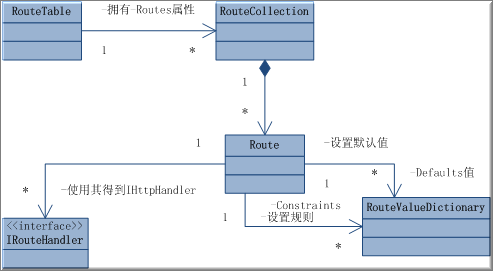
實際需要寫的一個 ASP.NET 清除 HTML 標記的函數,給大家一起學習一下,相信大家都能看懂。
以下為引用的內容:
//清除HTML函數
public static string NoHTML(string Htmlstring)
{
//刪除腳本
Htmlstring = Regex.Replace(Htmlstring, @"<script[^>]*?>.*?</script>", "", RegexOptions.IgnoreCase);
//刪除HTML
Htmlstring = Regex.Replace(Htmlstring, @"<(.[^>]*)>", "", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"([\r\n])[\s]+", "", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"-->", "", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"<!--.*", "", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(quot|#34);", "\"", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(amp|#38);", "&", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(lt|#60);", "<", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(gt|#62);", ">", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(nbsp|#160);", " ", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(iexcl|#161);", "\xa1", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(cent|#162);", "\xa2", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(pound|#163);", "\xa3", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(copy|#169);", "\xa9", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&#(\d+);", "", RegexOptions.IgnoreCase);
Htmlstring.Replace("<", "");
Htmlstring.Replace(">", "");
Htmlstring.Replace("\r\n", "");
Htmlstring = HttpContext.Current.Server.HtmlEncode(Htmlstring).Trim();
return Htmlstring;
}