二分圖是一個無向圖,它的n個頂點可二分為集合A和集合B,且同一集合中的任意兩個頂點在圖中無邊相連(即任何一條邊都是一個頂點在集合A中,另一個在集合B中)。當且僅當B中的每個頂點至少與A中一個頂點相連時,A的一個子集A' 覆蓋集合B(或簡單地說,A' 是一個覆蓋)。覆蓋A' 的大小即為A' 中的頂點數目。當且僅當A' 是覆蓋B的子集中最小的時,A' 為最小覆蓋。
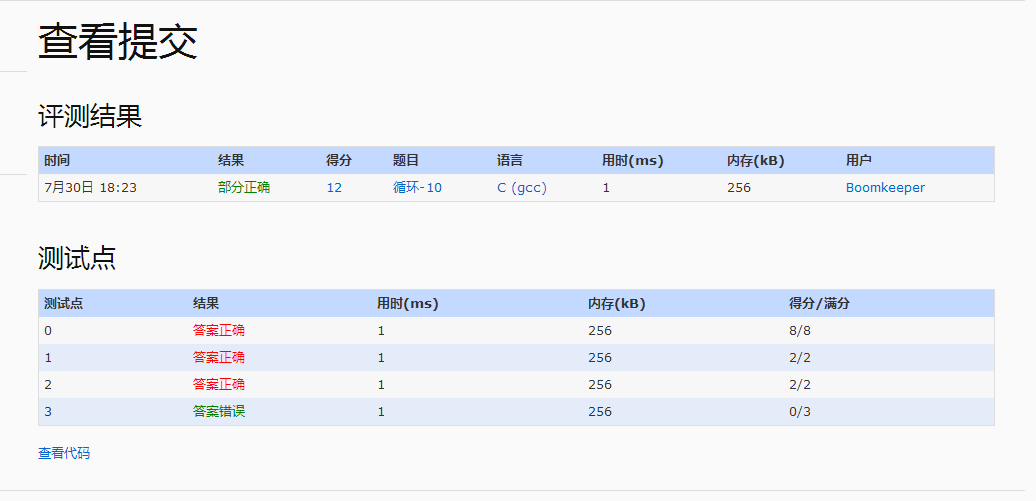
例1-10 考察如圖1 - 6所示的具有1 7個頂點的二分圖,A={1, 2, 3, 16, 17}和B={4, 5, 6, 7, 8, 9,10, 11, 12, 13, 14, 15},子集A'={ 1 , 1 6 , 1 7 }是B的最小覆蓋。在二分圖中尋找最小覆蓋的問題為二分覆蓋( b i p a r t i t e - c o v e r)問題。在例1 2 - 3中說明了最小覆蓋是很有用的,因為它能解決“在會議中使用最少的翻譯人員進行翻譯”這一類的問題。
二分覆蓋問題類似於集合覆蓋( s e t - c o v e r)問題。在集合覆蓋問題中給出了k個集合S={S1 , S2 ,., Sk },每個集合Si 中的元素均是全集U中的成員。當且僅當èi S'Si=U時,S的子集S' 覆蓋U,S '中的集合數目即為覆蓋的大小。當且僅當沒有能覆蓋U的更小的集合時,稱S' 為最小覆蓋。可以將集合覆蓋問題轉化為二分覆蓋問題(反之亦然),即用A的頂點來表示S1 , ., Sk ,B中的頂點代表U中的元素。當且僅當S的相應集合中包含U中的對應元素時,在A與B的頂點之間存在一條邊。
例1 - 11 令S={S1,...,S5 }, U={ 4,5,...,15}, S1={ 4,6,7,8,9,1 3 },S2={ 4,5,6,8 },S3={ 8,1 0,1 2,1 4,1 5 },S4={ 5,6,8,1 2,1 4,1 5 },S5={ 4,9,1 0,11 }。S '={S1,S4,S5 }是一個大小為3的覆蓋,沒有更小的覆蓋,S' 即為最小覆蓋。這個集合覆蓋問題可映射為圖1-6的二分圖,即用頂點1,2,3,1 6和1 7分別表示集合S1,S2,S3,S4 和S5,頂點j 表示集合中的元素j,4≤j≤1 5。
集合覆蓋問題為N P-復雜問題。由於集合覆蓋與二分覆蓋是同一類問題,二分覆蓋問題也是N P-復雜問題。因此可能無法找到一個快速的算法來解決它,但是可以利用貪婪算法尋找一種快速啟發式方法。一種可能是分步建立覆蓋A' ,每一步選擇A中的一個頂點加入覆蓋。頂點的選擇利用貪婪准則:從A中選取能覆蓋B中還未被覆蓋的元素數目最多的頂點。
例1-12 考察圖1 - 6所示的二分圖,初始化A'=且B中沒有頂點被覆蓋,頂點1和1 6均能覆蓋B中的六個頂點,頂點3覆蓋五個,頂點2和1 7分別覆蓋四個。因此,在第一步往A' 中加入頂點1或1 6,若加入頂點1 6,則它覆蓋的頂點為{ 5 , 6 , 8 , 1 2 , 1 4 , 1 5 },未覆蓋的頂點為{ 4 , 7 , 9 , 1 0 , 11 , 1 3 }。頂點1能覆蓋其中四個頂點( { 4 , 7 , 9 , 1 3 }),頂點2 覆蓋一個( { 4 } ),頂點3覆蓋一個({ 1 0 }),頂點1 6覆蓋零個,頂點1 7覆蓋四個{ 4 , 9 , 1 0 , 11 }。下一步可選擇1或1 7加入A' 。若選擇頂點1,則頂點{ 1 0 , 11} 仍然未被覆蓋,此時頂點1,2,1 6不覆蓋其中任意一個,頂點3覆蓋一個,頂點1 7覆蓋兩個,因此選擇頂點1 7,至此所有頂點已被覆蓋,得A'={ 1 6 , 1 , 1 7 }。
圖1 - 7給出了貪婪覆蓋啟發式方法的偽代碼,可以證明: 1) 當且僅當初始的二分圖沒有覆蓋時,算法找不到覆蓋;2) 啟發式方法可能找不到二分圖的最小覆蓋。
1.數據結構的選取及復雜性分析
為實現圖13 - 7的算法,需要選擇A' 的描述方法及考慮如何記錄A中節點所能覆蓋的B中未覆蓋節點的數目。由於對集合A' 僅使用加法運算,則可用一維整型數組C來描述A ',用m 來記錄A' 中元素個數。將A' 中的成員記錄在C[ 0 :m-1] 中。對於A中頂點i,令N e wi 為i 所能覆蓋的B中未覆蓋的頂點數目。逐步選擇N e wi 值最大的頂點。由於一些原來未被覆蓋的頂點現在被覆蓋了,因此還要修改各N e wi 值。在這種更新中,檢查B中最近一次被V覆蓋的頂點,令j 為這樣的一個頂點,則A中所有覆蓋j 的頂點的N e wi 值均減1。
例1-13 考察圖1 - 6,初始時(N e w1 , N e w2 , N e w3 , N e w16 , N e w17 )=( 6 , 4 , 5 , 6 , 4 )。假設在例1 - 1 2中,第一步選擇頂點1 6,為更新N e wi 的值檢查B中所有最近被覆蓋的頂點,這些頂點為5 , 6 , 8 , 1 2 , 1 4和1 5。當檢查頂點5時,將頂點2和1 6的N e wi 值分別減1,因為頂點5不再是被頂點2和1 6覆蓋的未覆蓋節點;當檢查頂點6時,頂點1 , 2 ,和1 6的相應值分別減1;同樣,檢查頂點8時,1,2,3和1 6的值分別減1;當檢查完所有最近被覆蓋的頂點,得到的N e wi 值為(4,1,0,4)。下一步選擇頂點1,最新被覆蓋的頂點為4,7,9和1 3;檢查頂點4時,N e w1 , N e w2, 和N e w1 7 的值減1;檢查頂點7時,N e w1 的值減1,因為頂點1是覆蓋7的唯一頂點。
為了實現頂點選取的過程,需要知道N e wi 的值及已被覆蓋的頂點。可利用一個二維數組來達到這個目的,N e w是一個整型數組,New[i] 即等於N e wi,且c o v為一個布爾數組。若頂點i未被覆蓋則c o v [ i ]等於f a l s e,否則c o v [ i ]為t r u e。現將圖1 - 7的偽代碼進行細化得到圖1 - 8。
m=0; //當前覆蓋的大小
對於A中的所有i,New[i]=Degree[i]
對於B中的所有i,C o v [ i ]=f a l s e
while (對於A中的某些i,New[i]>0) {
設v是具有最大的N e w [ i ]的頂點;
C [ m + + ]=v ;
for ( 所有鄰接於v的頂點j) {
if (!Cov[j]) {
Cov[j]=true;
對於所有鄰接於j的頂點,使其N e w [ k ]減1
} } }
if (有些頂點未被覆蓋) 失敗
else 找到一個覆蓋
圖1-8 圖1-7的細化
更新N e w的時間為O (e),其中e 為二分圖中邊的數目。若使用鄰接矩陣,則需花(n2 ) 的時間來尋找圖中的邊,若用鄰接鏈表,則需(n+e) 的時間。實際更新時間根據描述方法的不同為O (n2 ) 或O (n+e)。逐步選擇頂點所需時間為(S i z e O f A),其中S i z e O f A=| A |。因為A的所有頂點都有可能被選擇,因此所需步驟數為O ( S i z e O f A ),覆蓋算法總的復雜性為O ( S i z e O f A 2+n2)=O ( n2)或O (S i z e Of A2+n + e)。
2.降低復雜性
