說明
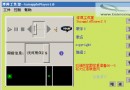
本文根據VC知識庫《在線雜志》的第30期的一篇文章:《類似 MSN 信息發送框的制作》,介紹了一個可以在RichEdit中添加表情圖象的類CFaceEdit。 以下是使用這個類的程序截圖:
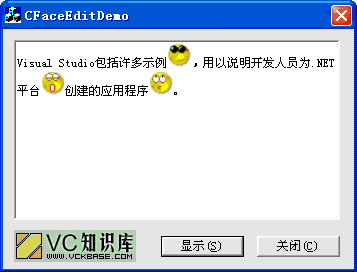
圖一 CFaceEdit類的使用
使用方法
我們可以先看一下它的使用方法:
//將對話框類成員變量由CRichEditCtrl改為CFaceEdit
CFaceEdit m_FaceEdit;
//自定義一組表情
CString pSymbol[] = {":)", ":(", ";)", ":0", ";-)"};
//表情對應的圖象ID
UINT nIDBmp[] = { IDB_BITMAP1, IDB_BITMAP2, IDB_BITMAP3, IDB_BITMAP4, IDB_BITMAP5};
m_FaceEdit.Init(5, pSymbol, nIDBmp);
......
m_FaceEdit.SetText("Visual Studio 包括許多示例:),用以說明開發人員為.NET 平台;)創建的應用程序:-) 。");
也可以以位圖文件的形式導入位圖:
CString sBmpFile[] = {"res\\kid.bmp", "res\\sad.bmp", "res\\showoff.bmp", "res\\quip.bmp", "res\\maze.bmp"};
m_FaceEdit.Init(5, pSymbol, sBmpFile);
...
m_FaceEdit.SetText("Visual Studio 包括許多示例:),用以說明開發人員為.NET 平台;)創建的應用程序:-) 。");
插入圖象的主要原理,是由《類似 MSN 信息發送框的制作》一文中提供的InsertBitmap()函數實現的。該函數可以通過指定圖象的ID插入圖象,或通過圖象文件的路徑來插入圖象。
那麼如何將文本中的字符表情,如::)、;-) 等翻譯成圖象呢?例如,對於字符串:
"Visual Studio 包括許多示例:),用以說明開發人員為.NET 平台;)創建的應用程序:-)。"
翻譯之後,變成:
"Visual Studio 包括許多示例 ,用以說明開發人員為.NET 平台
,用以說明開發人員為.NET 平台 創建的應用程序
創建的應用程序 。"
。"
如何實現呢?
在使用InsertBitmap()函數插入圖象時,我發現只要先將RichEdit中的某一段文本內容選中,然後再調用InsertBitmap()函數,便可實現將選定內容替換成圖象。如:
"Visual Studio 包括許多示例:),用以說明開發人員為.NET 平台;)創建的應用程序:-)。"
再調用InsertBitmap()函數:
"Visual Studio 包括許多示例,用以說明開發人員為.NET 平台;)創建的應用程序:-)。"
後面的符號只要使用相同的方法處理即可。明白了這一點,想要實現轉換圖象的功能也就不難了。我們可以使用CRichEditCtrl::SetSel()來實現,不過在此之前,要對各表情字符的一些信息,如位置、表情類型、長度等進行保存,以下是翻譯文本的函數的代碼:
/*-----------------------------------------------------------------------------
* 函數名 :SetTextWithFace
*
* 功能 :實現插入圖象的算法函數。
* 實現原理:
假設:CString pSymbol[] = {":)", ":(", "#", "AK47", ":-)"};
先將包括表情符號的文本( 如:"haha:)" )直接顯示到CRichEditCtrl中,
然後選定其中的表情符號( 如:":)" ),再調用InsertBitmap函數
實現插入,詳見注釋
-----------------------------------------------------------------------------*/
void CFaceEdit::SetTextWithFace(CString str)
{
CString *pstr = new CString[m_nfaceCount];
for(int n = 0; n<m_nfaceCount; n++)
{
pstr[n] = m_pSymbol[n];
}
SetWindowText(str);
int nFaceCount = 0; //str中共有多少個表情。
stFace faceNode; //faceNode中存儲的是在哪個位置插入,插入哪一個表情。
vector <stFace> vecFace; //vecFace[0]表示第一個表情的位置和型號、vecFace[1]表示第二的位置和型號…
/* ************************************************************************
* 第一步:
* 在str中查找表情字符(pstr)。
*
* 如str = "我們的:-)明天更美好AK47,一定:-)非常美好#。"。那麼以下操作將生成四個
* stFace(定義見FaceEdit.h)結點,它們的值分別為{3, 3, 3}, {15, 3, 4}, {10, 1, 3}, {21, 0, 1}。
