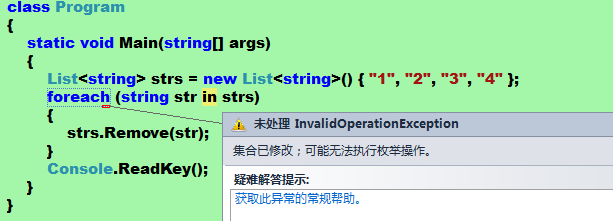
.Net 1.1版本最受诟病的一個缺陷就是沒有提供對泛型的支持。通過使用泛型,我們可以極大地提高代碼的重用度,同時還可以獲得強類型的支持,避免了隱式的裝箱、拆箱,在一定程度上提升了應用程序的性能。本文將系統地為大家討論泛型,我們先從理解泛型開始。
我想不論大家通過什麼方式進入了計算機程序設計這個行業,都免不了要面對數據結構和算法這個話題。因為它是計算機科學的一門基礎學科,往往越是底層的部分,對於數據結構或者算法的時間效率和空間效率的要求就越高。比如說,當你在一個集合類型(例如ArrayList)的實例上調用Sort()方法對它進行排序時,.Net框架在底層就應用了快速排序算法。.Net框架中快速排序方法名稱叫QuickSort(),它位於Array類型中,這可以通過Reflector.exe工具查看到。
我們現在並不是要討論這個QuickSort()實現的好不好,效率高還是不高,這偏離了我們的主題。但是我想請大家思考一個問題:如果由你來實現一個排序算法,你會怎麼做?好吧,我們把題目限定得再窄一些,我們來實現一個最簡單的冒泡排序(Bubble Sort)算法,如果你沒有使用泛型的經驗,我猜測你可能會毫不猶豫地寫出下面的代碼來,因為這是大學教程的標准實現:
public class SortHelper{
public void BubbleSort(int[] array) {
int length = array.Length;
for (int i = 0; i <= length - 2; i++) {
for (int j = length - 1; j >= 1; j--) {
// 對兩個元素進行交換
if (array[j] < array[j - 1] ) {
int temp = array[j];
array[j] = array[j - 1];
array[j - 1] = temp;
}
}
}
}
}
對冒泡排序不熟悉的讀者,可以放心地忽略上面代碼的方法體,它不會對你理解泛型造成絲毫的障礙,你只要知道它所實現的功能就可以了:將一個數組的元素按照從小到大的順序重新排列。我們對這個程序進行一個小小地測試:
class Program {
static void Main(string[] args) {
SortHelper sorter = new SortHelper();
int[] array = { 8, 1, 4, 7, 3 };
sorter.BubbleSort(array);
foreach(int i in array){
Console.Write("{0} ", i);
}
Console.WriteLine();
Console.ReadKey();
}
}
輸出為:
1 3 4 7 8
我們發現它工作良好,欣喜地認為這便是最好的解決方案了。直到不久之後,我們需要對一個byte類型的數組進行排序,而我們上面的排序算法只能接受一個int類型的數組,盡管我們知道它們是完全兼容的,因為byte類型是int類型的一個子集,但C#是一個強類型的語言,我們無法在一個接受int數組類型的地方傳入一個byte數組。好吧,沒有關系,現在看來唯一的辦法就是將代碼復制一遍,然後將方法的簽名改一個改了:
public class SortHelper {
public void BubbleSort(int[] array) {
int length = array.Length;
for (int i = 0; i <= length - 2; i++) {
for (int j = length - 1; j >= 1; j--) {
// 對兩個元素進行交換
if (array[j] < array[j - 1]) {
int temp = array[j];
array[j] = array[j - 1];
array[j - 1] = temp;
}
}
}
}
public void BubbleSort(byte[] array) {
int length = array.Length;
for (int i = 0; i <= length - 2; i++) {
for (int j = length - 1; j >= 1; j--) {
// 對兩個元素進行交換
if (array[j] < array[j - 1]) {
int temp = array[j];
array[j] = array[j - 1];
array[j - 1] = temp;
}
}
}
}
}
OK,我們再一次解決了問題,盡管總覺得哪裡有點別扭,但是這段代碼已經能夠工作,按照敏捷軟件開發的思想,不要過早地進行抽象和應對變化,當變化第一次出現時,使用最快的方法解決它,當變化第二次出現時,再進行更好的構架和設計。這樣做的目的是為了避免過度設計,因為很有可能第二次變化永遠也不會出現,而你卻花費了大量的時間精力制造了一個永遠也用不到的“完美設計”。這很像一個諺語,“fool me once,shame on you. fool me twice, shame on me.”,翻譯過來的意思是“愚弄我一次,是你壞;愚弄我兩次,是我蠢”。
美好的事情總是很難長久,我們很快需要對一個char類型的數組進行排序,我們當然可以仿照byte類型數組的作法,繼續采用復制粘貼大法,然後修改一下方法的簽名。但是很遺憾,我們不想讓它愚弄我們兩次,因為誰也不想證明自己很蠢,所以現在是時候思考一個更佳的解決方案了。
我們仔細地對比這兩個方法,會發現這兩個方法的實現完全一樣,除了方法的簽名不同以外,沒有任何的區別。如果你曾經開發過Web站點程序,會知道對於一些浏覽量非常大的站點,為了避免服務器負擔過重,通常會采用靜態頁面生成的方式,因為使用Url重寫仍要要耗費大量的服務器資源,但是生成為html靜態網頁後,服務器僅僅是返回客戶端請求的文件,能夠極大的減輕服務器負擔。
在Web上實現過靜態頁面生成時,有一種常用的方法,就是模板生成法,它的具體作法是:每次生成靜態頁面時,先加載模板,模板中含有一些用特殊字符標記的占位符,然後我們從數據庫讀取數據,使用讀出的數據將模板中的占位符替換掉,最後將模板按照一定的命名規則在服務器上保存成靜態的html文件。
我們發現這裡的情況是類似的,我來對它進行一個類比:我們將上面的方法體視為一個模板,將它的方法簽名視為一個占位符,因為它是一個占位符,所以它可以代表任何的類型,這和靜態頁面生成時模板的占位符可以用來代表來自數據庫中的任何數據道理是一樣的。接下來就是定義占位符了,我們再來審視一下這三個方法的簽名:
public void BubbleSort(int[] array)
public void BubbleSort(byte[] array)
public void BubbleSort(char[] array)
會發現定義占位符的最好方式就是將int[]、byte[]、char[]用占位符替代掉,我們管這個占位符用T[]來表示,其中T可以代表任何類型,這樣就屏蔽了三個方法簽名的差異:
public void BubbleSort(T[] array) {
int length = array.Length;
for (int i = 0; i <= length - 2; i++) {
for (int j = length - 1; j >= 1; j--) {
// 對兩個元素進行交換
if (array[j] < array[j - 1]) {
T temp = array[j];
array[j] = array[j - 1];
array[j - 1] = temp;
}
}
}
}
現在看起來清爽多了,但是我們又發現了一個問題:當我們定義一個類,而這個類需要引用它本身以外的其他類型時,我們可以定義有參數的構造函數,然後將它需要的參數從構造函數傳進來。但是在上面,我們的參數T本身就是一個類型(類似於int、byte、char,而不是類型的實例,比如1和'a')。很顯然我們無法在構造函數中傳遞這個T類型的數組,因為參數都是出現在類型實例的位置,而T是類型本身,它的位置不對。比如下面是通常的構造函數:
public SortHelper(類型 類型實例名稱);
而我們期望的構造函數函數是:
public SortHelper(類型);
此時就需要使用一種特殊的語法來傳遞這個T占位符,不如我們定義這樣一種語法來傳遞吧:
public class SortHelper<T> {
public void BubbleSort(T[] array){
// 方法實現體
}
}
我們在類名稱的後面加了一個尖括號,使用這個尖括號來傳遞我們的占位符,也就是類型參數。接下來,我們來看看如何來使用它,當我們需要為一個int類型的數組排序時:
SortHelper<int> sorter = new SortHelper<int>();
int[] array = { 8, 1, 4, 7, 3 };
sorter.BubbleSort(array);
當我們需要為一個byte類型的數組排序時:
SortHelper<byte> sorter = new SortHelper<byte>();
byte [] array = { 8, 1, 4, 7, 3 };
sorter.BubbleSort(array);
相信你已經發覺,其實上面所做的一切實現了一個泛型類。這是泛型的一個最典型的應用,可以看到,通過使用泛型,我們極大地減少了重復代碼,使我們的程序更加清爽,泛型類就類似於一個模板,可以在需要時為這個模板傳入任何我們需要的類型。
我們現在更專業一些,為這一節的占位符起一個正式的名稱,在.Net中,它叫做類型參數 (Type Parameter),下面一小節,我們將學習類型參數約束。
實際上,如果你運行一下上面的代碼就會發現它連編譯都通過不了,為什麼呢?考慮這樣一個問題,假如我們自定義一個類型,它定義了書,名字叫做Book,它含有兩個字段:一個是int類型的Id,是書的標識符;一個是string類型的Title,代表書的標題。因為我們這裡是一個范例,為了既能說明問題又不偏離主題,所以這個Book類型只含有這兩個字段:
public class Book {
private int id;
private string title;
public Book() { }
public Book(int id, string title) {
this.id = id;
this.title = title;
}
public int Id {
get { return id; }
set { id = value; }
}
public string Title {
get { return title; }
set { title = value; }
}
}
現在,我們創建一個Book類型的數組,然後試著使用上一小節定義的泛型類來對它進行排序,我想代碼應該是這樣子的:
Book[] bookArray = new Book[2];
Book book1 = new Book(124, ".Net之美");
Book book2 = new Book(45, "C# 3.0揭秘");
bookArray[0] = book1;
bookArray[1] = book2;
SortHelper<Book> sorter = new SortHelper<Book>();
sorter.BubbleSort(bookArray);
foreach (Book b in bookArray) {
Console.WriteLine("Id:{0}", b.Id);
Console.WriteLine("Title:{0}\n", b.Title);
}
可能現在你還是沒有看到會有什麼問題,你覺得上一節的代碼很通用,那麼讓我們看得再仔細一點,再看一看SortHelper類的BubbleSort()方法的實現吧,為了避免你回頭再去翻上一節的代碼,我將它復制了下來:
public void BubbleSort(T[] array) {
int length = array.Length;
for (int i = 0; i <= length - 2; i++) {
for (int j = length - 1; j >= 1; j--) {
// 對兩個元素進行交換
if (array[j] < array[j - 1]) {
T temp = array[j];
array[j] = array[j - 1];
array[j - 1] = temp;
}
}
}
}
盡管我們很不情願,但是問題還是出現了,既然是排序,那麼就免不了要比較大小,大家可以看到在兩個元素進行交換時進行了大小的比較,那麼現在請問:book1和book2誰比較大?小張可能說book1大,因為它的Id是124,而book2的Id是45;而小王可能說book2大,因為它的Title是以“C”開頭的,而book1的Title是以“.”開頭的(字符排序時“.”在“C”的前面)。但是程序就無法判斷了,它根本不知道要按照小張的標准進行比較還是按照小王的標准比較。這時候我們就需要定義一個規則進行比較。
在.Net中,實現比較的基本方法是實現IComparable接口,它有泛型版本和非泛型兩個版本,因為我們現在正在講解泛型,為了避免“死鎖”,所以我們采用它的非泛型版本。它的定義如下:
public interface IComparable {
int CompareTo(object obj);
}
假如我們的Book類型已經實現了這個接口,那麼當向下面這樣調用時:
book1.CompareTo(book2);
如果book1比book2小,返回一個小於0的整數;如果book1與book2相等,返回0;如果book1比book2大,返回一個大於0的整數。
接下來就讓我們的Book類來實現IComparable接口,此時我們又面對排序標准的問題,說通俗點,就是用小張的標准還是小王的標准,這裡就讓我們采用小張的標准,以Id為標准對Book進行排序,修改Book類,讓它實現IComparable接口:
public class Book :IComparable {
// CODE:上面的實現略
public int CompareTo(object obj) {
Book book2 = (Book)obj;
return this.Id.CompareTo(book2.Id);
}
}
為了節約篇幅,我省略了Book類上面的實現。還要注意的是我們並沒有在CompareTo()方法中去比較當前的Book實例的Id與傳遞進來的Book實例的Id,而是將對它們的比較委托給了int類型,因為int類型也實現了IComparable接口。順便一提,大家有沒有發現上面的代碼存在一個問題?因為這個CompareTo ()方法是一個很“通用”的方法,為了保證所有的類型都能使用這個接口,所以它的參數接受了一個Object類型的參數。因此,為了獲得Book類型,我們需要在方法中進行一個向下的強制轉換。如果你熟悉面向對象編程,那麼你應該想到這裡違反了Liskov替換原則,關於這個原則我這裡無法進行專門的講述,只能提一下:這個原則要求方法內部不應該對方法所接受的參數進行向下的強制轉換。為什麼呢?我們定義繼承體系的目的就是為了代碼通用,讓基類實現通用的職責,而讓子類實現其本身的職責,當你定義了一個接受基類的方法時,設計本身是優良的,但是當你在方法內部進行強制轉換時,就破壞了這個繼承體系,因為盡管方法的簽名是面向接口編程,方法的內部還是面向實現編程。
NOTE:什麼是“向下的強制轉換(downcast)”?因為Object是所有類型的基類,Book類繼承自Object類,在這個金字塔狀的繼承體系中,Object位於上層,Book位於下層,所以叫“向下的強制轉換”。
好了,我們現在回到正題,既然我們現在已經讓Book類實現了IComparable接口,那麼我們的泛型類應該可以工作了吧?不行的,因為我們要記得:泛型類是一個模板類,它對於在執行時傳遞的類型參數是一無所知的,也不會做任何猜測,我們知道Book類現在實現了IComparable,對它進行比較很容易,但是我們的SortHelper<T>泛型類並不知道,怎麼辦呢?我們需要告訴SortHelper<T>類(准確說是告訴編譯器),它所接受的T類型參數必須能夠進行比較,換言之,就是實現IComparable接口,這便是本小節的主題:泛型約束。
為了要求類型參數T必須實現IComparable接口,我們像下面這樣重新定義SortHelper<T>:
public class SortHelper<T> where T:IComparable {
// CODE:實現略
}
上面的定義說明了類型參數T必須實現IComaprable接口,否則將無法通過編譯,從而保證了方法體可以正確地運行。因為現在T已經實現了IComparable,而數組array中的成員是T的實例,所以當你在array[i]後面點擊小數點“.”時,VS200智能提示將會給出IComparable的成員,也就是CompareTo()方法。我們修改BubbleSort()類,讓它使用CompareTo()方法來進行比較:
public class SortHelper<T> where T:IComparable
{
public void BubbleSort(T[] array) {
int length = array.Length;
for (int i = 0; i <= length - 2; i++) {
for (int j = length - 1; j >= 1; j--) {
// 對兩個元素進行交換
if (array[j].CompareTo(array[j - 1]) < 0 ) {
T temp = array[j];
array[j] = array[j - 1];
array[j - 1] = temp;
}
}
}
}
}
此時我們再次運行上面定義的代碼,會看到下面的輸出:
Id:45
Title:.Net之美
Id:124
Title:C# 3.0揭秘
