今天的電子設備,不管是嵌入、工業、消費、娛樂,還是通訊電子設備,它們中的應用程序,都比過去需要在更短的時間內處理更多的數據。一般來說,開發者通常會選用某種通用型處理器或數字信號處理器(DSP),對那些適應性為先的應用程序來說,通用型處理器一直都是最佳的架構選擇,而同時DSP也是用於提高運算能力的首選。在許多情況中,既需要適應性,同時也需要強大的運算能力,當為了增加通用型處理器的執行能力而提高時鐘頻率時,也會帶來成本與電能消耗的增加。為滿足今日計算的要求,在這些設備中加入了硬件加速或某些特別的輔助部件,但由此付出的代價是增加了編程的復雜性。本文將探討通過C語言,怎樣加速程序處理速度,以可配置軟件架構的方式,達到硬件加速的目的,同時我將介紹一個硬件加速有限脈沖響應(FIR)轉換器的真實案例。
以軟件配置的處理器
大多數高性能IC產品的市場都在不斷地變動,追尋更先進的標准,及滿足永遠都在變化的系統需求。基於ASIC的架構,雖然提供了所需的性能,但卻不能快速及經濟地滿足這些變化著的應用規格,因此,許多開發者不得不轉向以軟件方式配置的架構,其可在應用型處理器中融入可編程邏輯。
以軟件配置的架構,其優勢在於,可編程的門電路可作為應用型處理器,有機地集成進同一流水線,而作為參考對比基於協處理器的架構,通常是使用FPGA或ASSP這樣單獨的系統部件來減輕系統負載的,這種使用協處理器的做法,帶來的是復雜的、應用上的分割,並且在應用型處理器等待結果時,造成延遲,或需實現復雜的調度機制。加之對FPGA的設計需要一個單獨的開發環境,和另一支開發隊伍,所帶來成本上的開銷也是非同一般的。
因為以軟件配置的處理器可作為應用型處理器,在同一流水線中實現了可編程邏輯,所以,編譯器可把算法分為硬件和軟件部分,由此也降低了相關的依賴性,其結果是,你可把"硬件"當成"軟件",並在單一開發環境中編寫代碼,使硬件和軟件更優化地一同工作。不需要花費巨大的開發資源來手工調校代碼,只需高亮標出運算熱點,編譯器就會以硬件的形式實現它。這些熱點區域作為擴展指令實現,應用型處理器可將其視為傳統的指令,並在同一流水線中執行。此處的差異在於,擴展指令可表現為成百上千條C指令,在單一時鐘周期內高效地執行和計算。
基本FIR轉換器
FIR轉換器可把熱點區域以並行的方式實現,在此,我們討論的重點是對一個轉換器,怎樣通過C的實現來硬件加速,這種優化的理念也可應用於其他算法。
可用以下方程式來描述一個FIR轉換器:
t=T-1
y(n)=SUM ((h(t)*x)(n-t)) for n=0,...N-1
t=0
x(n)在此是輸入信號,y(n)是輸出信號,h(t)是FIR轉換器系數,圖1為一個直觀的FIR函數示意圖,格子內的每一點,代表了系數h(t)與數據點x(n-t)的乘積,而每條斜線上的所有乘積全部相加才能得到輸出的y(n)。例1是對FIR轉換器一個直接用C語言的實現方法。利用此實現,一個使用T=64和N=80的64路轉換器執行完,將大約需要27230個時鐘周期。而這種固有的並行架構,使它成為一個非常適合於實際應用中硬件加速的候選方案。
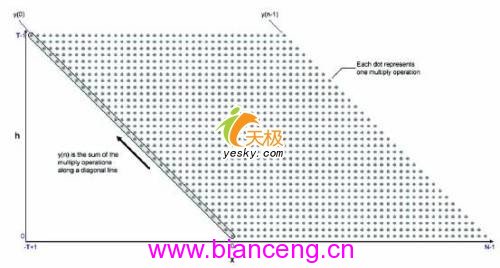
圖1:FIR函數示意圖
例1:
void fir(short *X, short *H, short *Y, int N, int T)
{
int n, t, acc;
short *x, *h;
/* 轉換器輸入 */
for (n = 0; n < N; n ) {
x = X;
h = H;
acc = (*x--) * (*h );
for(t = 1; t < T; t ) {
acc = (*x--) * (*h );
}
*Y = acc >> 14;
X ;
Y ;
}
}
加速的關鍵性考慮因素
當決定在算法中采用並行措施時,務必要留意架構上固有的一些特性:
總線位寬:數據怎樣在CPU和其他部件之間傳遞,對整體效率和吞吐量都有著重大的影響,因為總線決定了數據可被多快地傳遞,輸入與輸出都會受到其影響。位寬太窄或速度太慢,都會成為一個處理上的瓶頸,從而影響擴展指令的執行效率,但如果總線不能被及時地填充數據以充分利用,那麼不管擴展指令多有效率,都是無用的。
