我們學院的網站做得很爛,上面的新聞不提供rss訂閱,每次看新聞都要跑到網站上去,非常不方便。 我現在是就業負責人,萬一上面有什麼新的通知沒有看到,那我的責任就大了。昨天,突然有一個想法, 就是自己為其實現一個rss feed。
首先我考慮的是用rsslib,但發現rss lib生成的xml,普通的rss訂閱器不識別,沒辦法,只能自己想 辦法解決,最後自己觀察了一個rss的feed,了解了一下基本結構後自己實現了一個。主要有RssDocument 、RssChannel、RssImage、RssItem幾個類。其中RssDocument中含有一個RssChannel,RssChannel中含有 一個RssImage和多個RssItem。他們的類關系圖如下:
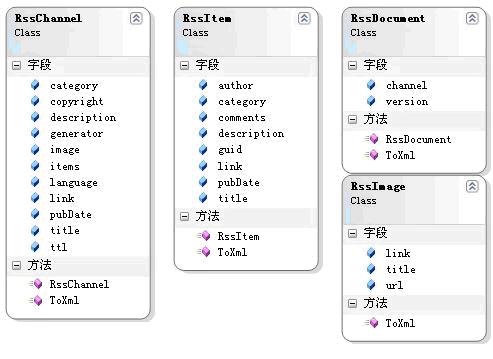
各個類的代碼就不解釋了,都和簡單。唯一值得一提是使用XmlDocument進行操作,這樣做的目的:一 個是使用XmlDocument的效率較高,另外一個就是不容易出現錯誤。當然也可以使用StringBuilder直接對 字符串進行操作。
另外,一件要解決的事情就是如何解析html的問題,開始想用HtmlDocument,後來發現它使用起來不 是很方便,而且效率也不高。但C#中沒有提供其他的操作html的工具,我上網上找了一下,發現一個很好 的東西SgmlReader,它可以將html轉成標准的xhtml。這樣的話,我們就可以用XmlDocument操作轉換後的 html了,轉換的函數如下:
public XmlDocument ConvertHtml2Xhtml(string html)
{
using (SgmlReader reader = new SgmlReader())
{
reader.DocType = "HTML";
reader.InputStream = new StringReader(html);
using (StringWriter stringWriter = new StringWriter())
{
using (XmlTextWriter writer = new XmlTextWriter(stringWriter))
{
reader.WhitespaceHandling = WhitespaceHandling.None;
writer.Formatting = Formatting.Indented;
XmlDocument doc = new XmlDocument();
doc.Load(reader);
return doc;
}
}
}
}
下面的工作主要就是分析我們學院網站上新聞的源代碼了,找到我要提取的新聞在dom中的位置,為了 速度,我直接從根往下找的,為了方便也可以使用getElementsByTagName的方法進行,不過效率可能受到 一點影響。
讀取新聞的代碼很簡單,就不做任何解析了,不明白的可以留言,我會盡力回答的。
本文配套源碼