隔離級別的概念
企業級的數據庫每一秒鐘都可能應付成千上萬的並發訪問,因而帶來了並發控制的問題。由數據庫理論可知,由於並發訪問,在不可預料的時刻可能引發如下幾個可以預料的問題:
髒讀:包含未提交數據的讀取。例如,事務1 更改了某行。事務2 在事務1 提交更改之前讀取已更改的行。如果事務1 回滾更改,則事務2 便讀取了邏輯上從未存在過的行。
不可重復讀取:當某個事務不止一次讀取同一行,並且一個單獨的事務在兩次(或多次)讀取之間修改該行時,因為在同一個事務內的多次讀取之間修改了該行,所以每次讀取都生成不同值,從而引發不一致問題。
幻象:通過一個任務,在以前由另一個尚未提交其事務的任務讀取的行的范圍中插入新行或刪除現有行。帶有未提交事務的任務由於該范圍中行數的更改而無法重復其原始讀取。
如你所想,這些情況發生的根本原因都是因為在並發訪問的時候,沒有一個機制避免交叉存取所造成的。而隔離級別的設置,正是為了避免這些情況的發生。事務准備接受不一致數據的級別稱為隔離級別。隔離級別是一個事務必須與其它事務進行隔離的程度。較低的隔離級別可以增加並發,但代價是降低數據的正確性。相反,較高的隔離級別可以確保數據的正確性,但可能對並發產生負面影響。
根據隔離級別的不同,DBMS為並行訪問提供不同的互斥保證。在SQL Server數據庫中,提供四種隔離級別:未提交讀、提交讀、可重復讀、可串行讀。這四種隔離級別可以不同程度地保證並發的數據完整性:
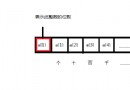
隔離級別 髒 讀 不可重復讀取 幻 像 未提交讀 是 是 是 提交讀 否 是 是 可重復讀 否 否 是 可串行讀 否 否 否可以看出,“可串行讀”提供了最高級別的隔離,這時並發事務的執行結果將與串行執行的完全一致。如前所述,最高級別的隔離也就意味著最低程度的並發,因此,在此隔離級別下,數據庫的服務效率事實上是比較低的。盡管可串行性對於事務確保數據庫中的數據在所有時間內的正確性相當重要,然而許多事務並不總是要求完全的隔離。例如,多個作者工作於同一本書的不同章節。新章節可以在任意時候提交到項目中。但是,對於已經編輯過的章節,沒有編輯人員的批准,作者不能對此章節進行任何更改。這樣,盡管有未編輯的新章節,但編輯人員仍可以確保在任意時間該書籍項目的正確性。編輯人員可以查看以前編輯的章節以及最近提交的章節。這樣,其它的幾種隔離級別也有其存在的意義。
在.Net框架中,事務的隔離級別是由枚舉System.Data.IsolationLevel所定義的:
[Flags]
[Serializable]
public enum IsolationLevel
其成員及相應的含義如下:
成 員 含 義 Chaos 無法改寫隔離級別更高的事務中的掛起的更改。 ReadCommitted 在正在讀取數據時保持共享鎖,以避免髒讀,但是在事務結束之前可以更改數據,從而導致不可重復的讀取或幻像數據。 ReadUncommitted 可以進行髒讀,意思是說,不發布共享鎖,也不接受獨占鎖。 RepeatableRead 在查詢中使用的所有數據上放置鎖,以防止其他用戶更新這些數據。防止不可重復的讀取,但是仍可以有幻像行。 Serializable 在DataSet上放置范圍鎖,以防止在事務完成之前由其他用戶更新行或向數據集中插入行。 UnspecifIEd 正在使用與指定隔離級別不同的隔離級別,但是無法確定該級別。顯而意見,數據庫的四個隔離級別在這裡都有映射。
默認的情況下,SQL Server使用ReadCommitted(提交讀)隔離級別。
關於隔離級別的最後一點就是如果你在事務執行的過程中改變了隔離級別,那麼後面的命名都在最新的隔離級別下執行——隔離級別的改變是立即生效的。有了這一點,你可以在你的事務中更靈活地使用隔離級別從而達到更高的效率和並發安全性。
最後的忠告
無疑,引入事務處理是應對可能出現的數據錯誤的好方法,但是也應該看到事務處理需要付出的巨大代價——用於存儲點、回滾和並發控制所需要的CPU時間和存儲空間。
本文的內容只是針對Microsoft SQL Server數據庫的,對應於.net框架中的System.Data.SqlClIEnt命名空間,對於使用OleDb的情形,具體的實現稍有不同,但這不是本文的內容,有興趣的讀者可以到.Net中華網(www.ASPcn.com)的論壇裡找到答案。