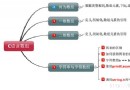
C# XML解析方法之“推”模型:
“推”模型也就是常說的SAX,SAX是一種靠事件驅動的模型。它每發現一個節點就用“推”模型引發一個事件,而我們必須編寫這些事件的處理程序,很麻煩。
C# XML解析方法之“拉”模型:
.NET中使用的是基於“拉”模型的實現方案。 “拉”模型在遍歷文檔時會把感興趣的文檔部分從讀取器中拉出,不需要引發事件,允許我們以編程的方式訪問文檔,這大大的提高了靈活性,“拉”模型可以選擇性的處理節點。在.Net中,“拉”模型通過XML閱讀器(XMLTextReader類)來實現的。該類提供Xml文件讀取的功能,它可以驗證文檔是否格式良好,如果不是格式良好的Xml文檔,該類在讀取過程中將會拋出XMLException異常。任何時候在內存中只有當前節點,但它是只讀的,向前的,不能在文檔中執行向後導航操作。
C# XML解析方法之DOM介紹:
DOM的好處在於它允許編輯和更新XML文檔,可以隨機訪問文檔中的數據,可以使用XPath查詢。但是,DOM的缺點在於它需要一次性的加載整個文檔到內存中,對於大型的文檔,這會造成資源問題。在.Net中使用XML DOM分析器(XMLDocument)實現DOM模型。
因此,.NET Framework完全支持XML DOM模式,但它不支持SAX模式。.Net Framework支持兩種不同的分析模式:XML DOM分析器(XMLDocument類)和XML閱讀器(XMLTextReader類),不支持SAX分析器, 但這並不意味著它沒有提供類似SAX分析器的功能。通過XML閱讀器可以將SAX的所有的功能很容易的實現及更有效的運用。
C# XML解析方法的介紹就向你講解到這裡,希望你對C# XML解析方法的了解和學習有所幫助。