通過使用有序數組N e wi、最大堆或最大選擇樹(max selection tree)可將每步選取頂點v的復雜性降為( 1 )。但利用有序數組,在每步的最後需對N e wi 值進行重新排序。若使用箱子排序,則這種排序所需時間為(S i z e O f B ) ( S i z e O fB=|B| ) (見3 .8 .1節箱子排序)。由於一般S i z e O f B比S i z e O f A大得多,因此有序數組並不總能提高性能。
如果利用最大堆,則每一步都需要重建堆來記錄N e w值的變化,可以在每次N e w值減1時進行重建。這種減法操作可引起被減的N e w值最多在堆中向下移一層,因此這種重建對於每次N e w值減1需( 1 )的時間,總共的減操作數目為O (e)。因此在算法的所有步驟中,維持最大堆僅需O (e)的時間,因而利用最大堆時覆蓋算法的總復雜性為O (n2 )或O (n+e)。
若利用最大選擇樹,每次更新N e w值時需要重建選擇樹,所需時間為(log S i z e O f A)。重建的最好時機是在每步結束時,而不是在每次N e w值減1時,需要重建的次數為O (e),因此總的重建時間為O (e log S i z e OfA),這個時間比最大堆的重建時間長一些。然而,通過維持具有相同N e w值的頂點箱子,也可獲得和利用最大堆時相同的時間限制。由於N e w的取值范圍為0到S i z e O f B,需要S i z e O f B+ 1個箱子,箱子i 是一個雙向鏈表,鏈接所有N e w值為i 的頂點。在某一步結束時,假如N e w [ 6 ]從1 2變到4,則需要將它從第1 2個箱子移到第4個箱子。利用模擬指針及一個節點數組n o d e(其中n o d e [ i ]代表頂點i,n o d e [ i ] .l e f t和n o d e [ i ] .r i g h t為雙向鏈表指針),可將頂點6從第1 2個箱子移到第4個箱子,從第1 2個箱子中刪除n o d e [ 0 ]並將其插入第4個箱子。利用這種箱子模式,可得覆蓋啟發式算法的復雜性為O (n2 )或O(n+e)。(取決於利用鄰接矩陣還是線性表來描述圖)。
3.雙向鏈接箱子的實現
為了實現上述雙向鏈接箱子,圖1 - 9定義了類U n d i r e c t e d的私有成員。N o d e Ty p e是一個具有私有整型成員l e f t和r i g h t的類,它的數據類型是雙向鏈表節點,程序1 3 - 3給出了U n d i r e c t e d的私有成員的代碼。
void CreateBins (int b, int n)
創建b個空箱子和n個節點
void DestroyBins() { delete [] node;
delete [] bin;}
void InsertBins(int b, int v)
在箱子b中添加頂點v
void MoveBins(int bMax, int ToBin, int v)
從當前箱子中移動頂點v到箱子To B i n
int *bin;
b i n [ i ]指向代表該箱子的雙向鏈表的首節點
N o d e Type *node;
n o d e [ i ]代表存儲頂點i的節點
圖1-9 實現雙向鏈接箱子所需的U n d i r e c t e d私有成員
程序13-3 箱子函數的定義
void Undirected::CreateBins(int b, int n)
{// 創建b個空箱子和n個節點
node=new NodeType [n+1];
bin=new int [b+1];
// 將箱子置空
for (int i=1; i <=b; i++)
bin[i]=0;
}
void Undirected::InsertBins(int b, int v)
{// 若b不為0,則將v 插入箱子b
if (!b) return; // b為0,不插入