* 使用vector數組vecFace進行存儲。
*
* *************************************************************************/
for(int i=0, m = -1; i<m_nfaceCount; i++)
{
//關鍵的一步:查找寬字符,漢字算一個字符。放在循環中,就可以查找重復的字符。
while(1)
{
m = (int)str.Find(pstr[i], m + 1); //循環搜索
if(m != -1)
{
faceNode.nPos = m;
faceNode.nFaceIndex = i;
faceNode.nLength = (int)pstr[i].GetLength();
vecFace.push_back(faceNode);
nFaceCount++;
}
else
{
break;
}
}
} //查找完畢
if(nFaceCount==0) //在str中沒找到一個表情,下面就無需插入表情了。
return;
delete []pstr;
/* ************************************************************************
* 第二步:
* 使用泛型算法sort進行排序。
*
* 上面的四個結點:A:{3, 3, 3}, B:{15, 3, 4}, C:{10, 1, 3}, D:{21, 0, 1},顯然這不是按照
* 順序排的,這裡應該按表情在文本中出現的次序依次替換,否則替換算法將會非常麻煩。
*
* *************************************************************************/
bool less_than(stFace &face1, stFace &face2); //聲明排序的"條件"函數
//詳見我的ObjectSort工程中的說明。可參見《Essential C++》P84
sort(vecFace.begin(), vecFace.end(), less_than);
/* ***********************************************************************
* 第三步:
* 調整各表情字符位置(nPos)。
*
* 排序之後各結點:A:{3, 3, 3}, C:{10, 1, 3}, B:{15, 3, 4}, D:{21, 0, 1}。
* 經過摸索,發現這樣一個規律:
* 本結點應該向前挪的值(prev) = 上一個表情的長度(prevLength) - 1 + 上一個結點應該向前挪的值(prev)
*
* 如:
CString pSymbol[] = {":)", ":(", "#", "AK47", ":-)"};
序號:? 0 1? 2? ?3? ?4
"我們的:-)明天更美好AK47,一定:-)非常美好#。"
位置: 3 11 18 25
"#"(25, 2, 1) "AK47"(11, 3, 4) ":-)"(3, 4, 3) ":-)"(18, 4, 3)
~~ ~~ ~~ ~~
排序後:
":-)"(3, 4, 3) "AK47"(11,3, 4) ":-)"(18, 4, 3) "#"(25, 2, 1)
~~ ~~ ~~ ~~
處理後:
":-)"(3, 4, 3) "AK47"(9, 3, 4) ":-)"(13, 4, 3) "#"(18, 2, 1)
~~ ~~ ~~ ~~
少了0 少了2 少了5 少了7
3-1+0 4-1+2 3-1+5
*
*
* *********************************************************************/
for(int t = 0, prevLength = 0, prev = 0; t<nFaceCount; t++)
{
vecFace[t].nPos -= prev;
prevLength = vecFace[t].nLength;
prev = prevLength - 1 + prev;
}
/* ********************************************************************
* 第四步:
* 下面插入表情。
*
* 調用InsertBitmap插入各處理完成的各結點A:{3, 3], C:{9, 1}, B:{13, 3}, D:{18, 0}。
*
* *********************************************************************/
try
{
for(int j=0; j<nFaceCount; j++)
{
stFace faceNode = vecFace[j];
InsertBitmap(faceNode);
}
}
catch(char *sError)
{
MessageBox(sError, "HBITMAP", MB_OK | MB_ICONERROR);
}
}
注意事項
本類有兩個版本,一個是針對RichEdit 1.0的,另一個是針對RichEdit 2.0的。它們的區別是,前者把一個漢字作為兩個字節處理,而後者把一個漢字作為一個字節處理。請讀者區分使用。
本文配套源碼