一般而言,總線的頻率決定了擴展指令發出的頻密度,而位寬則決定了擴展指令一次能處理多少數據。注意,某些架構提供了CPU與各部件之間的多重總線,由此來進行硬件加速,例如Stretch公司的S5以軟件配置的處理器,在應用處理器與可編程部件之間,就有三個讀取與兩個寫入端口,每個均為128位的位寬,並提供每條擴展指令最大讀取384位及寫入256位的能力。有效地利用這些總線,開發出高效的並行機制並不是件難事。
在帶寬計算上,要保證帶寬可把結果傳回至主CPU並同時處理中間結果,這一點尤其重要。
狀態寄存器:為一個復雜算法加速,通常會把算法進行分割,以便用於加速的硬件在每一次迭代中只計算結果的某一部分。因為轉換器是作為一個部分函數執行,也就是說,總體結果中只有一些離散的段是通過擴展指令執行的,而且,經常會有一些中間結果需要傳遞給下一個函數的調用,例如,在FIR函數最初的C實現中,一個連續的總數或中間結果必須在主算法循環的每一次迭代中都保留。再者,當應用更先進的優化技術時,中間結果的數量也會逐步增加。
為達到加速的目的,必須在每次迭代之間防止產生這些中間結果,因為這些值經常會通過數據總線傳回到主CPU,而CPU又會把它們返回給函數,以便進行下一次迭代。此過程不僅消耗有限的總線帶寬,而且也浪費了寶貴的CPU時鐘周期,降低了整體處理的效率。
為保證效率,在此可使用狀態寄存器。狀態寄存器提供了一種機制,其可存儲函數迭代的中間結果,而又不會涉及到主CPU或在總線上傳遞數據,因此,利用狀態寄存器,可使整體的並行機制變得更有效率,而可用的狀態寄存器數目,又進一步決定了在算法中可多大程度地利用這類並行機制。 數據大小:許多的架構在有關某數據類型占用的位寬方面,只提供了一個有限的子集,例如,一個布爾變量通常只需要一比特位,但在實現中,大小經常至少是一個字節,而一般對CPU來說,這樣做會提高效率,因為對一個比特位進行掩碼操作所花的代價及性能上的影響,遠遠要比浪費7個比特位更多;當傳遞數據給擴展指令,而此時CPU又必須立即剝離和打包這些比特位時,就會損失一部分效率。另外,為節約可編程邏輯資源,寄存器必須能被定義以消除未使用的位。最後,如果未使用的位可在被傳遞到總線之前就消除,那麼總線帶寬還是可以充分利用的。理想中的情況是,這些問題應在可編程邏輯之內處理,因為來自CPU所需的操作降低了整體的速率,而此時,CPU通常是可發出擴展指令的。
並行計算
對FIR轉換器硬件實現進行優化的第一步,是決定總線可高效地傳給加速硬件的數據點數量。通過一個高速的寬帶總線,可同時傳輸多個數值,例如,一個執行8次乘法和加法(MAC)的擴展指令,將以8為系數減少內部循環迭代的次數,每個流水線擴展指令可在單一周期內高效地執行,因此,整體性能將提高大約8倍。請注意,如果某一特殊的數據集不能被8整除,那麼數據集將會被填充零直至為8的倍數,因此,就不一定需要特殊的末端循環指令了。
數據相乘的方法如圖2所示,以高亮表示的數據點區域代表了單一擴展指令執行的運算,在擴展指令每次執行時,它都通過適當的系數乘以8個數據,並把乘積累加起來。產生的部分和將存儲在局部狀態變量中,隨後的指令便把這些部分和相加,由此便可消除把部分和傳回給CPU,隨後再傳給擴展指令這個過程。
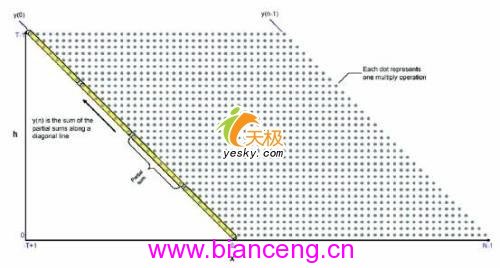
圖2:數據相乘的方法
每條擴展指令執行8次MAC,可把執行范例FIR轉換器所需的理論最小周期數降低到1941,與直接用C實現的方法相比,性能上可提高15倍。
可同時運算的最優數量,依賴於可用的可編程資源數量,因為這些資源是在CPU當前訪問的各種擴展指令之間共享的,所以,合理地節約使用可編程資源,對最大化提高系統整體性能來說,就顯得極其重要,只要可能,就要盡量復用這些資源。
復用的效率可通過使用兩條擴展指令來作一演示,分別是FIR_MUL和FIR_MAC(見例2)。
例2:
#include <stretch.h>
static se_sint<32> acc;
/* 執行8路並行MAC */
SE_FUNC void
firFunc(SE_INST FIR_MUL, SE_INST FIR_MAC, WR X, WR H, WR *Y)
{
se_sint<16>x, h
se_sint<32> sum ;
int i ;
sum = 0;
for(i = 0; i < 128; i = 16) {
