Microsoft ActiveX Data Objects (ADO) 支持用於建立基於客戶端/服務器和 Web 的應用程序的主要功能。其主要優點是易於使用、高速度、低內存支出和占用磁盤空間較少。
本次封裝的CadoInterface類僅針對MFC的使用,目的是優化對ADO的操作,避免頻繁寫try catch(…)以及在連庫、開表、寫數據、讀數據等過程中一些重復性的工作。該類僅對一些常用的操作進行封裝,用戶可以根據需要進行修改和擴展。
封裝類主要包括:基本操作、增值操作、支持算法與支持結構。基本操作、增值操作、支持算法在AdoInterface.h與AdoInterface.cpp中聲明定義,支持結構在DataBelong.h中定義。
這裡主要介紹該類的應用,實現細節的說明在代碼中均有注釋。
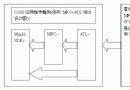
一、封裝類的關系
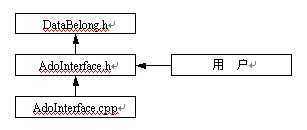
圖一 封裝類關系圖,箭頭代表包含關系,用戶使用時只需包含界面文件AdoInterface.h
二、基本操作部分
(一)連接數據庫
CString Conn="provider=Microsoft.Jet.OLEDB.4.0;Data Source=test.mdb";
myado.ConnecDataLibrary(Conn,"","");
本例連接了一個無密碼的Access庫,如用其他方式連接數據庫,用戶可自行更改連接字符串,或者以枚舉方式將多種連接方式封裝到本函數中。
(二)開表
myado.OpenSheet("select * from file");
用戶僅需給出開表條件即可,其他的枚舉參數均有默認值,如用戶需要以不同方式打開,則可以重新給定枚舉參數的默認值。
(三)關庫、關表
myado.CloseSheet();
myado.CloseDataLibrary();
(四)返回指針
myado.GetConnPtr();
myado.GetRecoPtr();
如用戶的需求超出本類提供的操作時,可以通過這兩個函數獲取_ConnectionPtr與_RecordsetPtr指針,調用ADO的操作。
(五)屬性判斷
myado.BOF();
myado.adoEOF();
(六)指針的移動
5種基本的指針移動(包括:MoveFirst、MoveLast、MoveNext、MovePrevious與Move(long Num))。
(七)執行SQL語句
CString str="Delete from file where AGE=36";
myado.Execute(str);
(八)獲得字段內容
_variant_t str;
myado.GetCollect("NAME",str);
CString name=str;
(九)刪除一條記錄
myado.Delet();
默認刪除當前記錄,用戶可根據需要修改枚舉參數。
三、增值操作部分
(一)追加一條新記錄
AddNewCode insert[3];
insert[0].ColName="NAME"; insert[0].Value="插入一條新記錄";
insert[1].ColName="AGE"; insert[1].Value=18;
insert[2].ColName="TIME"; insert[2].Value="1999/9/9";
myado.AddNewRecode(insert,3);
用戶需要確定向該條記錄的哪些字段添寫數據,然後根據字段的個數定義數組(AddNewCode為支持結構)。本函數需要兩個參數:支持結構的數組指針與添寫字段的個數。
(二)追加一條新記錄(擴展)
myado.AddNewRecodeEx2("FF,NAME,小數,NUM,AGE,TIME",-2.17,"查林傑",3.1415927,10,-18,"1995/6/9");
該函數采用了未定參數的形式(類似於CString中的Format()函數形式)。
第一個參數為要寫入字段的字段名,字段名要以字符串方式給出,字段名之間用逗號分開;後面的參數為賦值參數,要與前面的字段名一一對應,賦值方式參考應用舉例。
(三)獲取一條記錄的內容
_variant_t ColName[5];
ColName[0]="ID";ColName[1]="NAME";ColName[2]="AGE";ColName[3]="TIME";ColName[4]="HF";
_variant_t OutValue[5];
CString id,name1,age,time,hf;
myado.GetOneRecord(ColName,5,OutValue);
id=OutValue[0]; name1=OutValue[1]; age=OutValue[2]; time=OutValue[3]; hf=OutValue[4];
該函數需要三個參數,第一參數要一個_variant_t數組,順序給定要獲取的字段名;第二個參數為要獲取字段的個數;第三個為出參,也要一個_variant_t數組,用來順序保存所獲取的數據。
(四)獲取一條記錄的內容(擴展)
long la=0,lb=0; double da=0,db=0; CString s1="",s2="";
myado.GetOneRecordEx2("FF,NAME,小數,NUM,AGE,TIME",&da,&s1,&db,&la,&lb,&s2);
該函數采用了未定參數的形式(類似於CString中的Format()函數形式)。
第一個參數為要獲取字段的字段名,字段名要以字符串方式給出,字段名之間用逗號分開;後面的參數為接收變量的地址,要與前面的字段名一一對應,函數執行後,各接收變量中保存了所獲取的數據。
(五)查找
myado.Find("AGE=47");
while(myado.FindNext())
{
……
}
查找包括Find與FindNext,這兩個方法經常配合使用。Find在查找到一個符合條件的記錄時就停止,FindNext會繼續向下查詢,直到記錄集的末尾。
(六)過濾
myado.Filter("AGE>25");
四、支持算法與支持結構
(一)萃取字段名的算法
void Ufo(CString InStr,vector& OutStr);
該算法用於支持其他操作,可將一個字符串中的所有字段名分離出來,按順序壓入出參OutStr中。
(二)萃取字段名與字段類型的算法
void GetNameandType(CString ColName,vector& OutVnt);
該算法用於支持其他操作,是上一個算法的擴展,在分離字段名的同時,獲取該字段的類型,並按順序一同壓入出參OutVnt中。
(三)字段名與的值的結構
struct AddNewCode
{
_variant_t ColName;
_variant_t Value;
};
該結構用於支持其他操作。
(四)字段名與類型的結構
struct FieldInfor
{
_bstr_t Name;
DataTypeEnum Type;
};
該結構用於支持其他操作。
五、用戶需作的基本操作
1、在工程的stdafx.h中導入msado15.dll;
2、管理COM服務器;
3、將AdoInterface.h、AdoInterface.cpp、DataBelong.h三個文件加在工程目錄下,包含AdoInterface.h;
六、結束語
以上是對這個封裝類的介紹,用戶可以根據自已的需要進行修改和擴展,如果想要隱藏實現細節也可將其做成COM組件,這樣使用起來更加靈活。希望它能給大家操作數據庫帶來方便或者一些啟示。
示例程序由Visual Studio.NET2003編譯,在Win2000下通過測試。
本文配套源碼