1,什麼是視圖?
2,為什麼要用視圖;
3,視圖中的ORDER BY;
4,刷新視圖;
5,更新視圖;
6,視圖選項;
7,索引視圖;
1.什麼是視圖
視圖是由一個查詢所定義的虛擬表,它與物理表不同的是,視圖中的數據沒有物理表現形式,除非你為其創建一個索引;如果查詢一個沒有索引的視圖,Sql Server實際訪問的是基礎表。
如果你要創建一個視圖,為其指定一個名稱和查詢即可。Sql Server只保存視圖的元數據,用戶描述這個對象,以及它所包含的列,安全,依賴等。當你查詢視圖時,無論是獲取數據還是更新數據,Sql server都用視圖的定義來訪問基礎表;
視圖在我們日常操作也扮演著許多重要的角色,比如可以利用視圖訪問經過篩選和處理的數據,而不是直接訪問基礎表,以及在一定程度上也保護了基礎表。
我們在創建視圖的時候,也要遵守三個規則:
不能在視圖定義中指定ORDER BY ,除非定義中包含Top或For Xml 說明;
所有的列必須有列名;
這些所有的列名必須唯一;
對於視圖表中在沒有top或for xml說明的情況下,不能有Order by 語句,這是因為視圖被認為是一個表,表是一個邏輯的實體,它的行是沒有順序的。視圖中所有列必須有列名,且唯一的情況我想大家都理解;
下面的sql語句表示創建一個簡單的視圖:
復制代碼 代碼如下:CREATE VIEW dbo.V1
AS
SELECT CustomerID,CompanyName FROM Customers
WHERE EXISTS(SELECT * FROM Orders WHERE Customers.CustomerID = Orders.CustomerID)
2.為什麼要使用視圖(更新)
SqlServer既然給我們提供這樣的對象,就一定有它的作用。而我們在使用視圖上,要麼用的過多,要麼用的不夠,所以一部分人建議不要用視圖,而一部分人又建議少用。那我們聽誰的呢?
其實我們要是掌握了用視圖的目的,就能在正確的地方,用正確的視圖;那麼視圖能給我們解決什麼問題呢?
1),為最終用戶減少數據庫呈現的復雜性。客戶端只要對視圖寫簡單的代碼,就能返回我所需要的數據,一些復雜的邏輯操作,放在了視圖中來完成;
2),防止敏感的列被選中,同時仍然提供對其他重要數據的訪問;
3),對視圖添加一些額外的索引,來提高查詢的效率;
視圖其實沒有改變任何事情,只是對訪問的數據進行了某種形式的篩選。考慮一下視圖的作用,你應該能看到視圖的概念如何為缺乏經驗的用戶簡化數據(只顯示他們關心的數據),或者不給予用戶訪問基礎表的
權利,但授予他們訪問不包含敏感數據視圖的權力,從而提前隱藏敏感數據。
要知道,在默認的情況下,視圖沒有做什麼特殊的事情。視圖就好象一個查詢那樣從命令行運行(這裡不存在任何形式的預先優化),這意味著在數據請求和將被交付的數據之間多加了一層開銷。這表明視圖絕不可能像
只是直接運行底層SELECT語句那樣快。不過,視圖存在有一個原因--這就是它的安全性或為用戶所做的簡化,在你的需要和開銷之間權衡,找到最適合特定情況的解決方案。
3.視圖中的ORDER BY
視圖表示一個邏輯實體,它與表非常類似;
如果我們在上面的創建的sql語句中加一個Order BY 語句,看看有什麼效果:
復制代碼 代碼如下:ALTER VIEW dbo.V1
AS
SELECT CustomerID,CompanyName FROM Customers
WHERE EXISTS(SELECT * FROM Orders WHERE Customers.CustomerID = Orders.CustomerID)
ORDER BY CompanyName
運行該語句將會失敗,回收到以下的提示:
Msg 1033, Level 15, State 1, Procedure V1, Line 5
除非另外還指定了 TOP 或 FOR XML,否則,ORDER BY 子句在視圖、內聯函數、派生表、子查詢和公用表表達式中無效。
根據提示,ORDER By 也不是不能用,只有指定了Top或for xml語句後,ORDER BY 才能使用,如:
復制代碼 代碼如下:ALTER VIEW dbo.V1
AS
SELECT TOP(10) CustomerID,CompanyName FROM Customers
WHERE EXISTS(SELECT * FROM Orders WHERE Customers.CustomerID = Orders.CustomerID)
ORDER BY CompanyName
但是,並不建議在視圖中使用ORDER BY ,這是因為視圖表示一個表,而對於表來說,是不會有排序的;所以建議在查詢視圖的時候,用ORDER BY;
SQL Server2005聯機叢書有一段這樣的描述:“在視圖、內聯函數、派生表或子查詢的定義中使用ORDER BY 字句,子句只能用戶確定TOP子句返回的行。ORDER BY 不保證在查詢這些構造時得到有序結果,除非在查詢本省也指定了ORDER BY.”
