摘要:
隨機數在實際運用中非常之多,如游戲設計,信號處理,通常我們很容易得到平均分布的隨機數。但如何根據平均分布的隨機數進而產生其它分布的隨機數呢?本文提出了一種基於幾何直觀面積的方法,以正態分布隨機數的產生為例討論了任意分布的隨機數的產生方法。
正文:
一、平均分布隨機數的產生
大家都知道,隨機數在各個方面都有很大的作用,在vc的環境下,為我們提供了庫函數rand()來產生一個隨機的整數。該隨機數是平均在0~RAND_MAX之間平均分布的,RAND_MAX是一個常量,在VC6.0環境下是這樣定義的:
#define RAND_MAX 0x7fff
它是一個short 型數據的最大值,如果要產生一個浮點型的隨機數,可以將rand()/1000.0這樣就得到一個0~32.767之間平均分布的隨機浮點數。如果要使得范圍大一點,那麼可以通過產生幾個隨機數的線性組合來實現任意范圍內的平均分布的隨機數。例如要產生-1000~1000之間的精度為四位小數的平均分布的隨機數可以這樣來實現。先產生一個0到10000之間的隨機整數。方法如下 :
int a = rand()%10000;
然後保留四位小數產生0~1之間的隨機小數:
double b = (double)a/10000.0;
然後通過線性組合就可以實現任意范圍內的隨機數的產生,要實現-1000~1000內的平均分布的隨機數可以這樣做:
double dValue = (rand()%10000)/10000.0*1000-(rand()%10000)/10000.0*1000;
則dValue就是所要的值。
到現在為止,你或許以為一切工作都已經完成了,其實不然,仔細一看,你會發現有問題的,上面的式子化簡後就變為:
double dValue = (rand()%10000)/10.0-(rand()%10000)/10.0;
這樣一來,產生的隨機數范圍是正確的,但是精度不正確了,變成了只有一位正確的小數的隨機數了,後面三位的小數都是零,顯然不是我們要求的,什麼原因呢,又怎麼辦呢。
先找原因,rand()產生的隨機數分辨率為32767,兩個就是65534,而經過求余後分辨度還要減小為10000,兩個就是20000而要求的分辨率為1000*10000*2=20000000,顯然遠遠不夠。下面提供的方法可以實現正確的結果:
double a = (rand()%10000) * (rand()%1000)/10000.0;
double b = (rand()%10000) * (rand()%1000)/10000.0;
double dValue = a-b;
則dValue就是所要求的結果。在下面的函數中可以實現產生一個在一個區間之內的平均分布的隨機數,精度是4位小數。
double AverageRandom(double min,double max)
{
int minInteger = (int)(min*10000);
int maxInteger = (int)(max*10000);
int randInteger = rand()*rand();
int diffInteger = maxInteger - minInteger;
int resultInteger = randInteger % diffInteger + minInteger;
return resultInteger/10000.0;
}
但是有一個值得注意的問題,隨機數的產生需要有一個隨機的種子,因為用計算機產生的隨機數是通過遞推的方法得來的,必須有一個初始值,也就是通常所說的隨機種子,如果不對隨機種子進行初始化,那麼計算機有一個確省的隨機種子,這樣每次遞推的結果就完全相同了,因此需要在每次程序運行時對隨機種子進行初始化,在vc中的方法是調用srand(int)這個函數,其參數就是隨機種子,但是如果給一個常量,則得到的隨機序列就完全相同了,因此可以使用系統的時間來作為隨機種子,因為系統時間可以保證它的隨機性。
調用方法是srand(GetTickCount()),但是又不能在每次調用rand()的時候都用srand(GetTickCount())來初始化,因為現在計算機運行時間比較快,當連續調用rand()時,系統的時間還沒有更新,所以得到的隨機種子在一段時間內是完全相同的,因此一般只在進行一次大批隨機數產生之前進行一次隨機種子的初始化。下面的代碼產生了400個在-1~1之間的平均分布的隨機數。
double dValue[400];
