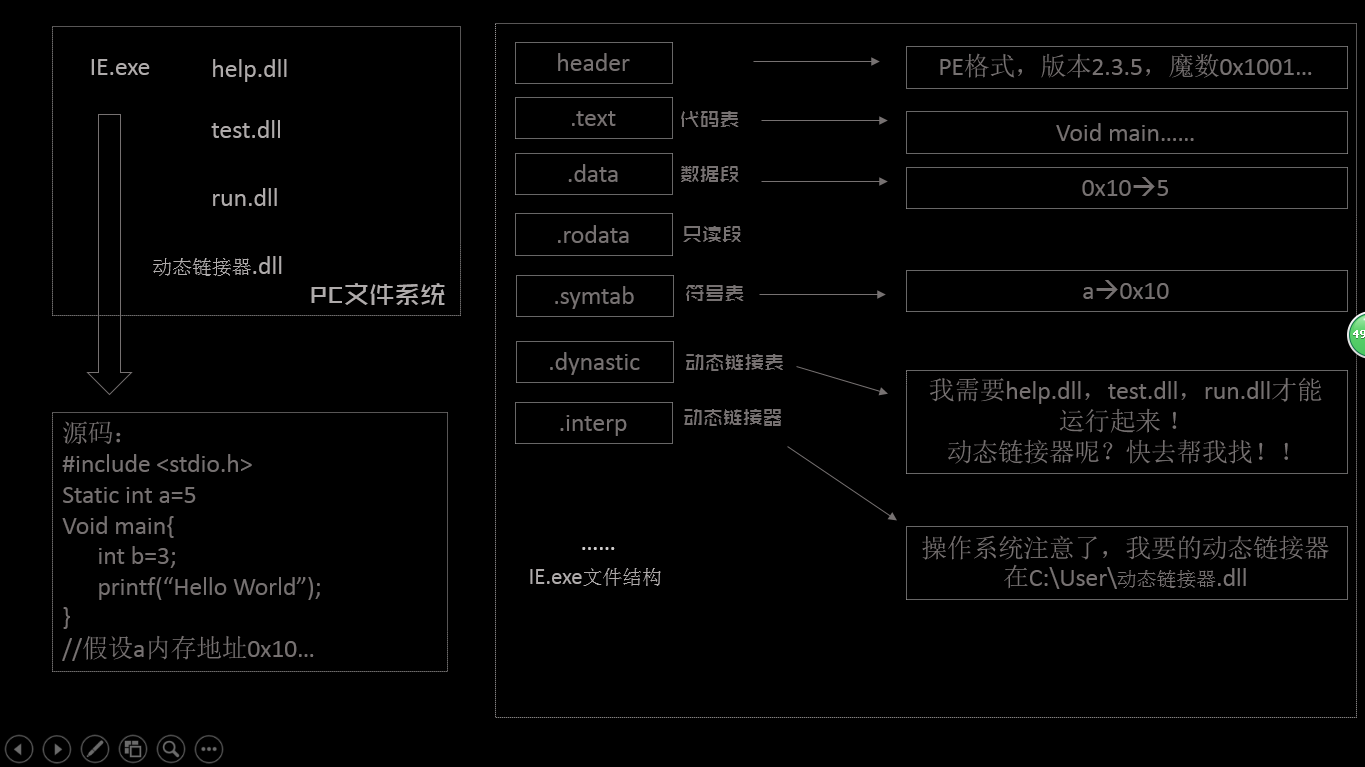
今天看到一個很有趣的程序,如下:
int main()
{
const int a = 1;
int *b = (int*)&a;
*b = 21;
printf("%d, %d", a, *b);
return 0;
}
當我第一眼看到這個程序的時候,我想當然的認為輸出結果是21, 21,但是我錯了
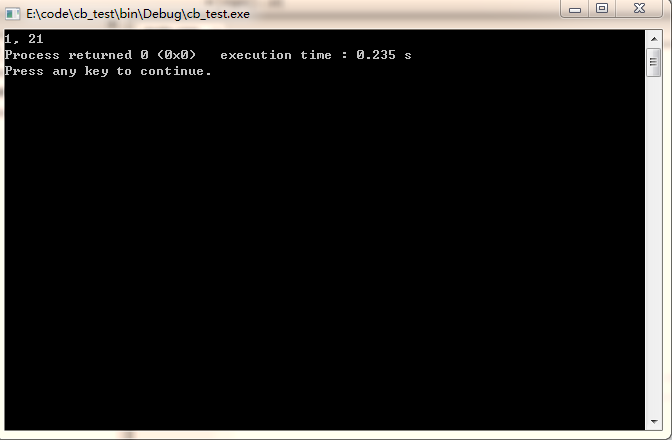
一時很難理解,於是我又輸出了它們的地址:
int main()
{
const int a = 1;
int *b = (int*)&a;
*b = 21;
printf("%d, %d", a, *b);
printf("\n%p, %p", &a, &*b);
return 0;
}
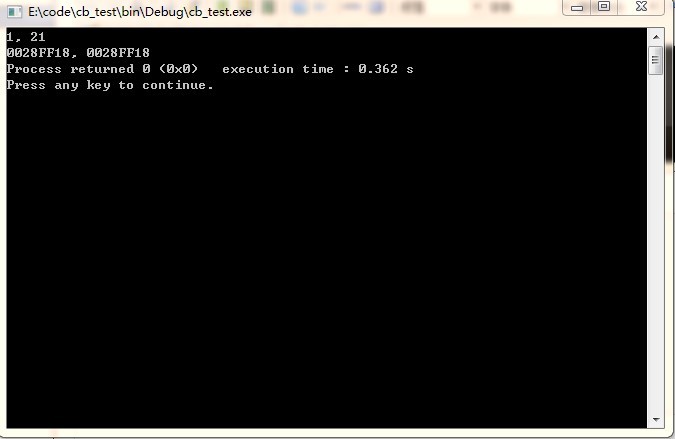
它們的地址是一樣的,看到這裡我更加的不解,於是我試著查看一下匯編代碼。