node[v].left=b; // 添加在左端
if (bin[b]) node[bin[b]].left=v;
node[v].right=bin[b];
bin[b]=v;
}
void Undirected::MoveBins(int bMax, int ToBin, int v)
{// 將頂點v 從其當前所在箱子移動到To B i n .
// v的左、右節點
int l=node[v].left;
int r=node[v].right;
// 從當前箱子中刪除
if (r) node[r].left=node[v].left;
if (l > bMax || bin[l] !=v) // 不是最左節點
node[l].right=r;
else bin[l]=r; // 箱子l的最左邊
// 添加到箱子To B i n
I n s e r t B i n s ( ToBin, v);
}
函數C r e a t e B i n s動態分配兩個數組: n o d e和b i n,n o d e [i ]表示頂點i, bin[i ]指向其N e w值為i的雙向鏈表的頂點, f o r循環將所有雙向鏈表置為空。如果b≠0,函數InsertBins 將頂點v 插入箱子b 中。因為b 是頂點v 的New 值,b=0意味著頂點v 不能覆蓋B中當前還未被覆蓋的任何頂點,所以,在建立覆蓋時這個箱子沒有用處,故可以將其捨去。當b≠0時,頂點n 加入New 值為b 的雙向鏈表箱子的最前面,這種加入方式需要將node[v] 加入bin[b] 中第一個節點的左邊。由於表的最左節點應指向它所屬的箱子,因此將它的node[v].left 置為b。若箱子不空,則當前第一個節點的left 指針被置為指向新節點。node[v] 的右指針被置為b i n [ b ],其值可能為0或指向上一個首節點的指針。最後,b i n [ b ]被更新為指向表中新的第一個節點。MoveBins 將頂點v 從它在雙向鏈表中的當前位置移到New 值為ToBin 的位置上。其中存在bMa x,使得對所有的箱子b i n[ j ]都有:如j>bMa x,則b i n [ j ]為空。代碼首先確定n o d e [ v ]在當前雙向鏈表中的左右節點,接著從雙鏈表中取出n o d e [ v ],並利用I n s e r t B i n s函數將其重新插入到b i n [ To B i n ]中。
4.Undirected::BipartiteCover的實現
函數的輸入參數L用於分配圖中的頂點(分配到集合A或B)。L [i ]=1表示頂點i在集合A中,L[ i ]=2則表示頂點在B中。函數有兩個輸出參數: C和m,m為所建立的覆蓋的大小,C [ 0 , m - 1 ]是A中形成覆蓋的頂點。若二分圖沒有覆蓋,函數返回f a l s e;否則返回t r u e。完整的代碼見程序1 3 - 4。
程序13-4 構造貪婪覆蓋
bool Undirected::BipartiteCover(int L[], int C[], int& m)
{// 尋找一個二分圖覆蓋
// L 是輸入頂點的標號, L[i]=1 當且僅當i 在A中
// C 是一個記錄覆蓋的輸出數組
// 如果圖中不存在覆蓋,則返回f a l s e
// 如果圖中有一個覆蓋,則返回t r u e ;
// 在m中返回覆蓋的大小; 在C [ 0 : m - 1 ]中返回覆蓋
int n=Ve r t i c e s ( ) ;
// 插件結構
int SizeOfA=0;
for (int i=1; i <=n; i++) // 確定集合A的大小
if (L[i]==1) SizeOfA++;
int SizeOfB=n - SizeOfA;
