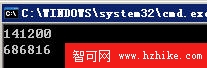
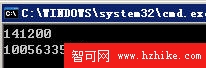
代碼執行結果如下圖(前面是使用享元模式的結果,後面是沒有使用享元模式的結果):
代碼說明
l 這裡的ModelFactory就是享元工廠角色。它的作用是創建和管理享元對象。可以看到,每加載一個模型都會在Hashtable中記錄一下,之後如果客戶端還是需要這個模型的話就直接把已有的模型對象返回給客戶端,而不是重新在內存中加載一份模型數據。
l ModelFactory本身應用了Singleton,因為如果實例化多個享元工廠是的話就起不到統一管理和分配享元對象的目的了。
l Model就是享元角色。在構造方法中傳入modelName,然後它從指定路徑加載模型數據,並且把數據放入字段中。
l 從代碼的運行結果中可以看到,如果沒有應用享元模式,那麼在內存中就會有10000套模型對象,由於一共就2個模型,所以9998個對象是可以通過享元來消除的。
何時采用
l 系統中有大量耗費了大量內存的細粒度對象,並且對外界來說這些對沒有任何差別的(或者說經過改造後可以是沒有差別的)。
實現要點
l 享元工廠維護一張享元實例表。
l 享元不可共享的狀態需要在外部維護。
l 按照需求可以對享元角色進行抽象。
注意事項
l 享元模式通常針對細粒度的對象,如果這些對象比較擁有非常多的獨立狀態(不可共享的狀態),或者對象並不是細粒度的,那麼就不適合運用享元模式。維持大量的外蘊狀態不但會使邏輯復雜而且並不能節約資源。
l 享元工廠中維護了享元實例的列表,同樣也需要占用資源,如果享元占用的資源比較小或者享元的實例不是非常多的話(和列表元素數量差不多),那麼就不適合使用享元,關鍵還是在於權衡得失。