srand(GetTickCount());
for(int i= 0;i < 400; i++)
{
double dValue[i] = AverageRandom(-1,1);
}
用該方法產生的隨機數運行結果如圖1所示:
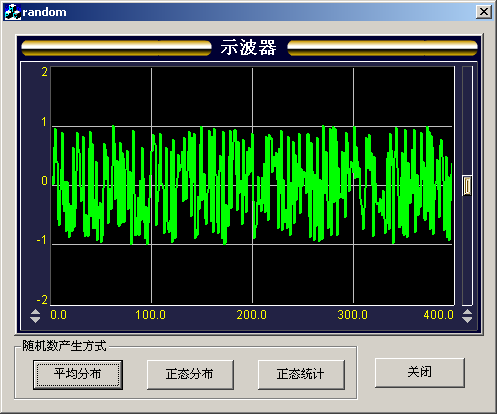
圖1 400個-1~1之間平均分布的隨機數
二、任意分布隨機數的產生
下面提出了一種已知概率密度函數的分布的隨機數的產生方法,以典型的正態分布為例來說名任意分布的隨機數的產生方法。
如果一個隨機數序列服從一維正態分布,那麼它有有如下的概率密度函數:
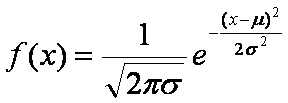 (1-1)
(1-1)
其中μ,σ( >0)為常數,它們分別為數學期望和均方差,如果讀者對數學期望和均方差的概念還不大清楚,請查閱有關概率論的書。如果取μ =0,σ =0.2,則其曲線為
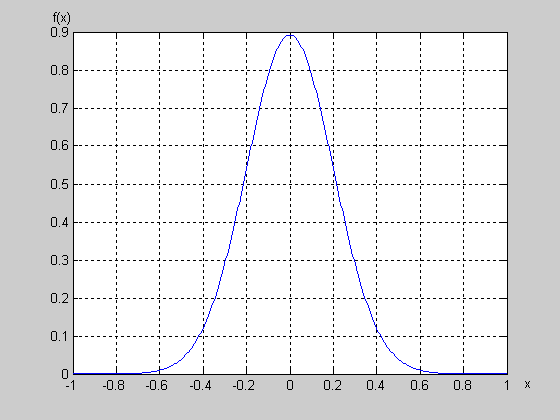
圖2 正態分布的概率密度函數曲線
從圖中可以看出,在μ附近的概率密度大,遠離μ的地方概率密度小,我們要產生的隨機數要服從這種分布,就是要使產生的隨機數在μ附近的概率要大,遠離μ處小,怎樣保證這一點呢,可以采用如下的方法:在圖2的大矩形中隨機產生點,這些點是平均分布的,如果產生的點落在概率密度曲線的下方,則認為產生的點是符合要求的,將它們保留,如果在概率密度曲線的上方,則認為這些點不合格,將它們去處。如果隨機產生了一大批在整個矩形中均勻分布的點,那麼被保留下來的點的橫坐標就服從了正態分布。可以設想,由於在μ處的f(x)的值比較大,理所當然的在μ附近的點個數要多,遠離μ處的少,這從面積上就可以看出來。我們要產生的隨機數就是這裡的橫坐標。
基於以上思想,我們可以用程序實現在一定范圍內服從正態分布的隨機數。程序如下:
double Normal(double x,double miu,double sigma) //概率密度函數
{
return 1.0/sqrt(2*PI*sigma) * exp(-1*(x-miu)*(x-miu)/(2*sigma*sigma));
}
double NormalRandom(double miu,
double sigma,double min,double max)//產生正態分布隨機數
{
double x;
double dScope;
double y;
do
{
x = AverageRandom(min,max);
y = Normal(dResult, miu, sigma);
dScope = AverageRandom(0, Normal(miu,miu,sigma));
}while( dScope > y);
return x;
}
參數說明:double miu:μ,正態函數的數學期望
double sigma:σ,正態函數的均方差
double min,double max,表明產生的隨機數的范圍
用如上方法,取 μ=0,σ=0.2,范圍是-1~1產生400個正態隨機數如圖3所示:
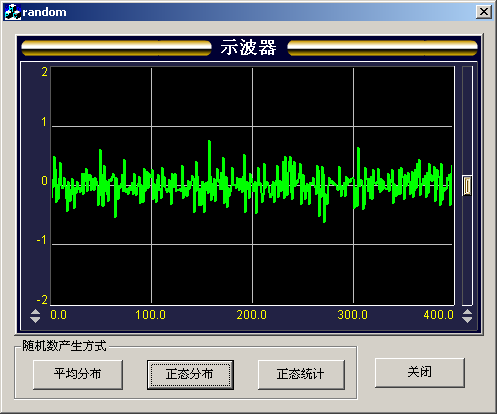
圖3 μ=0, σ=0.2,范圍在-1~1時的400個正態分布的隨機數分布圖
取 μ=0, σ=0.05,范圍是-1~1產生400個正態隨機數如圖4所示:
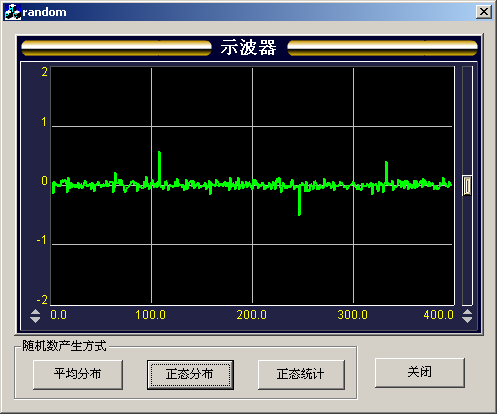
圖4 μ=0,σ=0.05,范圍在-1~1時的400個正態分布的隨機數分布圖
從圖3和圖4的比較可以看出, 越小,產生的隨機數靠近 的數量越多,也說明了產生的隨機數靠近 的概率越大。
我們,先產生4000個在0到4之間的正態分布的隨機數,取μ=0,σ=0.2,再把產生的數據的數量做個統計,畫成曲線,如下圖5所示:
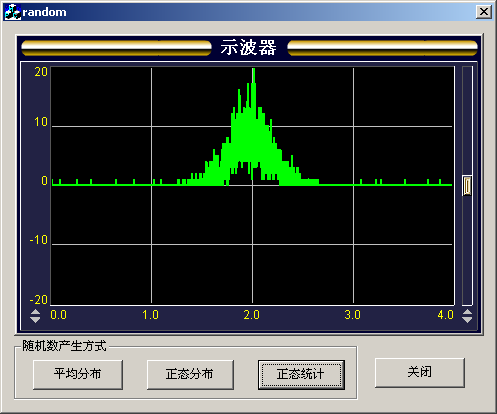
圖5 μ=0, σ=0.2,范圍在0~4時的4000個正態分布的隨機數統計圖
從圖5中也可以看出,在靠近 處的產生的個數多,遠離 處的產生的數量少,該圖的輪廓線和概率密度曲線的形狀剛好吻合。也就驗證了該方法的正確性。
有了以上基礎,也就用同樣的方法,只要知道概率密度函數,也就不難產生任意分布的隨機數,方法都是先產生一個點,然後進行取捨,落在概率密度曲線下方的點就滿足要求,取其橫坐標就是所要獲取的隨機數。
本文配套源碼