB2312或GBK編碼的環境下測試通過。
sbc_to_dbc( *sbc, * (; *sbc; ++ ((*sbc & ) == && (*(sbc + ) & ) == )
*dbc++ = ++ ((*sbc & ) == && (*(sbc + ) & ) >= && (*(sbc + ) & ) <= )
*dbc++ = *++sbc -
(*sbc < )
*dbc++ = *sbc++ *dbc++ = * *dbc =
dbc_to_sbc( *dbc, * (; *dbc; ++ ((*dbc & ) == )
*sbc++ = *sbc++ = ((*dbc & ) >= && (*dbc & ) <= *sbc++ = *sbc++ = *dbc +
(*dbc < )
*sbc++ = *dbc++ *sbc++ = * *sbc = }