六、分析網絡資源
對下載的網絡資源進行分析是網絡蜘蛛中最重要的功能之一。這裡網絡資源主要指的是html代碼中標簽的href屬性值。狀態和狀態之間會根據從Html文件中讀入的字符進行切換。下面是狀態之間切換的描述。
狀態0:讀入'<'字符後切換到狀態1,讀入其他的字符,狀態不變。
狀態1:讀入'a'或'A',切換到狀態2,讀入其他的字符,切換到狀態0。
狀態2:讀入空格或制表符(\t),切換到狀態3,讀入其他的字符,切換到狀態0。
狀態3:讀入'>',成功獲得一個,讀入其他的字符,狀態不變。為了更容易說明問題。在本文給出的網絡蜘蛛中只提取了html代碼中中的href屬性中的url。本文中所采用的分析方法是分步進行提取href。首先將Html代碼中的標簽整個提出來。不包括和前面的字符,如comprg中只提取,而comprg將被忽略,因為這裡並沒有url。
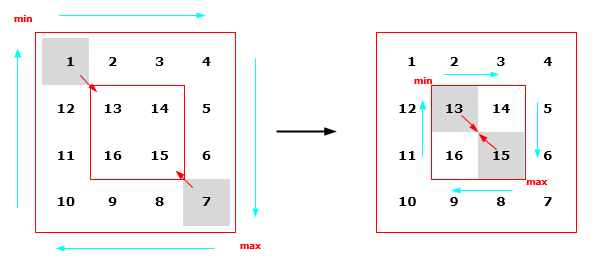
本文使用了一個狀態機來的提取,這個狀態機分為五個狀態(0 至 4)。第一個狀態是初始態,最後一個狀態為終止態,如果到達最後一個狀態,說明已經成功獲得了一個
狀態機如圖1所示。
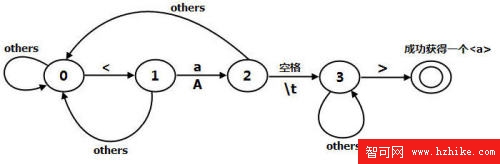
圖1
最後一個雙環的狀態是最終態。下面讓我們來看看獲得的實現代碼。
getA方法的實現
// 獲得Html中的
private void getA()
{
char[] buffer = new char[1024];
int state = 0;
String a = "";
while (!sr.EndOfStream)
{
int n = sr.Read(buffer, 0, buffer.Length);
for (int i = 0; i < n; i++)
{
switch (state)
{
case 0: // 狀態0
if (buffer[i] == '<') // 讀入的是'<'
{
a += buffer[i];
state = 1; // 切換到狀態1
}
break;
case 1: // 狀態1
if (buffer[i] == 'a' || buffer[i] == 'A') // 讀入是'a'或'A'
{
a += buffer[i];
state = 2; // 切換到狀態2
}
else
{
a = "";
state = 0; // 切換到狀態0
}
break;
case 2: // 狀態2
if (buffer[i] == ' ' || buffer[i] == '\t') // 讀入的是空格或'\t'
{
a += buffer[i];
state = 3;
}
else
{
a = "";
state = 0; // 切換到狀態0
}
break;
case 3: // 狀態3
if (buffer[i] == '>') // 讀入的是'>',已經成功獲得一個
{
a += buffer[i];
try
{
string url = getUrl(getHref(a)); // 獲得中的href屬性的值
if (url != null)
{
if (findUrl != null)
findUrl(url); // 引發發現url的事件
}
}
catch (Exception e)
{
}
state = 0; // 在獲得一個後,重新切換到狀態0
}
else
a += buffer[i];
break;
}
}
}
}