4.刷新視圖
我在上面說過,視圖會保存元數據,列,安全,以及依賴等信息,如果我們把基礎表的架構更改了,並不會直接反映到視圖上來;更改架構後,使用sp_refreshview存儲過程刷新視圖的元數據是一個好習慣;
比如我們創建了一個表T1和一個T1的視圖V1,然後更改T1,再看V1的結果:
首先創建表T1:
復制代碼 代碼如下:IF OBJECT_ID('T1') IS NOT NULL
DROP TABLE T1
CREATE TABLE T1(col1 INT,col2 INT)
INSERT INTO T1(col1,col2) VALUES(1,2)
GO
然後創建T1的視圖V1:
復制代碼 代碼如下:CREATE VIEW V1
AS
SELECT * FROM T1
在現實實踐中,要避免在視圖中的SELECT語句中使用*,在這只是演示。如果你查詢視圖V1就會出現以下結果:
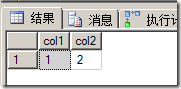
接下來,我們對表T1添加一列col3:
復制代碼 代碼如下:ALTER TABLE T1 ADD col3 INT
然後再次查詢視圖V1,你想這時的結果是三列呢,還是而列呢?答案是二列。T1架構的改變,並沒有影響到視圖的元數據中,這時候,如果我們要刷新一下視圖V1,我們就可以用:EXEC sp_refreshview V1 命令, 再次查詢,V1的結果就是三列了。
5.更新視圖
視圖是一個虛擬表,我們在查詢視圖的時候,實際上是對基礎表的查詢。視圖不僅可以作為SELECT查詢的目標,也可以作為修改語句的目標。當然,當你修改視圖的時候,修改的時候是對基礎表的修改,它就好像是一個代理。當然,如果不允許直接修改基礎表,只允許修改視圖,就可以限制你要公開的數據。這樣,就可以對你的數據起到一定的保護作用,不過這種限制的時候很少。
那麼在更新視圖的時候,有哪些限制條件呢?
1),只要視圖有一列不能隱式獲取值,你就不能想視圖中插入數據,如果列允許NULL、有默認值或者IDETITY屬性,則說明它可以隱式獲取值;
2),如果視圖包含聯結,UPDATE或INSERT語句只能影響聯結的一端。也就是說,INSERT或UPDATE語句必須定義目標列列表,這些列只能數據聯結的一端。你不能從由聯結查詢定義的視圖中刪除數據;
3),不能修改作為計算結果的列。如:標量表達式和聚合函數,SqlServer不會嘗試改變數據庫引擎的計算結果;
4),如果在創建或修改視圖時指定了WITH CHECK OPTION選項,與視圖的查詢篩選器有沖突的INSERT或UPDATE語句將被拒絕;我在“視圖選項”一節詳細講解一下。
如果視圖上定義了INSERT OF觸發器,則違反這些限制的數據修改語句可以被執行。在INSERT OF觸發器中你可以用自己的代碼替換原始修改;
當你允許對有聯結查詢定義的視圖執行修改的時候,一定要謹慎,比如一對多的關系,如果你根據“多”的某一索引值修改對應“一”端某列值的記錄,那麼結果就可想而知;
6.視圖選項
當你創建或修改視圖時,可以指定一些選項,這些選項用戶控制視圖的行為和功能。
ENCRYPTION、SCHEMABINDING和VIEW_METADATA選項在視圖頭指定,CHECK OPTION選項則在查詢之後指定;
如:
復制代碼 代碼如下:CREATE VIEW v2
WITH ENCRYPTION,SCHEMABINDING,VIEW_METADATA
AS
SELECT OrderID FROM dbo.Orders
WITH CHECK OPTION
1),ENCRYPTION
如果你在構建任何類型的商業軟件的時候,需要對視圖進行加密的時候,這是一個不錯的選項。
如果未指定ENCRYPTION選項,SQLSERVEr則以純文本的形式保存用戶定義的語句,如果指定了ENCRYPTION選項,對象的文本則會被混淆。
SQLSERVER提供了一個系統函數sp_helptext查看視圖的文本,如果應用的ENCRYPTION選項,則會得到“The text for object ‘xx' is encrypted”語句;