h = H(i 15, i);
x = X(127-i, 112-i);
sum = x * h ;
}
acc = FIR_MUL ? sum : se_sint<32>(sum acc) ;
*Y = acc >> 14 ;
}
在FIR轉換器第一次調用時,部分和狀態需要重設,這通常由FIR_MUL處理。在64路轉換器的情況中,將有7個並發的迭代調用FIR_MAC,它們都將使用先前已有的部分和。FIR_MUL與FIR_MAC的主要不同之處在於下面這一行代碼:
acc = FIR_MUL ? sum : se_int<32>(sum acc)
如果擴展指令通過FIR_MUL被調用,上述代碼將有效地重設部分和,如果通過FIR_MAC調用,將直接使用部分和。
這種實現的好處就是復用了分配給剩余函數的可編程邏輯,同一可編程資源能被共享,就不需要為了這兩條擴展指令,而增加可用資源了。合理地使用這些資源,並有選擇性地解決與之相關的延遲,在這種情況下,就不會對性能產生實質性的影響,因而,就有更多的資源可用於實現其他擴展指令或進一步優化當前指令。
好事不怕多
如果要更進一步地優化,就要增加在每條擴展指令執行時處理的數據點數量,因為集成了可編程邏輯,才讓靈活的實現變成了可能,所以不需重新設計,就可對擴展指令加以修訂,提高執行效率。相比之下,基於ASIC或FPGA的架構就需要徹底改造、調整,並調試修改過的功能。ASIC與FPGA的設計源於獨立且明顯不同的開發環境,通常需要硬件方面的專門技術,並由第二個開發團隊來協助工作,因此,為實現硬件加速而進行的修改或重分配,在結果未被准確評估之前,會遇到人們心理上的抵抗。
當把硬件分離出作為軟件時,生成程序代碼的同一編譯器也能為可編程邏輯生成相應的配置。這樣,編譯器也能有效地管理資源和依賴性,並使性能達到最優化。另外,因為硬件的實現是由編譯器自動生成的,所以只需一個開發團隊就行了,這不但降低了把設計移交給另一個團隊時的復雜性,而且在不需要投入更多開發時間進行人工優化的前提下,給予了充分的自由來測試和評估多種實現。
舉例來說,FIR轉換器就可通過減少調用擴展指令的次數,來進一步地優化,不但減少了調度擴展指令的麻煩,也減少了調用擴展指令時系統整體的開銷。
如果把並行MAC的數目增加到16,性能上會有多大提高呢?圖3中,需計算一個4×4的數據區域,而計算這些數據點,至少對一個FIR轉換器來說,需要4個系數與7個數據點,與16個系數與16個數據點的實現相比,後者從單一的斜行中就可計算出部分和,這提高了總線帶寬的利用率,其使用更少的帶寬,卻可執行更多的計算,這是通過把4個部分和存儲在狀態寄存器中,以便擴展指令下一次迭代時使用來達到的。最優化性能,其實就是在優化使用可編程資源之間取得一個平衡。
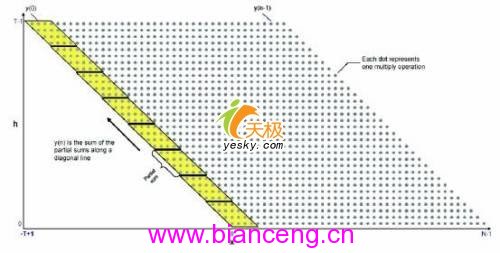
圖3:一個4×4的數據點區域
每條擴展指令可執行16-MAC,在性能上可比8-MAC的實現提高一倍,所需時鐘周期減少至981,對未實現加速的版本來說,性能上提高了30倍。如果要更進一步地提高性能,可能要分配更多的可編程資源以執行32-MAC(見圖4)。在這種配置下,擴展指令需要4個系數與11個數據樣本,從一條指令到下一條指令,期間需保存8個部分和。關於此實現所需的時鐘周期,理論上最小值為501,相對於直接用C的實現,效率大約提高了58倍。
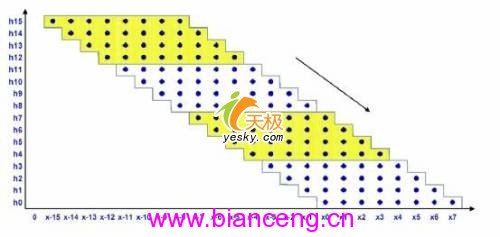
圖4:分配更多的可編程資源以執行32-MAC
循環優化
雖然增加並行運算的數量,是提高性能最有效的方法,但通過常規的循環優化,也能對性能達到實質性的改進。舉例說明,請看下例可同時執行8次運算的FIR轉換器實現(參見例3),之所以選擇這個例子,是因為相對於可同時執行32次運算的例子,它更能保持內部代碼簡潔,以便更好地演示優化的技巧。
例3:
#include "fir8.h"
#define ST_DECR 1
#define ST_INCR 0
void fir(short *X, short *H, short *Y, short N, short T)
{
int n, t, t8;
WR x, h, y;
t8 = T/8;
WRPUTINIT(ST_INCR, Y) ;
