前言
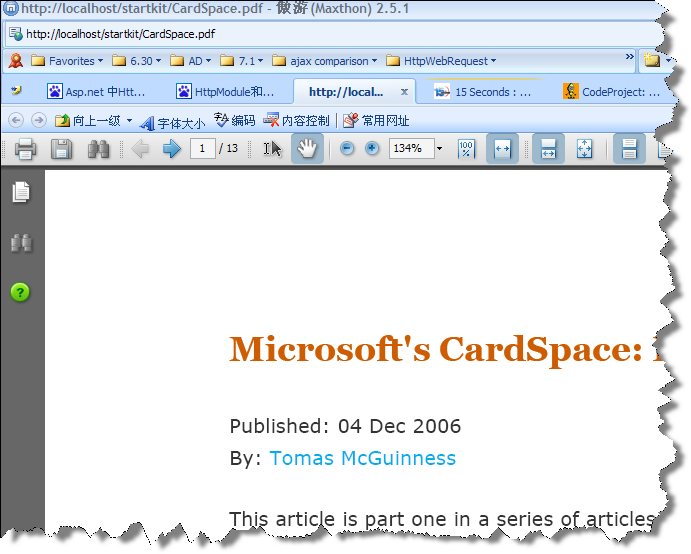
如果我們想將服務端的PDF文檔內容展示給客戶端,往往會通過URL直接訪問的方式。這樣一來,PDF文檔就會毫無保留的保存到客戶端去,通過浏覽器的PDF插件,客戶端可以隨意拷貝PDF的副本。(如下圖)
本文通過HttpHandler和開源控件PDFBox來對PDF文檔進行訪問控制,只向客戶端解析並展示PDF的內容而非PDF文件本身。
PDF解析
目前有許多PDF解析組件,國內比較常用的是iTextSharp,該控件早期從JAVA移植過來,完全支持.NET平台,在創建PDF文檔方面非常靈活易用。然而在讀取解析PDF時卻顯得力不從心,只有少數復雜難用的類可以讓我們讀取PDF。故不適合本案。
PDFBox在此方面表現卻非常突出,同樣,它也是從java平台移植過來的, 常用來作為Lucene的PDF索引器。目前,它的開源項目中已經包含了通過IKVM.NET(IKVM.NET is an implementation of Java for Mono and the Microsoft .NET Framework.)封裝,而支持.NET的組件。
PDFBox對PDF的讀取解析非常簡單,只用如下代碼即可完成:
private static string parseUsingPDFBox(string filename)
{
PDDocument doc = PDDocument.load(filename);
PDFTextStripper stripper = new PDFTextStripper();
return stripper.getText(doc);
}