注:在加密之前一定要先備份你所要加密的視圖,一旦加密,就不能回頭。
2),SCHEMABINDING
如果你使用SCHEMABINDING選項創建視圖,SQLSERVER將不允許刪除基礎表或修改被引用的列,防止在對底層對象修改時,使視圖變得“孤立”,如果某人沒有注意到你的視圖,執行了DROP,刪除視圖引用的列或其他一些操作,那就很糟糕。如果使用SCHEMABINDING選項,則就可以避免這種情況。
如果想在視圖上創建索引,則必須使用SCHMABINDING選項;
如果應用這個選項,則定義視圖的時候要注意兩點:
1,所有對象必須由兩部分構成的名稱,如:應該使用dbo.Orders 而不能是Orders
2,不能在SELECT列表使用*,所有的列名必須指定一個名稱;
3),CHECK OPTION
使用WITH CHECK OPTION 創建的視圖能防止與視圖查詢篩選器有沖突的INSERT或UPDATE語句。沒有該選項,視圖可以接受不符合查詢篩選器的修改。比如:
我們在Northwind數據庫中創建一個CustomWithOrder的視圖,現在還沒有添加WITH CHECK OPTION選項
復制代碼 代碼如下:CREATE VIEW CustomerWithOrder
WITH VIEW_METADATA
AS
SELECT Customers.CustomerID,Customers.CompanyName FROM Customers
WHERE EXISTS(SELECT 1 FROM Orders WHERE Orders.CustomerID = Customers.CustomerID)
該視圖的作用是查詢所有有訂單的客戶的id和公司名,接下來我們向視圖中插入一條不存在的用戶id,和公司名:
復制代碼 代碼如下:INSERT INTO CustomerWithOrder(CustomerID,CompanyName) VALUES('MYSQL','MyReed')
執行成功,然後在查詢這個CustomerWithOrder視圖,很明顯,查詢不到CustomerID為'MySQL'的用戶,因為視圖只包含發生過訂單的用戶;如果你直接查詢Customers表,就會發現這個新增的用戶信息了。
接下來對CustomerWithOrder視圖添加WITH CHECK OPTION 選項
復制代碼 代碼如下:ALTER VIEW CustomerWithOrder
WITH VIEW_METADATA
AS
SELECT Customers.CustomerID,Customers.CompanyName FROM Customers
WHERE EXISTS(SELECT 1 FROM Orders WHERE Orders.CustomerID = Customers.CustomerID)
WITH CHECK OPTION
然後再執行下面的語句:
復制代碼 代碼如下:INSERT INTO CustomerWithOrder(CustomerID,CompanyName) VALUES('ILSQL','MyReed')
你會收到以下錯誤:
Msg 550, Level 16, State 1, Line 2
試圖進行的插入或更新已失敗,原因是目標視圖或者目標視圖所跨越的某一視圖指定了 WITH CHECK OPTION,而該操作的一個或多個結果行又不符合 CHECK OPTION 約束。
語句已終止。
4),VIEW_METADATA
該選項的作用是,讓視圖看起來更像一個真正的表。不使用該選項,返回給客戶端的api的元數據將是視圖所依賴的基礎表的數據;
如果客戶端希望SqlServer發送視圖的元數據信息,而不是基礎表的元數據時,可以在創建或修改視圖時指定此選項;是不是聽的很費勁,聽我慢慢說;
假設用戶擁有對視圖的操作權限,而沒有對基礎表操作的權限,那麼用戶對視圖執行一些操作,如果指定了VIEW_METADATA選項,那麼該語句將會違背安全而失敗,因為只要指定了VIEW_METADATA那麼返回給客戶端就是視圖的元數據,而不是基礎表的元數據。另一方面,如果用戶嘗試通過視圖修改數據,而該操作又與視圖上定義的CHECK OPTION有沖突,這種操作只有直接提交到基礎表,才有可能成功。
