介個是一個ORM,介個ORM基於Dapper擴展。
為什麼需要一個ORM呢?
支持簡單的LINQ查詢
但是不能連表查詢,why?why?why?為什麼不能連接查詢 ^.^ ok.但是就是不支持。哈哈哈哈,最後談一談為什麼
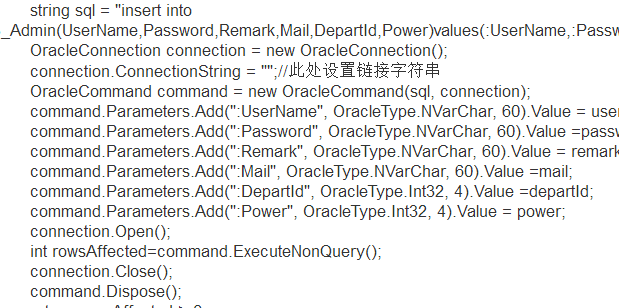
基本的寫法
一次
二次
三次
第一:會造成系統臃腫,DLL編譯代碼量變大
第二:不方便維護
第三: DLL都變大了,創建的時候內存不占大了....................................................好吧,又開始瞎扯蛋
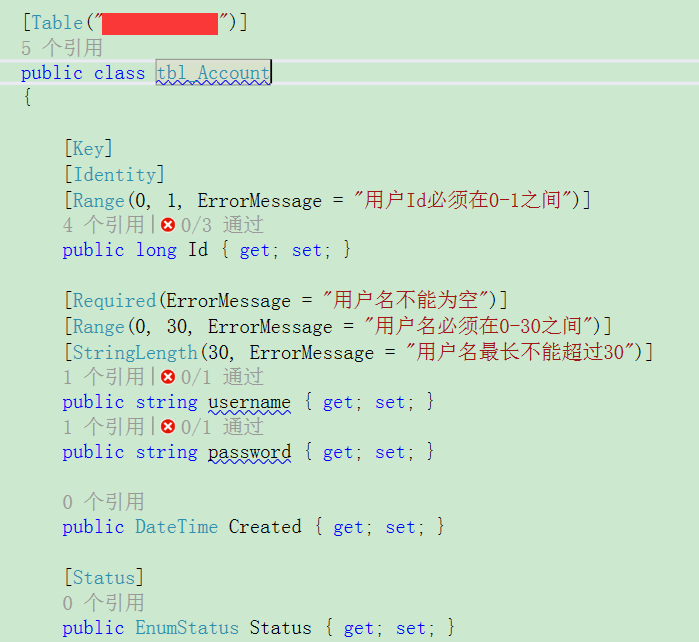
實體類(OK,我們用到了特性)
Table:表名
Key:主鍵