for (n = 0; n < N; n ) {
WRGET0INIT(ST_INCR, H) ;
X ;
WRGET1INIT(ST_DECR, X) ;
WRGET0I( &h, 16 );
WRGET1I( &x, 16);
FIR_MUL(x, h, &y);
for (t = 1; t < t8; t ) {
WRGET0I(&h, 16);
WRGET1I(&x, 16);
FIR_MAC(x, h, &y);
}
WRPUTI(y, 2) ;
}
WRPUTFLUSH0() ;
WRPUTFLUSH1() ;
}
在這個實現中,擴展指令的使用,對函數fir()的性能,有極大的改善,可從27230個時鐘周期降低到5065個時鐘周期,而且無需低級匯編代碼或對原始C語言算法結構進行較大的修改,然而,仍有浪費掉的時鐘周期存在,所以此實現還是不夠高效。為特定外部循環迭代而調用最後的FIR_MAC指令之後,處理器在取得結果之前,必須等待與擴展指令延遲相等的一定周期數,浪費掉的周期就由此而產生。
一種彌補的方法是,當在等待前一輪循環輸出時,即刻開始下一輪循環的運算。因為完全發送擴展指令所需的處理器周期數,要遠遠大於等待結果所需的周期數,因此,完全可保證在當前例子發出第一條擴展指令時,處理器已可以使用前一個例子的輸出了。
在循環迭代之間,也有進行優化的可能。某一特定外部循環迭代中的內部循環運算,是不依賴於前面或後面外部循環的結果的,如果此時可發出一條新的外部循環迭代,在某種程度上可補償等待結果的延遲。可以設想這樣一種情況,對0層外部循環迭代最後一條FIR_MAC發出後,CPU可即刻開始對1層外部循環迭代中的內部循環進行運算,而不必等待0層外部循環迭代完成後所發出的擴展指令。在此實現中,最後一條FIR_MAC在給出結果之前,將大概需要21個處理器周期。照這樣,如果把外部循環中的內部循環運算進行流水線操作,極有可能把每次迭代所需處理器周期降低至18,當然這是除最後一個外部循環迭代之外,因為此時已沒有更多的運算量可利用周期了。假定這種情況只會在每次fir()調用時發生一次,那麼系統開銷幾乎可以忽略不計。
基於此技巧的實現(例4),已把每次調用所需的總周期數,從5065減少到3189。這樣,對現有代碼無需作更多的修改,就能帶來超過8倍的性能提升。
例4:
/* 包含特定的擴展指令頭文件 */
#include "fir8.h"
#define ST_DECR 1 /* 減量指示器 */
#define ST_INCR 0 /* 增量指示器 */
/* 為FIR ISEF 指令調用定義宏 */
#define FIR(H, X, h, x, t8, y)
{
int t8m1 = (t8)-1;
WRGET0INIT(ST_INCR, (H)) ;
(X) ;
WRGET1INIT(ST_DECR, (X)) ;
WRGET0I( &(h), 8 * sizeof(short) );
WRGET1I( &(x), 8 * sizeof(short) );
FIR_MUL( (x), (h), &(y) );
for (t = 1; t < (t8m1); t )
{
WRGET0I( &(h), 16 );
WRGET1I( &(x), 16 );
FIR_MAC( (x), (h), &(y) );
}
WRGET0I( &(h), 16 );
WRGET1I( &(x), 16 );
FIR_MAC( (x), (h), &(y) );
}
/*
* - 在ISEF中,FIR使用8倍乘法循環優化
*/
void fir(short *X, short *H, short *Y, short N, short T)
{
int n, t, t8 ;
WR x, h, y1, y2, y3, y4;
t8 = T/8 ;
WRPUTINIT(ST_INCR, Y) ; /* 起始輸出流 */
FIR (H, X, h, x, t8, y1) ; /* x * h y => y1 */
/* loop ((N/2)-1) times */
n = 0;
do
{
FIR (H, X, h, x, t8, y2) ; /* x * h y => y2 */
WRPUTI(y1, 2) ; /* 輸出(y1)結果 */