SqlServer中就有這樣的工具,在SqlServer2000中,企業管理器就是,如果我們向視圖中插入一條記錄,比如向在有WITH CHECK OPTION選項的CustomerWithOrder視圖中插入一個任意的消費者無論存在與否,並打開跟蹤企業管理器提交到Sql Server中的操作,你會發現操作實際把基礎表作為目標提交的,及時他違背CHECK OPTION,也會成功。而在Sql Server2005中的SSMS中,就會不同了,如果在“Modify”視圖中,手動插入一條記錄,就可以成功,說明雖然指定了VIEW_METADATA和CHECK OPTION選項,它還是插入到了基礎表中了,可以跟蹤一下提交到Sqlserver的操作(用Sql server Profiler)。但如果在由“Open View”產生的面板中進行操作,將會失敗,提示:
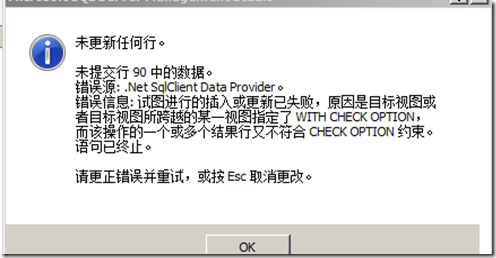
可以再次跟蹤提交到Sql server的操作,就能看到,他提交到目標對象是視圖;
還是那句話:如果客戶端希望SqlServer發送視圖的元數據信息,而不是基礎表的元數據時,可以在創建或修改視圖時指定此選項
這次明白了嗎?
我個人總結,只要有VIEW_METADATA選項就有必要加上CHECK OPTION選項,而SCHEMABINDING選項,最好也要加上,防止你的視圖“孤立”,而在索引視圖中SCHEMABINDING選項是必須加上的。
7.索引視圖
如果沒有索引,視圖中的數據不會有任何物理表現形似,如果加上索引,則就把視圖中的數據物理化了,SqlServer會在修改基礎表時同步索引視圖。但你不能直接同步視圖內容。
我們知道在表上創建索引,能提高性能,相同,在視圖也是一樣,在視圖上創建的第一個索引必須是唯一聚集索引,之後才可以創建其他的非聚集索引。
索引視圖必須使用SCHEMABINDING選項,並且不能引用其他視圖,只能引用基礎表和UDF,而基礎表和UDF必須使用兩部分命名約定來引用(參見5.視圖選項中的SCHEMABINDING選項)。
除了性能,你可能還會因為其他原因使用索引視圖,比如在一張基礎表中有一列我們要強制該列中已知值的唯一性,但是允許出現多次的NULL值,我們怎麼辦呢,我們首先想到的可能是用UNIQUE約束,但是UNIQUE會認為兩個NULL值相等,那麼這個不得不放棄了,那還有什麼辦法呢?
其實我們可以利用一個索引視圖來完成這個任務,利用索引視圖篩選所有非NULL的數據,那麼這種索引將防止重復的已知值進入基礎表,但允許多個NULL,因為NULL不是唯一索引的一部分,我們在向基礎表中插入數據的時候,就利用索引視圖的UNIQUE來限制我們的數據,來達到某列中強制已知值的唯一性的目的;
我們可以演示一下,首先創建一個基礎表T2和一個索引視圖V2:
復制代碼 代碼如下:CREATE TABLE T2(col1 INT,col2 NVARCHAR(50))
CREATE VIEW V2
WITH SCHEMABINDING
AS
SELECT col1 FROM dbo.T2 WHERE col1 IS NOT NULL;
CREATE UNIQUE CLUSTERED INDEX idx_col1 ON dbo.V2(col1);
然後我們向T2表中插入以下數據:
復制代碼 代碼如下:INSERT INTO t2(col1,col2) VALUES(1,'2')
INSERT INTO t2(col1,col2) VALUES(1,'3')
INSERT INTO t2(col1,col2) VALUES(null,'4')
INSERT INTO t2(col1,col2) VALUES(null,'5')
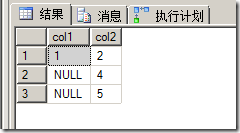
那麼以上4條INSERT哪條會失敗呢?答案是2。最後讓我們SELECT 一下基礎表T2,看實現我們開始那個要求了嗎?
復制代碼 代碼如下:SELECT * FROM t2
執行: