SSE是英特爾提出的即MMX之後新一代(當然是幾年前了)CPU指令集,最早應用在PIII系列CPU上。現在已經得到了Intel PIII、P4、Celeon、Xeon、AMD Athlon、duron等系列CPU的支持。而更新的SSE2指令集僅得到了P4系列CPU的支持,這也是為什麼這篇文章是講SSE而不是SSE2的原因之一。另一個原因就是SSE和SSE2的指令系統是非常相似的,SSE2比SSE多的僅是少量的額外浮點處理功能、64位浮點數運算支持和64位整數運算支持。
SSE為什麼會比傳統的浮點運算更快呢?因為它使用了128位的存儲單元,這對於32位的浮點數來講,是可以存下4個的,也就是說,SSE中的所有計算都是一次性針對4個浮點數來完成的,這種批處理當然就會帶來效率的提升。我們再來回顧一下SSE的全稱:Stream SIMD Extentions(流SIMD擴展)。SIMD就是single instruction multiple data,連起來就是“數據流單指令多數據擴展”,從名字我們就可以更好的理解SSE是如何工作的了。
雖然SSE從理論上來講要比傳統的浮點運算會快,但是他所受的限制也很多,首先,雖然他執行一次相當於四次,會比傳統的浮點運算執行4次的速度要快,但是他執行一次的速度卻並沒有想象中的那麼快,所以要體現SSE的速度,必須有Stream做前提,就是大量的流數據,這樣才能發揮SIMD的強大作用。其次,SSE支持的數據類型是4個32位(共計128位)浮點數集合,就是C、C++語言中的float[4],並且必須是以16位字節邊界對齊的(稍後會以代碼來進行闡釋,關於邊界對齊的概念,讀者可以參考論壇上的其它文章,都會有很詳細的解答,我這裡就恕不贅述了)。因此這也給輸入和輸出帶來了不少的麻煩,實際上主要影響SSE發揮性能的就是不停的對數據進行復制以適用應它的數據格式。
我是一個C++程序員,對匯編並不很熟,但我又想用SSE來優化我的程序,我該怎麼做呢?幸好VC++.Net為我們提供了很方便的指令C函數級的封裝和C格式數據類型,我們只需像平時寫C++代碼一樣定義變量、調用函數就可以很好的應用SSE指令了。
當然了,我們需要包含一個頭文件,這裡面包括了我們需要的數據類型和函數的聲明:
#include <xmmintrin.h>
SSE運算的標准數據類型只有一個,就是:
__m128,它是這樣定義的:
typedef struct __declspec(intrin_type) __declspec(align(16)) __m128 {
float m128_f32[4];
} __m128;
簡化一下,就是:
struct __m128
{
float m128_f32[4];
};
比如要定義一個__m128變量,並為它賦四個float整數,可以這樣寫:
__m128 S1 = { 1.0f, 2.0f, 3,0f, 4,0f };
要改變其中第2個(基數為0)元素時可以這樣寫:
S1.m128_f32[2] = 6.0f;
令外我們還會用到幾個賦值的指令,它可以讓我們更方便的使用這個數據結構:
S1 = _mm_set_ps1( 2.0f );
它會讓S1.m128_f32中的四個元素全部賦予2.0f,這樣會比你一個一個賦值要快的多。
S1 = _mm_setzero_ps();
這會讓S1中的所有4個浮點數都置零。
還有一些其它的賦值指令,但執行起來還沒有自己逐個賦值來的快,只做為一些特殊用途,如果你想了解更多的信息,可以參考MSDN -> VisualC++參考 -> C/C++Language -> C++Language Reference -> Compiler Intrinsics -> MMX, SSE, and SSE2 Intrinsics -> Stream SIMD Extensions(SSE)章節。
一般來講,所有SSE指令函數都有3個部分組成,中間用下劃線隔開:
_mm_set_ps1
mm表示多媒體擴展指令集
set表示此函數的含義縮寫
ps1表示該函數對結果變量的影響,由兩個字母組成,第一個字母表示對結果變量的影響方式,p表示把結果做為指向一組數據的指針,每一個元素都將參與運算,S表示只將結果變量中的第一個元素參與運算;第二個字母表示參與運算的數據類型。s表示32位浮點數,d表示64位浮點數,i32表示32位定點數,i64表示64位定點數,由於SSE只支持32位浮點數的運算,所以你可能會在這些指令封裝函數中找不到包含非s修飾符的,但你可以在MMX和SSE2的指令集中去認識它們。
接下來我舉一個例子來說明SSE的指令函數是如何使用的,必須要說明的是我以下的代碼都是在VC7.1的平台上寫的,不保證對其它如Dev-C++、Borland C++等開發平台的完全兼容。
為了方便對比速度,我會用常歸方法和SSE優化兩種寫法寫出,並會用一個測試速度的類CTimer來進行計時。
這個算法是對一組float值進行放大,函數ScaleValue1是使用SSE指令優化的,函數ScaleValue2則沒有。我們用10000個元素的float數組數據來測試這兩個算法,每個算法運算10000遍,下面是測試程序和結果:
#include <xmmintrin.h>
#include <Windows.h>
class CTimer
{
public:
__forceinline CTimer( void )
{
QueryPerformanceFrequency( &m_Frequency );
QueryPerformanceCounter( &m_StartCount );
}
__forceinline void Reset( void )
{
QueryPerformanceCounter( &m_StartCount );
}
__forceinline double End( void )
{
static __int64 nCurCount;
QueryPerformanceCounter( (PLARGE_INTEGER)&nCurCount );
return double( nCurCount * ( *(__int64*)&m_StartCount ) ) / double( *(__int64*)&m_Frequency );
}
private:
LARGE_INTEGER m_Frequency;
LARGE_INTEGER m_StartCount;
};
void ScaleValue1( float *pArray, DWord dwCount, float fScale )
{
DWord dwGroupCount = dwCount / 4;
__m128 e_Scale = _mm_set_ps1( fScale );
for ( DWord i = 0; i < dwGroupCount; i++ )
{
*(__m128*)( pArray + i * 4 ) = _mm_mul_ps( *(__m128*)( pArray + i * 4 ), e_Scale );
}
}
void ScaleValue2( float *pArray, DWord dwCount, float fScale )
{
for ( DWord i = 0; i < dwCount; i++ )
{
pArray[i] *= fScale;
}
}
#define ARRAYCOUNT 10000
int __cdecl main()
{
float __declspec(align(16)) Array[ARRAYCOUNT];
memset( Array, 0, sizeof(float) * ARRAYCOUNT );
CTimer t;
double dTime;
t.Reset();
for ( int i = 0; i < 100000; i++ )
{
ScaleValue1( Array, ARRAYCOUNT, 1000.0f );
}
dTime = t.End();
cout << "Use SSE:" << dTime << "秒" << endl;
t.Reset();
for ( int i = 0; i < 100000; i++ )
{
ScaleValue2( Array, ARRAYCOUNT, 1000.0f );
}
dTime = t.End();
cout << "Not Use SSE:" << dTime << "秒" << endl;
system( "pause" );
return 0;
}
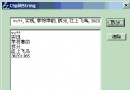
Use SSE:0.997817
Not Use SSE:2.84963
這裡要注意一下,我使用了__declspec(align(16))做為數組定義的修釋符,這表示該數組是以16字節為邊界對齊的,因為SSE指令只能支持這種格式的內存數據。
我們在這裡看到了SSE算法的強大,相信它會成為多媒體程序員手中用來對付無窮盡流媒體數據的一把利劍。我後面還會寫一些關於SSE算法更復雜應用的文章,敬請關注,感謝您抽時間閱讀!