承接上一篇,這一篇講如何把表達式轉換成記號對象,這裡就涉及到了編譯原理中的詞法分析。關於編譯原理我不想多講,畢竟我自己也不 怎麼熟悉,現在只知道其中有個有限自動機的概念。不管什麼概念,用代碼實現才是最終目標。
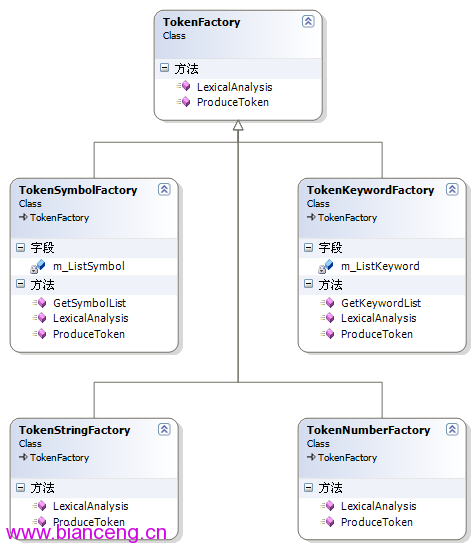
因為不清楚字符串中到底包含什麼字符,只能一個個字符進行處理,采用循環一次次向後取一個字符進行判斷。這裡建立一個TokenFactory 記號“工廠”類,由這個類負責對表達式進行分析並“生產”出TokenRecord對象。其中包括兩個方法, LexicalAnalysis和ProduceToken。LexicalAnalysis用於詞法分析,分析到符合規則的記號對象後調用ProduceToken方法,“生產 ”出對應的TokenRecord對象。這裡偷了一點懶,把所有方法全部寫成了static,這樣就不用實例化多個子類了。
從這個類衍生出多個子類:
TokenKeyWordFactory:用於處理關鍵字
TokenSymbolFactory:用於處理運算符
TokenStringFactory:用於處理字符串
TokenNumberFactory:用於處理數字
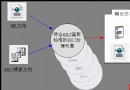
類圖如下: