大家都知道在c語言的運行過程中,局部變量都是存放在棧中的,且是從高位到低位進行進行空間分配。
先看一個程序。

很明顯,地址從高到低分配,和預計的一樣。
稍微修改一下,再運行。
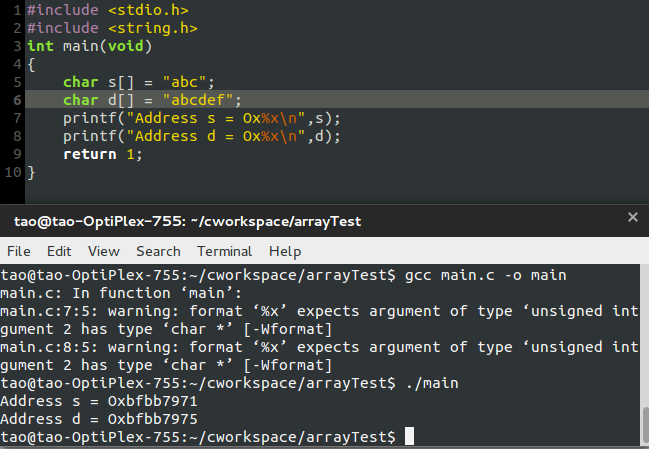
很明顯,從低位到高位!!!
明確一下問題:棧區會應為局部變量的占內存的大小更改內存的分配方式。
為什麼?為什麼?為什麼?
用-S生成匯編語言看一下
第一種情況的匯編語言
.file "main.c"
.section .rodata
.LC0:
.string "Address s = Ox%x\n"
.LC1:
.string "Address d = Ox%x\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $32, %esp
movl %gs:20, %eax
movl %eax, 28(%esp)
xorl %eax, %eax
movl $6513249, 24(%esp)
movw $25185, 21(%esp)
movb $0, 23(%esp)
leal 24(%esp), %eax
movl %eax, 4(%esp)
movl $.LC0, (%esp)
call printf
leal 21(%esp), %eax
movl %eax, 4(%esp)
movl $.LC1, (%esp)
call printf
movl $1, %eax
movl 28(%esp), %edx
xorl %gs:20, %edx
je .L3
call __stack_chk_fail
.L3:
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu/Linaro 4.7.3-1ubuntu1) 4.7.3"
.section .note.GNU-stack,"",@progbits
第二種情況的匯編語言
.file "main.c"
.section .rodata
.LC0:
.string "Address s = Ox%x\n"
.LC1:
.string "Address d = Ox%x\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $32, %esp
movl %gs:20, %eax
movl %eax, 28(%esp)
xorl %eax, %eax
movl $6513249, 17(%esp)
movl $1684234849, 21(%esp)
movw $26213, 25(%esp)
movb $0, 27(%esp)
leal 17(%esp), %eax
movl %eax, 4(%esp)
movl $.LC0, (%esp)
call printf
leal 21(%esp), %eax
movl %eax, 4(%esp)
movl $.LC1, (%esp)
call printf
movl $1, %eax
movl 28(%esp), %edx
xorl %gs:20, %edx
je .L3
call __stack_chk_fail
.L3:
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu/Linaro 4.7.3-1ubuntu1) 4.7.3"
.section .note.GNU-stack,"",@progbits
在前面的幾句mov有很明顯的不同,一個是從低到高分配,一個是從高到低分配.
猜想:編譯器對語言進行的優化,讓長的字符串先進棧。
但為什麼要這麼做呢?
求解答。
本文轉載自:http://blog.csdn.net/qp120291570/article/details/8889950