int main()
{
const int a = 1;
int *b = (int*)&a;
*b = 21;
printf("%d", a);
return 0;
}
對應匯編代碼如下:
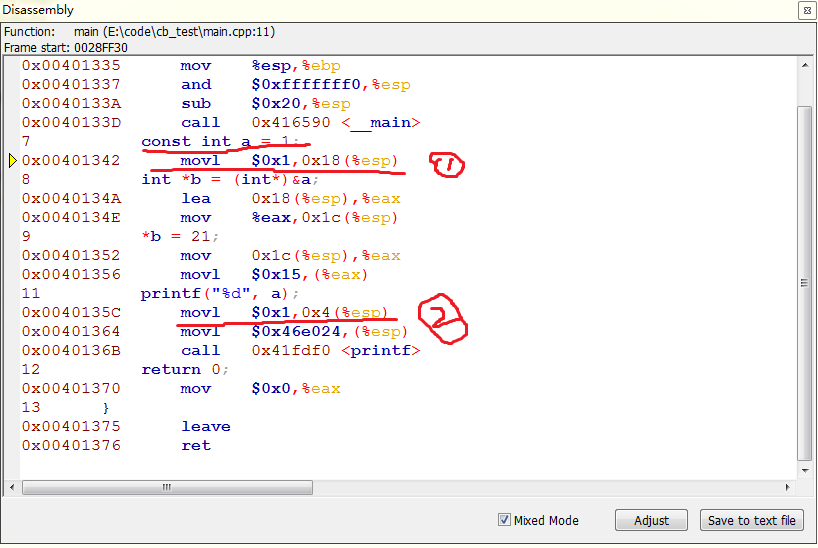
這裡得到的是at&t的匯編代碼,與intel不同之處在於:
1,指令格式為:指令名稱 元操作數 目的操作數
2,寄存器前加%
3,操作數前加$
4,0x4(%esp)為內存尋址,實際表示的是esp寄存器中的內容 + 4(如果不是很明白,望自行查找資料,本人知識有限)
我們首先看標號為1的行,對應c語句為const int a =1,這是把1放進地址為0x18(%esp)的地方,再來看標號2的地方,對應的printf語句,發現並沒有引用地址為0x18(%esp)的地方的值,而是把1直接放到了0x4(%esp),然後輸出。
所以個人認為,之所以會出現最開始的結果,是因為編譯器給我們做了一些優化導致的。為了證明我的觀點,我修改了程序:
