這是我面試的題目,借用了很多網上同仁的代碼,如有冒犯,請海涵!
現在工作真難找,我應聘的單位是http://www.027dns.net/,希望公司經理能給我上班的機會,我會很 努力的,因為軟件行業才是我的世界!我一個大學本科生當保安都成了同事們的笑話了,呵呵。
這是我第一次求職軟件行業,第一次做面試題目,第一次自己這麼認真寫博客文章,寫的不好,大家 請指正,我會進步的!
張素豐,轉載請注明出處 http://www.cnblogs.com/zhangsufeng/archive/2009/02/28/1400224.html
屁話少說,正文開始:
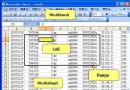
假如我們采集網址:http://info.laser.hc360.com/list/z_news_yw.shtml 上的新聞,要求采集標題 、時間、內容、單篇文章如果有翻頁則采集完全。
這種類型的采集就是從指定網頁獲得新聞列表(即url),然後通過其url獲得新聞詳情,這是一種很常 見的采集方式,有可能到很多頁面上去采集,所以我們可以采用接口來構造基類。
首先定義 IGatherInfo.cs
1using System;
2using System.Collections.Generic;
3using System.Linq;
4using System.Text;
5
6namespace ClassLibrary
7{
8 /**//// <summary>
9 /// 新聞采集類接口
10 /// </summary>
11 interface IGatherInfo
12 {
13 /**//// <summary>
14 /// 采集時間
15 /// </summary>
16 string gatherTime
17 {
18 get;
19 set;
20 }
21 /**//// <summary>
22 /// NewsListUrl:抽取頁地址
23 /// RegexString:正則表達式,抽取邏輯
24 /// 返回新聞頁url
25 /// </summary>
26 List<string> GatherUrlList(string NewsListUrl, string RegexString);
27 //采集新聞詳細內容
28 List<NewsDetail> GatherNewsDetail(List<string> NewsUrlList,
string RegeXString);
29 }
30}
31