早上看到老趙的《一個較完整的關鍵字過濾解決方案(上)》文章,講到怎樣在項目中嵌 入過濾方案的問題,以及提到 xingd 和 sumtec 兩位大師發表的系列互拼的文章,在此我也 忍不住談談自己遇到的問題以及一個的簡化版的算法。
因為過濾關鍵字機制到處可見,於是聰明的網友就會想到各種各樣的方法突破,例如:
1、中文會用繁體字的方法避開關鍵字掃描
2、在關鍵字中間插入無意思的特殊字符,例如 * & # @ 等,而且個數可變
3、使用諧音或拆字法變換關鍵字
在實現自己的算法時也有些問題:
4、隨著時間推移,關鍵字列表會越來越大,有些論壇常用的正則表達式N次掃描的方法顯 得效率很低。
5、關鍵字有不同的嚴重級別,有些需要禁止,有些只需要替換,還有一些可能記錄一下 即可。
針對這些問題,可采用的應對方法:
1、加載關鍵字列表時,將所有的關鍵字轉換成繁體字一份,以掃描繁體版的關鍵字;
這個轉換工作只需一句就可以實現了:
s=Microsoft.VisualBasic.Strings.StrConv(word, Microsoft.VisualBasic.VbStrConv.TraditionalChinese, 0);
2、在掃描原文本時,如果遇到關鍵字的首個文字,忽略其後的特殊字符,直到下一個有 意義的文字為止,當然這裡需要在定義關鍵字列表時指定哪些才需要這樣掃描,並不是所有 關鍵字都采用這種方式;
例如有關鍵字 “你好”經常會被人輸入成“你x好”或者“你xxxxx好”,那麼在關鍵字 列表裡就需要定義成“你*好”,在匹配關鍵字時,如果遇到星號就忽略原文本下一個為特殊 的字符。
3、遇到諧音和拆字時,沒什麼好辦法了,只好將這些諧音詞和拆分詞也加入到關鍵字列 表。
4、不用正則表達式或者 String.IndexOf方法,可以將所有關鍵字的首字相同的組成一個 一個小組,然後在將首字放到一個散列表(HashTable/Dictionary<T>),在掃描原文 本時先在散列表裡掃描,如果碰到了首字再掃描同組的關鍵字,這樣簡單處理一下效率可以 提高很多。
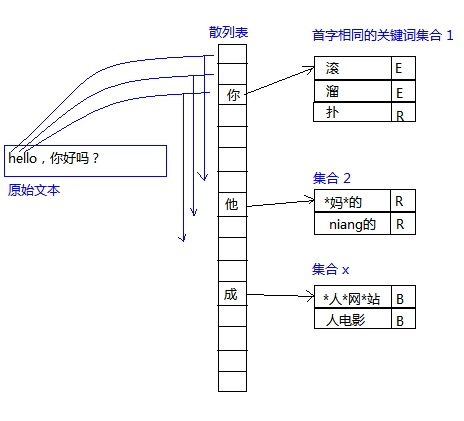
還有一個比用散列表更好的方法,將散列表改成一個大小為char.MaxValue的數組,然後 將首個文字轉成int,即char->int,然後將關鍵詞集合放到相應下標裡。這樣在掃描原文 本時,將被掃描的字符轉成int,然後試探數組相應下標的元素是否不為NULL。這樣比用散列 表會更快一些。