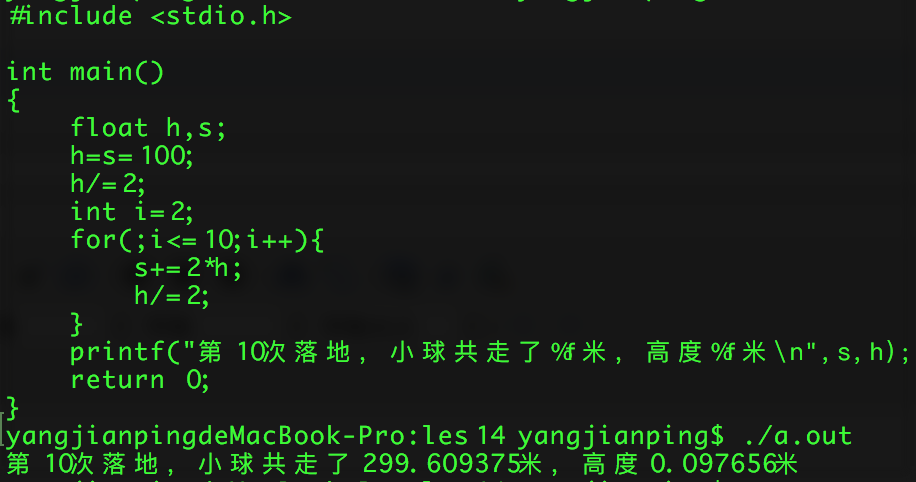
(1)什麼是字節對齊
一個變量占用 n 個字節,則該變量的起始地址必須能夠被 n 整除,即: 存放起始地址 % n = 0, 對於結構體而言,這個 n 取其成員種的數據類型占空間的值最大的那個。
(2)為什麼要字節對齊
內存空間是按照字節來劃分的,從理論上說對內存空間的訪問可以從任何地址開始,但是在實際上不同架構的CPU為了提高訪問內存的速度,就規定了對於某些類型的數據只能從特定的起始位置開始訪問。這樣就決定了各種數據類型只能按照相應的規則在內存空間中存放,而不能一個接一個的順序排列。
舉個例子,比如有些平台訪問內存地址都從偶數地址開始,對於一個int型(假設32位系統),如果從偶數地址開始的地方存放,這樣一個讀周期就可以讀出這個int數據,但是如果從奇數地址開始的地址存放,就需要兩個讀周期,並對兩次讀出的結果的高低字節進行拼湊才能得到這個int數據,這樣明顯降低了讀取的效率。
(3)如何進行字節對齊
每個成員按其類型的對齊參數(通常是這個類型的大小)和指定對齊參數(不指定則取默認值)中較小的一個對齊,並且結構的長度必須為所用過的所有對齊參數的整數倍,不夠就補空字節。
這個規則有點苦澀,可以把這個規則分解一下,前半句的意思先獲得對齊值後與指定對齊值進行比較,其中對齊值獲得方式如下:
1. 數據類型的自身對齊值為:對於char型數據,其自身對齊值為1,對於short型為2,對於int, long, float類型,其自身對齊值為4,對於 double 類型其自身對齊值為8,單位為字節。
2.結構體自身對齊值:其成員中自身對齊值最大的那個值。
其中指定對齊值獲得方式如下:
#pragma pack (value)時的指定對齊值value。
未指定則取默認值。
後半句的意思是主要是針對於結構體的長度而言,因為針對數據類型的成員,它僅有一個對齊參數,其本身的長度、於這個對齊參數,即1倍。對於結構體而言,它可能使用了多種數據類型,那麼這句話翻譯成對齊規則: 每個成員的起始地址 % 自身對齊值 = 0,如果不等於 0 則先補空字節直至這個表達式成立。
換句話說,對於結構體而言,結構體在在內存的存放順序用如下規則即可映射出來:
(一)每個成員的起始地址 % 每個成員的自身對齊值 = 0,如果不等於 0 則先補空字節直至這個表達式成立;
(二)結構體的長度必須為結構體的自身對齊值的整數倍,不夠就補空字節。
舉個例子:
#pragma pack(8)
struct A{
char a;
long b;
};
struct B{
char a;
struct A b;
long c;
};
struct C{
char a;
struct A b;
double c;
};
struct D{
char a;
struct A b;
double c;
int d;
};
struct E{
char a;
int b;
struct A c;
double d;
};
對於 struct A 來說,對於char型數據,其自身對齊值為1,對於long類型,其自身對齊值為4, 結構體的自身對齊值取其成員最大的對齊值,即大小4。那麼struct A 在內存中的順序步驟為:
(1) char a, 地址范圍為0x0000~0x0000,起始地址為0x0000,滿足 0x0000 % 1 = 0,這個成員字節對齊了。
(2) long b, 地址起始位置不能從0x00001開始,因為 0x0001 % 4 != 0, 所以先補空字節,直到0x00003結束,即補3個字節的空字節,從0x00004開始存放b,其地址范圍為0x00004~0x0007.
(3)此時成員都存放結束,結構體長度為8,為結構體自身對齊值的2倍,符合條件(二).
此時滿足條件(一)和條件(二),struct A 中各成員在內存中的位置為:a*** b ,sizeof(struct A) = 8。(每個星號代表一位,成員各自代表自己所占的位,比如a占一位,b占四位)
對於struct B,裡面有個類型為struct A的成員b自身對齊值為4,對於long類型,其自身對齊值為4. 故struct B的自身對齊值為4。那麼structB 在內存中的順序步驟為:
(1) char a, 地址范圍為0x0000~0x0000,起始地址為0x0000,滿足 0x0000 % 1 = 0,這個成員字節對齊了。
(2) struct A b, 地址起始位置不能從0x00001開始,因為 0x0001 % 4 != 0, 所以先補空字節,直到0x00003結束,即補3個字節的空字節,從0x00004開始存放b,其地址范圍為0x00004~0x00011.
(3) long c,地址起始位置從0x000012開始, 因為 0x0012 % 4 = 0,其地址范圍為0x00012~0x0015.
(4)此時成員都存放結束,結構體長度為16,為結構體自身對齊值的4倍,符合條件(二).
此時滿足條件(一)和條件(二),struct B 中各成員在內存中的位置為:a*** b c ,sizeof(struct C) = 24。(每個星號代表一位,成員各自代表自己所占的位,比如a占一位,b占八位,c占四位)
對於struct C,裡面有個類型為struct A的成員b自身對齊值為4,對於double 類型,其自身對齊值為8. 故struct C的自身對齊值為8。那麼struct C 在內存中的順序步驟為:
(1) char a, 地址范圍為0x0000~0x0000,起始地址為0x0000,滿足 0x0000 % 1 = 0,這個成員字節對齊了。
(2) struct A b, 地址起始位置不能從0x00001開始,因為 0x0001 % 4 != 0, 所以先補空字節,直到0x00003結束,即補3個字節的空字節,從0x00004開始存放b,其地址范圍為0x00004~0x00011.
(3) double c,地址起始位置不能從0x000012開始, 因為 0x0012 % 8 != 0,所以先補空字節,直到0x000015結束,即補4個字節的空字節,從0x00016開始存放c,其地址范圍為0x00016~0x0023.
(4)此時成員都存放結束,結構體長度為24,為結構體自身對齊值的3倍,符合條件(二).
此時滿足條件(一)和條件(二),struct C 中各成員在內存中的位置為:a*** b **** c ,sizeof(struct C) = 24。(每個星號代表一位,成員各自代表自己所占的位,比如a占一位,b占八位,c占八位)
對於struct D,自身對齊值為8。前面三個成員與 struct C 是一致的。對於第四成員d,因為 0x0024 % 4 = 0, 所以可以從0x0024開始存放d, 其地址范圍為0x00024~0x00027.此時成員都存放結束,結構體長度為28,28 不是結構體自身對齊值8的倍數,所以要在後面補四個空格,即在0x0028~0x0031上補四個空格。補完了,結構體長度為32, 為結構體自
身對齊值的4被,,符合條件(二).
此時滿足條件(一)和條件(二),struct D 中各成員在內存中的位置為:a*** b **** c d **** ,sizeof(struct D) = 32。(每個星號代表一位,成員各自代表自己所占的位,比如a占一位,b占八位,c占八位, d占四位)。
對於struct E 中各成員在內存中的位置為:a*** b c d, sizeof(struct E) = 24。(每個星號代表一位,成員各自代表自己所占的位,比如a占一位,b占四位,c占八位, d占八位)。
通過struct D 和 struct E 可以看出,在成員數量和類型一致的情況,後者的所占空間少於前者,因為後者的填充空字節要少。如果我們在編程時考慮節約空間的話,應該遵循將變量按照類型大小從小到大聲明的原則, 這樣盡量減少填補空間。另外,可以在填充空字節的地方來插入reserved成員, 例如
struct A
{
char a;
char reserved[3];
int b;
};
這樣做的目的主要是為了對程序員起一個提示作用,如果不加則編譯器會自動補齊。