Identity:自動增長列
Status:邏輯刪除(假刪除)
哈哈 ,幾百張表的話,我是不是需要手動去寫? no.no.no. 我們有T4模板 自動生成
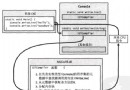
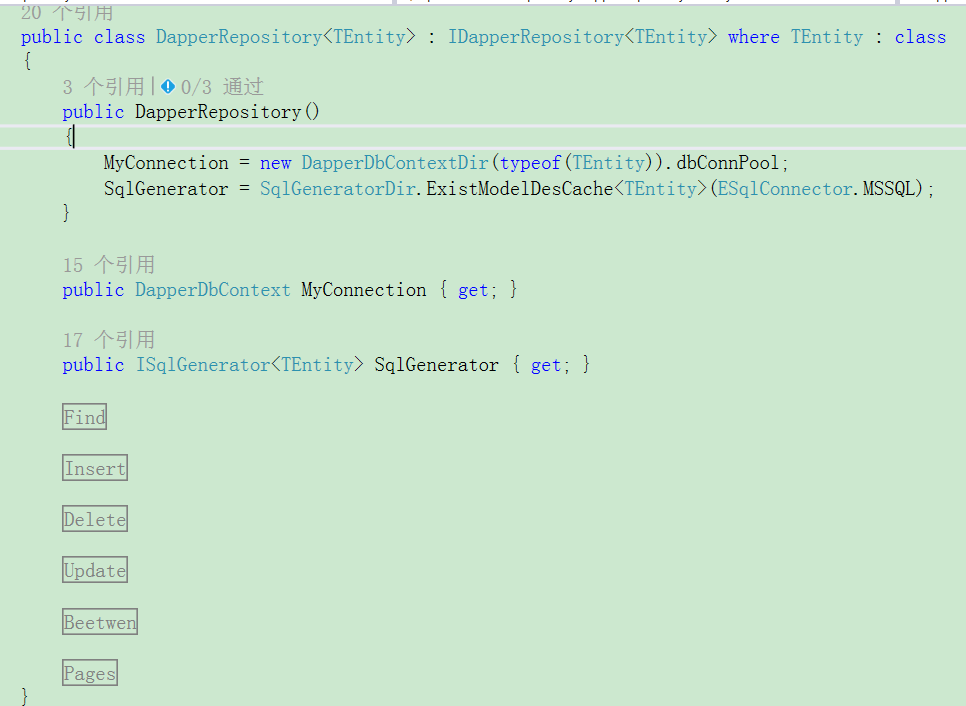
現在看下擴展結構:
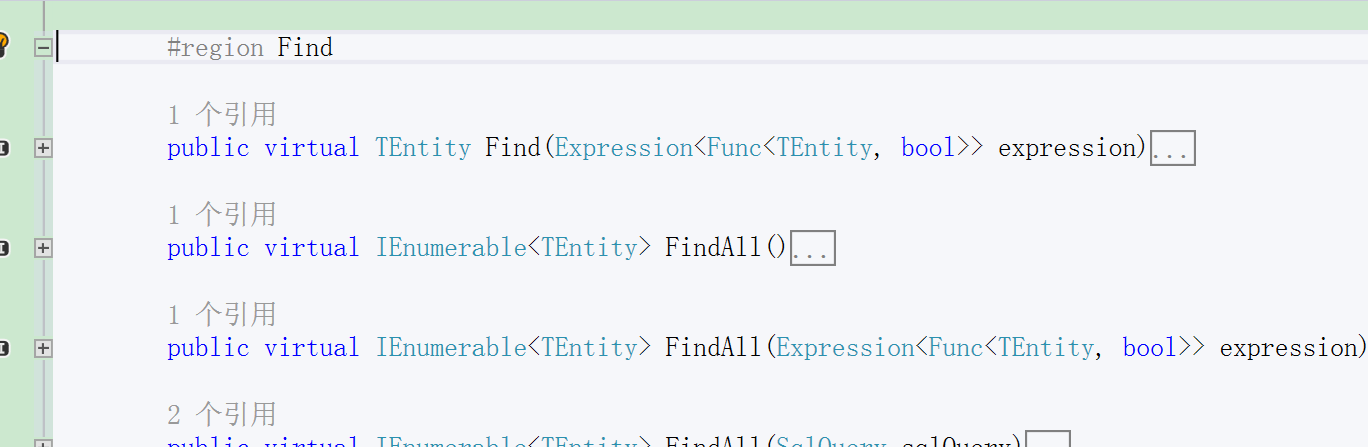
Find(查詢):
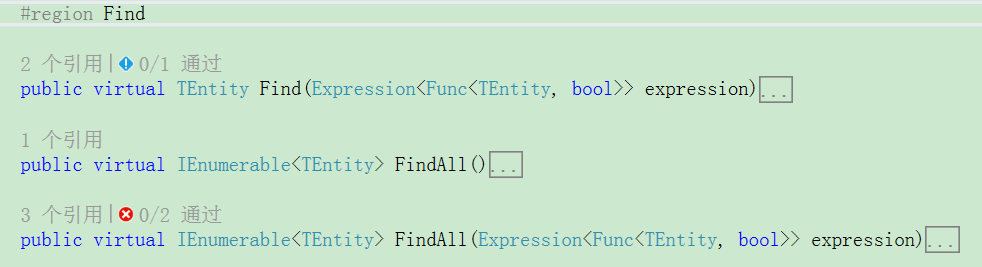
TEntity Find(Expression<Func<TEntity, bool>> expression)
expression 查詢條件:重復的只會查詢一條 Top 1



