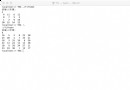
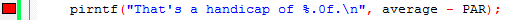我們首先從考查字符串pat開始,pat中包含有表達式。第一個capture是從第一個圓括號開始的,然後表達式將匹配到一個abra。第二個capture組從第二個圓括號開始,但第一個capture組還沒有結束,這意味著第一個組匹配的結果是abracad ,而第二個組的匹配結果僅僅是cad。因此如果通過使用?符號而使cad成為一項可選的匹配,匹配的結果就可能是abra或abracad。然後,第一個組就會結束,通過指定+符號要求表達式進行多次匹配。
現在我們來看看匹配過程中發生的情況。首先,通過調用Regex的constructor方法建立表達式的一個實例,並在其中指定各種選項。在這個例子中,由於在表達式中有注釋,因此選用了x選項,另外還使用了一些空格。打開x選項,表達式將會忽略注釋和其中沒有轉義的空格。
然後,取得表達式中定義的組的編號的清單。你當然可以顯性地使用這些編號,在這裡使用的是編程的方法。如果使用了命名的組,作為一種建立快速索引的途徑這種方法也十分有效。
接下來是完成第一次匹配。通過一個循環測試當前的匹配是否成功,接下來是從group 1開始重復對組清單執行這一操作。在這個例子中沒有使用group 0的原因是group 0是一個完全匹配的字符串,如果要通過收集全部匹配的字符串作為一個單一的字符串,就會用到group 0了。
我們跟蹤每個group中的CaptureCollection。通常情況下每次匹配、每個group中只能有一個capture,但本例中的Group1則有兩個capture:Capture0和Capture1。如果你僅需要Group1的ToString,就會只得到abra,當然它也會與abracad匹配。組中ToString的值就是其CaptureCollection中最後一個Capture的值,這正是我們所需要的。如果你希望整個過程在匹配abra後結束,就應該從表達式中刪除+符號,讓regex引擎知道我們只需要對表達式進行匹配。
基於過程和基於表達式方法的比較
一般情況下,使用規則表達式的用戶可以分為以下二大類:第一類用戶盡量不使用規則表達式,而是使用過程來執行一些需要重復的操作;第二類用戶則充分利用規則表達式處理引擎的功能和威力,而盡可能少地使用過程。
對於我們大多數用戶而言,最好的方案莫過於二者兼而用之了。我希望這篇文章能夠說明.Net語言中regexp類的作用以及它在性能和復雜性之間的優、劣點。
基於過程的模式
我們在編程中經常需要用到的一個功能是對字符串中的一部分進行匹配或其他一些對字符串處理,下面是一個對字符串中的單詞進行匹配的例子:
string text = "the quick red fox jumped over the lazy brown dog.";
System.Console.WriteLine("text=[" + text + "]");
string result = "";
string pattern = @"\w+|\W+";
foreach (Match m in Regex.Matches(text, pattern))
{
// 取得匹配的字符串
string x = m.ToString();
// 如果第一個字符是小寫
if (char.IsLower(x[0]))
// 變成大寫
x = char.ToUpper(x[0]) + x.Substring(1, x.Length-1);
// 收集所有的字符
result += x;
}
System.Console.WriteLine("result=[" + result + "]");
正象上面的例子所示,我們使用了C#語言中的foreach語句處理每個匹配的字符,並完成相應的處理,在這個例子中,新創建了一個result字符串。這個例子的輸出所下所示:
text=[the quick red fox jumped over the lazy brown dog.]
result=[The Quick Red Fox Jumped Over The Lazy Brown Dog.]