除了可以約束類型參數T實現某個接口以外,還可以約束T是一個結構、T是一個類、T擁有構造函數、T繼承自某個基類等,但我覺得將這些每一種用法都向你羅列一遍無異於浪費你的時間。所以我不在這裡繼續討論了,它們的概念是完全一樣的,只是聲明的語法有些差異罷了,而這點差異,相信你可以很輕松地通過查看MSDN解決。
我們再來考慮這樣一個問題:假如我們有一個很復雜的類,它執行多種基於某一領域的科學運算,我們管這個類叫做SuperCalculator,它的定義如下:
public class SuperCalculator {
public int SuperAdd(int x, int y) {
return 0;
}
public int SuperMinus(int x, int y) {
return 0;
}
public string SuperSearch(string key) {
return null;
}
public void SuperSort(int[] array) {
}
}
由於這個類對算法的要求非常高,.Net框架內置的快速排序算法不能滿足要求,所以我們考慮自己實現一個自己的排序算法,注意到SuperSearch()和SuperSort()方法接受的參數類型不同,所以我們最好定義一個泛型來解決,我們將這個算法叫做SpeedSort(),既然這個算法如此之高效,我們不如把它定義為public的,以便其他類型可以使用,那麼按照前面兩節學習的知識,代碼可能類似於下面這樣:
public class SuperCalculator<T> where T:IComparable {
// CODE:略
public void SpeedSort(T[] array) {
// CODE:實現略
}
}
這裡穿插講述一個關於類型設計的問題:確切的說,將SpeedSort()方法放在SuperCaculator中是不合適的?為什麼呢?因為它們的職責混淆了,SuperCaculator的意思是“超級計算器”,那麼它所包含的公開方法都應該是與計算相關的,而SpeedSort()出現在這裡顯得不倫不類,當我們發現一個方法的名稱與類的名稱關系不大時,就應該考慮將這個方法抽象出去,把它放置到一個新的類中,哪怕這個類只有它一個方法。
這裡只是一個演示,我們知道存在這個問題就可以了。好了,我們回到正題,盡管現在SuperCalculator類確實可以完成我們需要的工作,但是它的使用卻變得復雜了,為什麼呢?因為SpeedSort()方法污染了它,僅僅為了能夠使用SpeedSort()這一個方法,我們卻不得不將類型參數T加到SuperCalculator類上,使得即使不調用SpeedSort()方法時,創建Calculator實例時也得接受一個類型參數。
為了解決這個問題,我們自然而然地會想到:有沒有辦法把類型參數T加到方法上,而非整個類上,也就是降低T作用的范圍。答案是可以的,這便是本小節的主題:泛型方法。類似地,我們只要修改一下SpeedSort()方法的簽名就可以了,讓它接受一個類型參數,此時SuperCalculator的定義如下:
public class SuperCalculator{
// CODE:其他實現略
public void SpeedSort<T>(T[] array) where T : IComparable {
// CODE:實現略
}
}
接下來我們編寫一段代碼來對它進行一個測試:
Book[] bookArray = new Book[2];
Book book1 = new Book(124, "C# 3.0揭秘");
Book book2 = new Book(45, ".Net之美");
SuperCalculator calculator = new SuperCalculator();
calculator.SpeedSort<Book>(bookArray);
因為SpeedSort()方法並沒有實現,所以這段代碼沒有任何輸出,如果你想看到輸出,可以簡單地把上面冒泡排序的代碼貼進去,這裡我就不再演示了。這裡我想說的是一個有趣的編譯器能力,它可以推斷出你傳遞的數組類型以及它是否滿足了泛型約束,所以,上面的SpeedSort()方法也可以像下面這樣調用:
calculator.SpeedSort(bookArray);
這樣盡管它是一個泛型方法,但是在使用上與普通方法已經沒有了任何區別。
本節中我們學習了掌握泛型所需要的最基本知識,你看到了需要泛型的原因,它可以避免重復代碼,還學習到了如何使用類型參數和泛型方法。擁有了本節的知識,你足以應付日常開發中的大部分場景。
在下面兩節,我們將繼續泛型的學習,其中包括泛型在集合類中的應用,以及泛型的高級話題。