Delete(刪除):

bool Delete(TEntity instance) :
instance : 根據實體類中的Key(主鍵) 刪除
bool Delete(Expression<Func<TEntity, bool>> expression) :
expression :條件 和查詢一樣
Update(修改):

bool Update(TEntity instance):
instance:根據實體類Key(主鍵)修改實體類
Update(TEntity instance, Expression<Func<TEntity, object>> field):
instance \ field :根據實體類Key(主鍵)修改實體類指定的字段(field)
bool Update(TEntity instance, Expression<Func<TEntity, object>> field, Expression<Func<TEntity, bool>> expression):
instance \ field \ expression :根據置頂條件(expression)修改實體類(instance)指定的字段(field->field為Null時為全部字段)
好吧,再來個分頁:

from: 第幾頁
to :每頁多少條
expression:條件
scfield : 排序條件
idDesc : 是否降序
特麼的沒事務啊,沒事務,不完善什麼ORM....我也想說,你自己寫的什麼什麼玩樣?
特麼的沒連表查詢啊,什麼ORM,MDZZ~~~
無需鏈表、無需子查詢、數據庫中每表可分布在不同服務器,完美解決數據關系,輕松承載百億數據,千萬流量,完美思想............哈哈哈

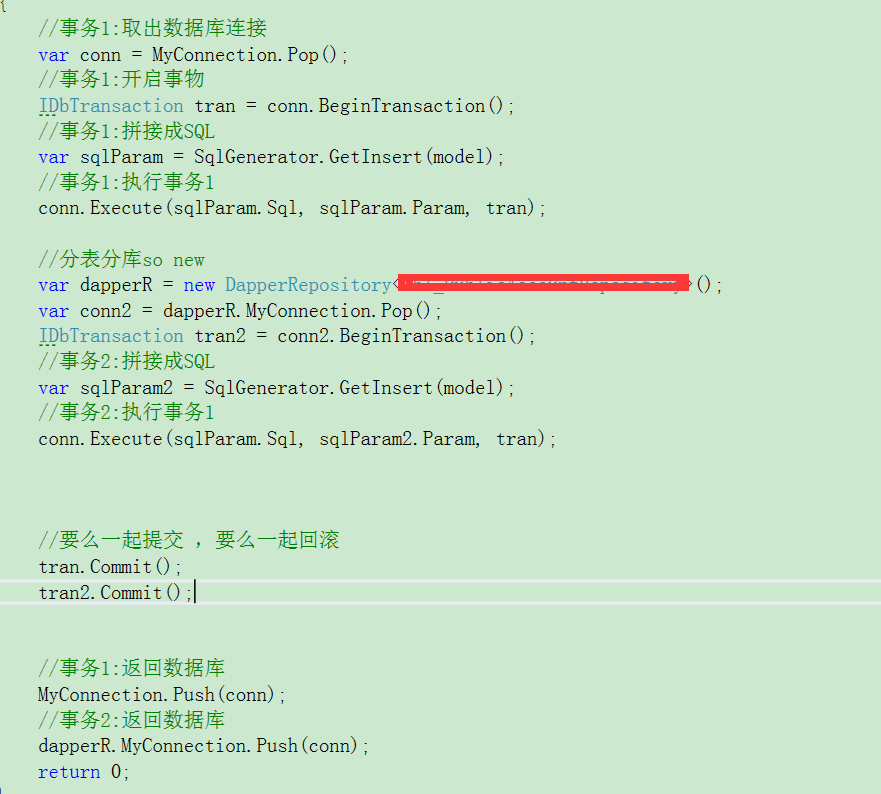
數據連接池 --->
1. 資源重用
2. 更快的系統響應速度
3. 新的資源分配手段
4. 統一的連接管理,避免數據庫連接洩漏
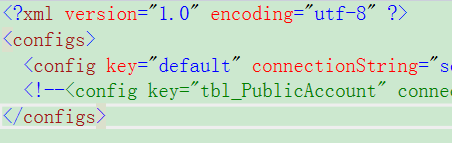
配置文件,沒錯就是配置文件。
key = default 默認的連接字符串 :未配置的實體類連接默認配置的數據庫
key = 表名 :配置的實體類連接配置的數據庫
why?why?why? 為了方便擴展分表分庫:
數據庫中的數據量不一定是可控的,在未進行分庫分表的情況下,隨著時間和業務的發展,庫中的表會越來越多,表中的數據量也會越來越大,相應地,數據操作,增刪改查的開銷也會越來越大;另外,由於無法進行分布式式部署,而一台服務器的資源(CPU、磁盤、內存、IO等)是有限的,最終數據庫所能承載的數據量、數據處理能力都將遭遇瓶頸。
好吧,這是簡述,騷年找資料去吧,用'洪荒之力';
介個樣子的話連表查詢平常的寫法不能滿足啊,怎麼辦?:

使用AutoMapper 連接起來即可,Foreach...代碼多啊。
事務,怎麼辦,自己寫咯:
如果數據一致性要求高,那只能鎖(分布式鎖),或者數據庫寫存儲過程事務....
so .....介介介就是一個ORM!
 開源地址
開源地址