分而治之方法還可以用於實現另一種完全不同的排序方法,這種排序法稱為快速排序(quick sort)。在這種方法中, n個元素被分成三段(組):左段l e f t,右段r i g h t和中段m i d d l e。中段僅包含一個元素。左段中各元素都小於等於中段元素,右段中各元素都大於等於中段元素。因此l e f t和r i g h t中的元素可以獨立排序,並且不必對l e f t和r i g h t的排序結果進行合並。m i d d l e中的元素被稱為支點( p i v o t )。圖1 4 - 9中給出了快速排序的偽代碼。
/ /使用快速排序方法對a[ 0 :n- 1 ]排序
從a[ 0 :n- 1 ]中選擇一個元素作為m i d d l e,該元素為支點
把余下的元素分割為兩段left和r i g h t,使得l e f t中的元素都小於等於支點,而right中的元素都大於等於支點
遞歸地使用快速排序方法對left進行排序
遞歸地使用快速排序方法對right進行排序
所得結果為l e f t + m i d d l e + r i g h t
圖14-9 快速排序的偽代碼
考察元素序列[ 4 , 8 , 3 , 7 , 1 , 5 , 6 , 2 ]。假設選擇元素6作為支點,則6位於m i d d l e;4,3,1,5,2位於l e f t;8,7位於r i g h t。當left 排好序後,所得結果為1,2,3,4,5;當r i g h t排好序後,所得結果為7,8。把right中的元素放在支點元素之後, l e f t中的元素放在支點元素之前,即可得到最終的結果[ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 ]。
把元素序列劃分為l e f t、m i d d l e和r i g h t可以就地進行(見程序1 4 - 6)。在程序1 4 - 6中,支點總是取位置1中的元素。也可以采用其他選擇方式來提高排序性能,本章稍後部分將給出這樣一種選擇。
程序14-6 快速排序
template
void QuickSort(T*a, int n)
{// 對a[0:n-1]進行快速排序
{// 要求a[n] 必需有最大關鍵值
quickSort(a, 0, n-1);
template
void quickSort(T a[], int l, int r)
{// 排序a[ l : r ], a[r+1] 有大值
if(l >= r)return;
int i = l, // 從左至右的游標
j = r + 1; // 從右到左的游標
T pivot = a[l];
// 把左側>= pivot的元素與右側<= pivot 的元素進行交換
while(true){
do {// 在左側尋找>= pivot 的元素
i = i + 1;
} while(a[i] < pivot);
do {// 在右側尋找<= pivot 的元素
j = j - 1;
} while(a[j] > pivot);
if(i >= j)break; // 未發現交換對象
Swap(a[i], a[j]);
}
// 設置p i v o t
a[l] = a[j];
a[j] = pivot;
quickSort(a, l, j-1); // 對左段排序
quickSort(a, j+1, r); // 對右段排序
}
若把程序1 4 - 6中d o - w h i l e條件內的<號和>號分別修改為< =和> =,程序1 4 - 6仍然正確。實驗結果表明使用程序1 4 - 6的快速排序代碼可以得到比較好的平均性能。為了消除程序中的遞歸,必須引入堆棧。不過,消除最後一個遞歸調用不須使用堆棧。消除遞歸調用的工作留作練習(練習1 3)。程序1 4 - 6所需要的遞歸棧空間為O(n)。若使用堆棧來模擬遞歸,則可以把這個空間減少為O( l o gn)。在模擬過程中,首先對left和right中較小者進行排序,把較大者的邊界放入堆棧中。在最壞情況下l e f t總是為空,快速排序所需的計算時間為(n2 )。在最好情況下, l e f t和r i g h t中的元素數目大致相同,快速排序的復雜性為(nl o gn)。令人吃驚的是,快速排序的平均復雜性也是(nl o gn)。
定理2-1 快速排序的平均復雜性為(nl o gn)。
證明用t(n)代表對含有n個元素的數組進行排序的平均時間。當n≤1時,t(n)≤d,d為某一常數。當n <1時,用s 表示左段所含元素的個數。由於在中段中有一個支點元素,因此右段中元素的個數為n-s- 1。所以左段和右段的平均排序時間分別為t(s), t(n-s- 1 )。分割數組中元素所需要的時間用cn 表示,其中c 是一個常數。因為s 有同等機會取0 ~n- 1中的任何一個值.
如對(2 - 8)式中的n 使用歸納法,可得到t(n)≤kn l o ge n,其中n> 1且k=2(c+d),e~2 . 7 1 8為自然對數的基底。在歸納開始時首先驗證n= 2時公式的正確性。根據公式(1 4 - 8),可以得到t( 2 )≤2c+ 2d≤k nl o ge 2。在歸納假設部分,假定t(n)≤kn l o ge n(當2≤n<m 時,m 是任意一個比2大的整數=.