FIR (H, X, h, x, t8, y1) ; /* x * h y => y1 */
WRPUTI(y2, 2) ; /* 輸出(y2)結果 */
} while ( n < ((N>>1)-1) );
FIR (H, X, h, x, t8, y2) ; /* x * h y => y2 */
WRPUTI(y1, 2) ; /* 輸出(y1)結果 */
WRPUTI(y2, 2) ; /* 輸出(y2)結果 */
WRPUTFLUSH0() ; /* 清除輸出流 */
WRPUTFLUSH1() ; /* 清除輸出新 */
}
另一個提升性能的技巧是手工解開內部循環。因為內部循環是通過使用一個變量來管理的,而FIR宏又是為通用目的編寫的,所以,編譯器不能預測到循環將執行的次數,也就是完全取決於內部循環本身。然而,這些條件又反過來影響擴展指令的調度,因為它們將清除(flush)處理器流水線,而處理器又錯過了可發出一條擴展指令的周期,延遲就這樣產生了。
循環解開優化的實現(例5),意味著只需少許努力,就可大幅提升性能,每次調用所需周期減少至2711,整體系統提升10倍。如果在使用32-MAC擴展指令時,一起使用上述技巧,函數可在687個周期內執行完畢,相對於最初直接用C代碼,性能提升超過39倍(見表1)。
例5:
/*包含特定的擴展指令頭文件*/
#include "fir8.h"
#define ST_DECR 1 /* 減量指示器 */
#define ST_INCR 0 /* 增量指示器 */
#define FIR(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, X)
{
WRGET0I( &(h1), 8 * sizeof(short) );
WRGET1I( &(x1), 16 );
X ;
WRGET0I( &(h2), 16 );
WRGET1I( &(x2), 16 );
FIR_MUL( (x1), (h1), &(y1) );
WRGET0I( &(h3), 16 );
WRGET1I( &(x1), 16 );
FIR_MAC( (x2), (h2), &(y1) );
WRGET0I( &(h4), 16 );
WRGET1I( &(x2), 16 );
FIR_MAC( (x1), (h3), &(y1) );
WRGET0I( &(h5), 16 );
WRGET1I( &(x1), 16 );
FIR_MAC( (x2), (h4), &(y1) );
WRGET0I( &(h6), 16 );
WRGET1I( &(x2), 16 );
FIR_MAC( (x1), (h5), &(y1) );
WRGET0I( &(h7), 16 );
WRGET1I( &(x1), 16 );
FIR_MAC( (x2), (h6), &(y1) );
WRGET0I( &(h8), 16 );
WRGET1I( &(x2), 16 );
FIR_MAC( (x1), (h7), &(y1) );
WRGET1INIT(ST_DECR, X);
FIR_MAC( (x2), (h8), &(y1) );
}
#define FIR1(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X)
{
WRGET1I( &(x1), 16 );
FIR_MUL( (x1), (h1), &(y2) );
WRGET1I( &(x1), 16 );
FIR_MAC( (x1), (h2), &(y2) );
WRGET1I( &(x1), 16 );
FIR_MAC( (x1), (h3), &(y2) );
WRGET1I( &(x1), 16 );
FIR_MAC( (x1), (h4), &(y2) );
WRGET1I( &(x1), 16 );
X ;
FIR_MAC( (x1), (h5), &(y2) );
WRGET1I( &(x1), 16 );
WRGET1I( &(x2), 16 );
FIR_MAC( (x1), (h6), &(y2) );
WRGET1I( &(x1), 16 );
WRGET1INIT0(ST_DECR, X);
