在Github 上搜索下Web Crawler 有上千個開源的項目,但是C#的僅僅只有168 個,相比於Java 或者Python 確實少的可憐。如果按照Stars 排名。可以看到
排在第一位的是一個叫Abot的爬蟲。通過這兩天的測試,發現Abot是一個非常輕巧的爬蟲。非常適合.Net程序員入門爬蟲技術。
在上一篇博文中,已經簡單的介紹了如何使用Abot爬取博客園的新聞數據。今天給大家介紹下Abot的整體結構。
Abot的項目非常簡單,核心的只有一個Project,但是裡面已經包含了線程調度、Html 解析等核心模塊。Abot的入口是PoliteWebCrawler,只需要它的一個Instance就可以啟動爬蟲。
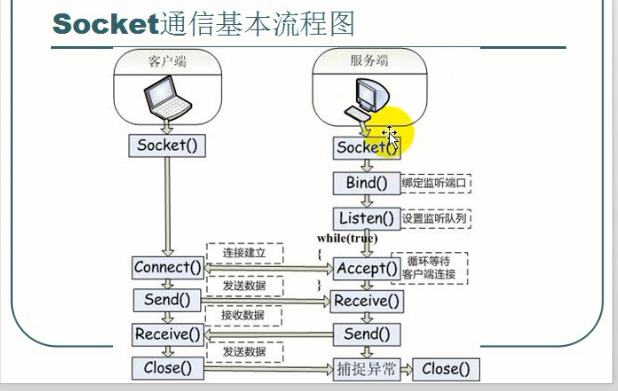
整體的爬取流程大概是這樣子的,以爬取博客園新聞數據為例:
上圖中 綠色的箭頭表示線程從Url Repository獲取需要爬取的Url, 黑色的箭頭表示線程將未爬取Url放入Url Repository。
主要的模塊有:
1) Url Repository 存儲所有需要爬取的Url,底層的實現采用了ConcurrentQueue,因此是線程安全的,也滿足了先進先出的規則。
2) Thread Manager 管理所有的爬取線程,線程個數默認是當前處理器的個數,也可以通過Config 指定。
3) Robots 處理robots.txt 的模塊,Abot 直接封裝了NRobotsPatched 來解析robots.txt
4) LinkParser解析當前爬取到的page 中的鏈接,Abot 很大程度上利用了HtmlAgilityPack
5) Crawled Url Repository 存儲已經爬取的Url,Abot 內部有多個實現
6) Http download 采用了HttpWebRequest 和 HttpWebResponse
7) Memory Monitor 主要是監控內存使用等等,可以通過Config設置爬蟲的內存使用上限等
8) Event 相關,主要是在適當的時候觸發像Start Crawl 等事件
這是Abot的代碼目錄
本文主要介紹下Abot 的整體結構,從代碼量來看還是非常的輕巧,但是裡面具體的實現還是有不少細節性的東西。
對於.Net 程序員是個非常好的學習項目。以後再給大家分析下具體模塊的實現。
歡迎訪問我的個人網站 51zhang.net 網站還在不斷開發中…