不知道你是否有過和我一樣的疑問,不同編碼的字符串是如何存儲在運行時的內存中的呢,計算機在操作string類型的對象時,如何知道這個string是什麼編碼呢?和文本文件那樣有類似BOM的東東在string對象裡?
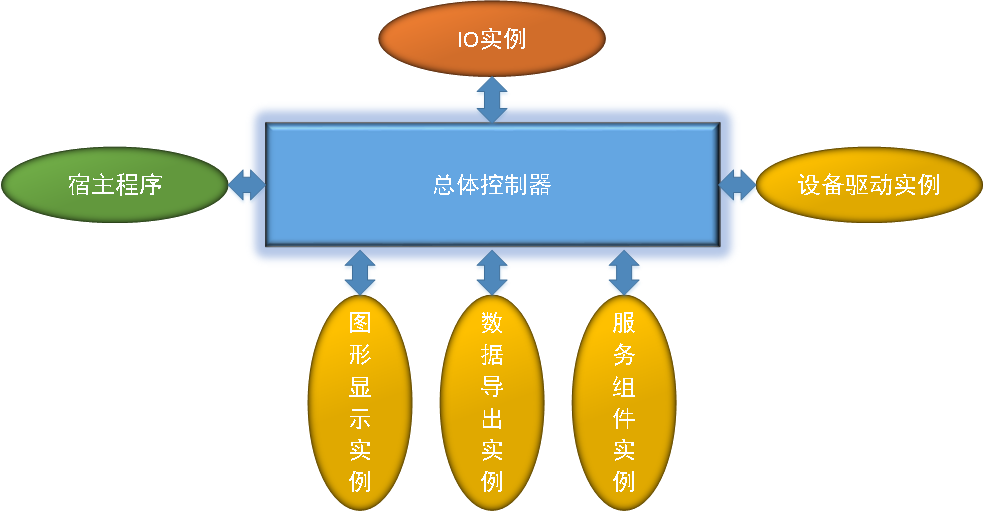
答案是,內存中是無關編碼的。統一使用UCS2(注意,這裡為什麼不說是UTF16,見下文)編碼(大小端應該是和計算機CPU有關,intel的應該是小端)存放在內存中。
string對象和IO交互時,分別根據方法中的Encoding去處理來自IO的字節,或者轉換成Encoding所指示的編碼的字節流作為IO輸出。
另外,上文提到內存中使用的是UCS2而不是UTF16,意思是,對於Unicode編碼值大於0xFFFF的編碼,C#和java一樣,是轉換成“代理對”(2*2字節)表示的。所以,如果string中含有類似emoji那樣的“大”字符時,string的Length方法返回的字符串長度是不正確的。解決方案是,使用StringInfo類中的LengthInTextElements。
PS:System.Text.Encoding中的Unicode和BigEndianUnicode實際是UTF16,微軟一定有它的道理。只是我不清楚。