FIR_MAC( (x2), (h7), &(y2) );
WRGET1INIT1();
WRPUTI(y1, 2);
FIR_MAC( (x1), (h8), &(y2) );
}
#define FIR2(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X)
{
WRGET1I( &(x1), 16 );
FIR_MUL( (x1), (h1), &(y1) );
WRGET1I( &(x1), 16 );
FIR_MAC( (x1), (h2), &(y1) );
WRGET1I( &(x1), 16 );
FIR_MAC( (x1), (h3), &(y1) );
WRGET1I( &(x1), 16 );
FIR_MAC( (x1), (h4), &(y1) );
WRGET1I( &(x1), 16 );
X ;
FIR_MAC( (x1), (h5), &(y1) );
WRGET1I( &(x1), 16 );
WRGET1I( &(x2), 16 );
FIR_MAC( (x1), (h6), &(y1) );
WRGET1I( &(x1), 16 );
WRGET1INIT0(ST_DECR, X) ;
FIR_MAC( (x2), (h7), &(y1) );
WRGET1INIT1();
WRPUTI(y2, 2);
FIR_MAC( (x1), (h8), &(y1) );
}
/*
* -在ISEF中,FIR使用8倍乘法循環優化 / 手工展開
*/
void fir(short *X, short *H, short *Y, short N, short T)
{
int n, t, t8 ;
WR h1, h2, h3, h4, h5, h6, h7, h8 ;
WR x1, x2;
WR y1;
WR y2;
// (these alternative "register" declarations make no difference:)
// register WR y1 SE_REG("wra1") ;
// register WR y2 SE_REG("wra2") ;
WRPUTINIT(ST_INCR, Y); /* 起始輸出流 */
WRGET0INIT(ST_INCR, H); /* 起始系數流 */
X ;
WRGET1INIT(ST_DECR, X); /* 起始輸入流 */
/* compute Y[0] in y1 */
FIR(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, X) ;
/* loop ((N/2)-1) times */
for (n = 0; n < ((N>>1)-1); n )
{
/* FIR1 輸出前一個(y1)的結果,並計算當前(y2)的結果 */
FIR1(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) ;
/* FIR1 輸出前一個(y2)的結果,並計算當前(y1)的結果 */
FIR2(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) ;
}
/* 在y2中計算Y[N-1],並從y1中輸出Y[N-2] */
FIR1(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) ;
WRPUTI(y2, 2) ; /* 輸出U[N-1] */
WRPUTFLUSH0() ; /* 清除輸出流 */
WRPUTFLUSH1() ; /* 清除輸出流 */
}
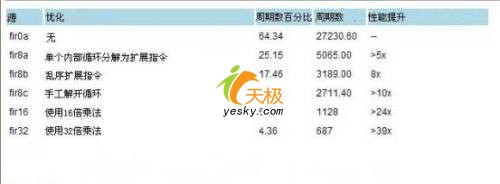
表1:
通過在應用型處理器和流水線中集成可編程邏輯,以軟件方式配置的架構,只需少許手工優化,在運算密集的算法中,也能提供實質上硬件加速的效果。正是因為可把"硬件設計成軟件",開發者現在能避免在硬件與軟件之間,由於算法分割上的實現,而帶來的復雜性了,並且編譯器處理了實際硬件實現上的復雜性,開發者現在能快速、輕松地設計更復雜的算法,評估各種實現的效率,以最大化地提升性能及控制成本。