int main()
{
int c = 1;
const int a = c;
int *b = (int*)&a;
*b = 21;
printf("%d, %d", a, *b);
return 0;
}
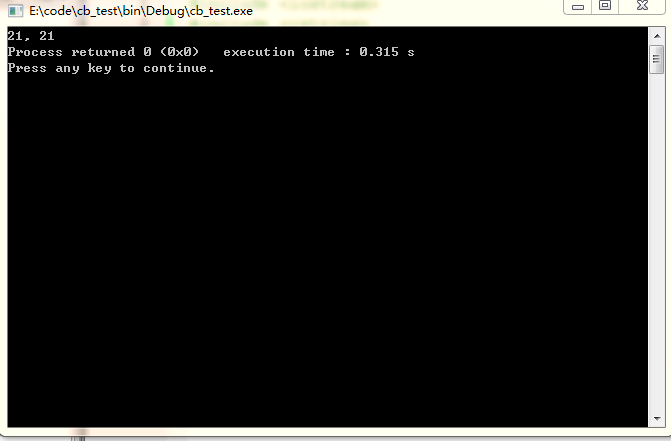
輸出結果為:
對應的匯編代碼為:
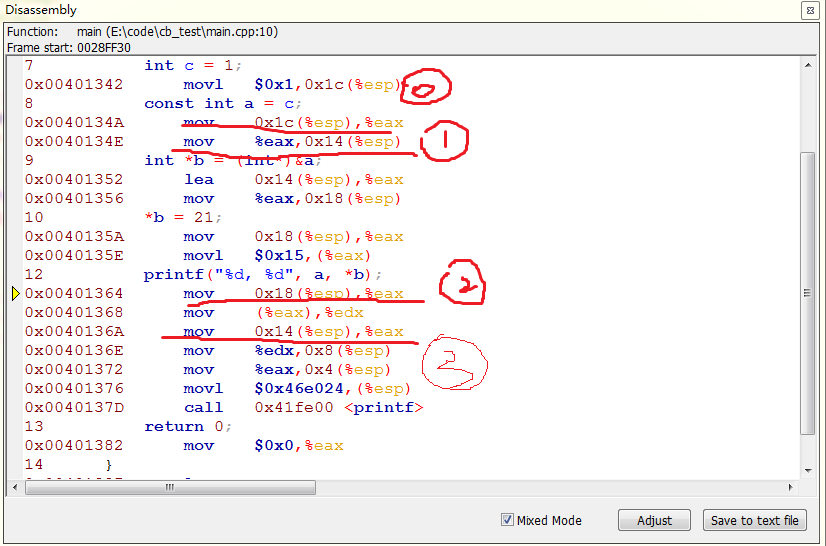
在標號1處,我們可以確定a存放在0x14(%esp)的地方,在標號2處,對應的printf語句,此語句從右向左處理參數,2處理的是*b,3處理的是a,這時看到用的是地址,而不是直接用數值,同時看標號0處,我們是將c賦值1,再給a賦值時編譯器用的是數值,並沒有引用地址。
所以,個人猜測,編譯器在這方面有一個優化功能:如果一個變量在定義時賦值常量,那麼在引用它的時候,編譯器會直接用該常量數值代替地址的引用來節省時間,但是也給我們帶來了以外的麻煩。
這些都是個人的觀點,希望各位指教!!!