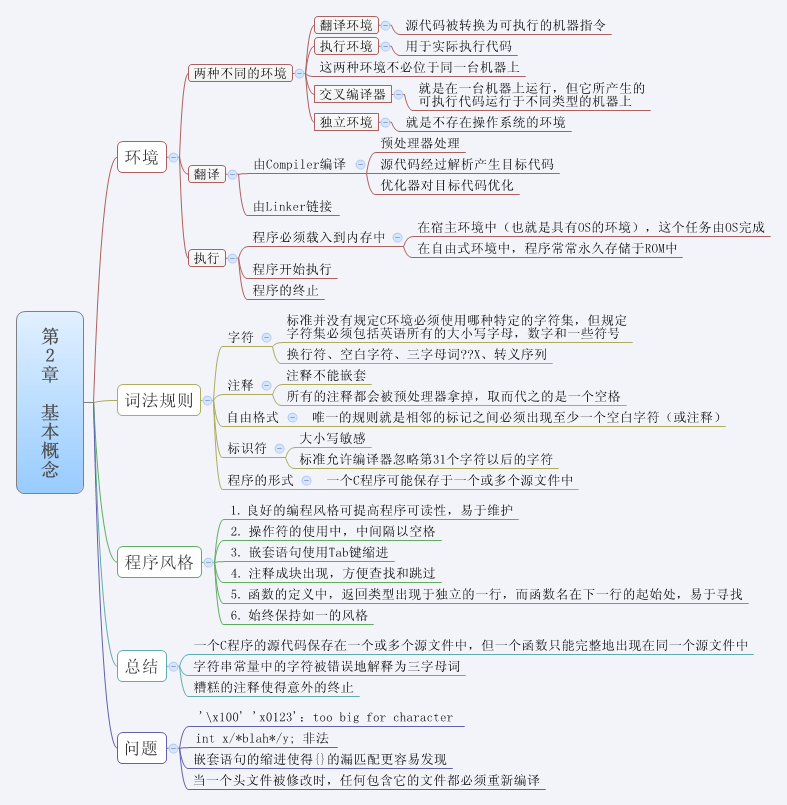
圖1 4 - 1 0對本書中所討論的算法在平均條件下和最壞條件下的復雜性進行了比較。
方法最壞復雜性平均復雜性
冒泡排序n2 n2
計數排序n2 n2
插入排序n2 n2
選擇排序n2 n2
堆排序nl o gn nl o gn
歸並排序nl o gn nl o gn
快速排序n2 nl o gn
圖14-10 各種排序算法的比較
中值快速排序(median-of-three quick sort)是程序1 4 - 6的一種變化,這種算法有更好的平均性能。注意到在程序1 4 - 6中總是選擇a[ 1 ]做為支點,而在這種快速排序算法中,可以不必使用a[ 1 ]做為支點,而是取{a[1],a[(1+r)/2],a[r]}中大小居中的那個元素作為支點。例如,假如有三個元素,大小分別為5,9,7,那麼取7為支點。為了實現中值快速排序算法,一種最簡單的方式就是首先選出中值元素並與a[1]進行交換,然後利用程序1 4 - 6完成排序。如果a[ r ]是被選出的中值元素,那麼將a[1] 與a[r]進行交換,然後將a[ 1 ](即原來的a[ r ])賦值給程序1 4 - 6中的變量p i v o t,之後繼續執行程序1 4 - 6中的其余代碼。
圖2 - 11中分別給出了根據實驗所得到的歸並排序、堆排序、插入排序、快速排序的平均時間。對於每一個不同的n, 都隨機產生了至少1 0 0組整數。隨機整數的產生是通過反復調用s t d l i b . h庫中的r a n d o m函數來實現的。如果對一組整數進行排序的時間少於1 0個時鐘滴答,則繼續對其他組整數進行排序,直到所用的時間不低於1 0個時鐘滴答。在圖2 - 11中的數據包含產生隨機整數的時間。對於每一個n,在各種排序法中用於產生隨機整數及其他開銷的時間是相同的。因此,圖2 - 11中的數據對於比較各種排序算法是很有用的。
對於足夠大的n,快速排序算法要比其他算法效率更高。從圖中可以看到快速排序曲線與插入排序曲線的交點橫坐標比2 0略小,可通過實驗來確定這個交點橫坐標的精確值。可以分別用n = 1 5 , 1 6 , 1 7 , 1 8 , 1 9進行實驗,以尋找精確的交點。令精確的交點橫坐標為nBr e a k。當n≤nBreak 時,插入排序的平均性能最佳。當n>nBreak 時,快速排序性能最佳。當n>nBreak 時,把插入排序與快速排序組合為一個排序函數,可以提高快速排序的性能,實現方法是把程序1 4 - 6中的以下語句:
if(l >= r)r e t u r n ;
替換為
if(r-1
這裡I n s e r t i o n S o r t( a , l , r )用來對a[ 1 : r ]進行插入排序。測量修改後的快速排序算法的性能留作練習(練習2 0)。用更小的值替換n B r e a k有可能使性能進一步提高(見練習2 0)。
大多數實驗表明,當n>c時(c為某一常數),在最壞情況下歸並排序的性能也是最佳的。而當n≤c時,在最壞情況下插入排序的性能最佳。通過將插入排序與歸並排序混合使用,可以提高歸並排序的性能(練習2 1)。