CreateBins(SizeOfB, n);
int *New=new int [n+1]; / /頂點i覆蓋了B中N e w [ i ]個未被覆蓋的頂點
bool *Change=new bool [n+1]; // Change[i]為t r u e當且僅當New[i] 已改變
bool *Cov=new bool [n+1]; // Cov[i] 為true 當且僅當頂點i 被覆蓋
I n i t i a l i z e P o s ( ) ;
LinkedStack S;
// 初始化
for (i=1; i <=n; i++) {
Cov[i]=Change[i]=false;
if (L[i]==1) {// i 在A中
New[i]=Degree(i); // i 覆蓋了這麼多
InsertBins(New[i], i);}}
// 構造覆蓋
int covered=0, // 被覆蓋的頂點
MaxBin=SizeOfB; // 可能非空的最大箱子
m=0; // C的游標
while (MaxBin > 0) { // 搜索所有箱子
// 選擇一個頂點
if (bin[MaxBin]) { // 箱子不空
int v=bin[MaxBin]; // 第一個頂點
C[m++]=v; // 把v 加入覆蓋
// 標記新覆蓋的頂點
int j=Begin(v), k;
while (j) {
if (!Cov[j]) {// j尚未被覆蓋
Cov[j]=true;
c o v e r e d + + ;
// 修改N e w
k=Begin(j);
while (k) {
New[k]--; // j 不計入在內
if (!Change[k]) {
S.Add(k); // 僅入棧一次
Change[k]=true;}
k=NextVe r t e x ( j ) ; }
}
j=NextVe r t e x ( v ) ; }
// 更新箱子
while (!S.IsEmpty()) {
S .D e l e t e ( k ) ;
Change[k]=false;
MoveBins(SizeOfB, New[k], k);}
}
else MaxBin--;
}
D e a c t i v a t e P o s ( ) ;
D e s t r o y B i n s ( ) ;
delete [] New;
delete [] Change;
delete [] Cov;
return (covered==SizeOfB);
}
程序1 3 - 4首先計算出集合A和B的大小、初始化必要的雙向鏈表結構、創建三個數組、初始化圖遍歷器、並創建一個棧。然後將數組C o v和C h a n g e初始化為f a l s e,並將A中的頂點根據它們覆蓋B中頂點的數目插入到相應的雙向鏈表中。
為了構造覆蓋,首先按SizeOfB 遞減至1的順序檢查雙向鏈表。當發現一個非空的表時,就將其第一個頂點v 加入到覆蓋中,這種策略即為選擇具有最大Ne o v [ j ]置為t r u e,表示頂點j 現在已被覆蓋,同時將已被覆蓋的B中的頂點數目加1。由於j 是最近被覆w 值的頂點。將所選擇的頂點加入覆蓋數組C並檢查B中所有與它鄰接的頂點。若頂點j 與v 鄰接且還未被覆蓋,則將C蓋的,所有A中與j 鄰接的頂點的New 值減1。下一個while 循環降低這些New 值並將New 值被降低的頂點保存在一個棧中。當所有與頂點v鄰接的頂點的Cov 值更新完畢後,N e w值反映了A中每個頂點所能覆蓋的新的頂點數,然而A中的頂點由於New 值被更新,處於錯誤的雙向鏈表中,下一個while 循環則將這些頂點移到正確的表中。