Html Agility Pack下載地址:http://htmlagilitypack.codeplex.com/
Html Agility Pack 源碼中的類大概有28個左右,其實不算一個很復雜的類庫,但它的功能確不弱,為解析DOM已經提供了足夠強大的功能支持,可以跟jQuery操作DOM媲美:)
Html Agility Pack最常用的基礎類其實不多,對解析DOM來說,就只有HtmlDocument和HtmlNode這兩個常用的類,還有一個 HtmlNodeCollection集合類。
當然在解析DOM前需要加載html原始文件或者html的字符串,HtmlDocument類封裝了支持此功能的方法,下面是加載html的方法介紹。
HtmlDocument類定義了多個重載的Load方法來實現以不同方式加載html,其實主要分為兩種,一種是從Stream中加載html,另外一種是從物理路徑加載html,分別見下面:
方法:public void Load(TextReader reader)
說明:從指定的 TextReader對象中加載Html
示例:
HtmlDcument doc =new HtmlDocument();
基於上面方法,衍生出了幾個不同重載方法。
以指定的Stream對象為主的有:
(1)public void Load(Stream stream) ///從指定的Stream對象中加載html;
(2)public void Load(Stream stream, bool detectEncodingFromByteOrderMarks) ///指定是否從順序字節流中解析編碼格式
(3)public void Load(Stream stream, Encoding encoding) ///指定編碼格式
(4)public void Load(Stream stream, Encoding encoding, bool detectEncodingFromByteOrderMarks)
(5)public void Load(Stream stream, Encoding encoding, bool detectEncodingFromByteOrderMarks, int buffersize)
以指定的物理路徑為主的有:
(1)public void Load(string path)
(2)public void Load(string path, bool detectEncodingFromByteOrderMarks) ///指定是否從順序字節流中解析編碼格式
(3)public void Load(string path, Encoding encoding) ///指定編碼格式
(4)public void Load(string path, Encoding encoding, bool detectEncodingFromByteOrderMarks)
(5)public void Load(string path, Encoding encoding, bool detectEncodingFromByteOrderMarks, int buffersize)
HtmlDocument類中還定義了直接從html字符串中加載Html,如下:
方法:public void LoadHtml(string html)
說明:從指定的html字符串中加載html
示例:
HtmlDocument doc =new HtmlDocument();
HtmlDocument類還有其他寫DOM方法的定義,這裡不作詳細介紹,留作以後專門介紹Html Agility Pack寫DOM章節介紹吧,這裡著重介紹Html Agility pack解析DOM的細節。
通過HtmlDocument把html加載進來後,接著是要做什麼呢?當然是對html解析了,解析DOM就需要提到HtmlNode類
了。 HtmlDocument類由屬性DocumentNode屬性返回當前Html解析後的一個全局的HtmlNode對象;如果想獲取某一個元素的
HtmlNode,可以通過HtmlDocument類的GetElementbyId(string
Id)方法來獲取,返回指定某一個html元素的HtmlNode對象。如何通過HtmlNode對象來訪問DOM呢?介紹之前先對它的功能了解下。
HtmlNode類實現了IXPathNavigable接口,這說明了它可以通過xpath來查詢DOM了,如果對System.Xml
命名空間下的
XmlDocument類了解的,特別是使用過了SelectNodes()和SelectSingleNode()方法的朋友對使用HtmlNode類
將會很熟悉。其實Html Agility
Pack內部是把html解析成xml文檔格式了的,所以支持xml中的一些常用查詢方式。下面對HtmlNode的一些主要的常用成員作簡要的說明。
1)Attributes屬性
獲取當前Html元素的屬性的集合,返回的是一個HtmlAttributeCollection對象。如一個div元素,它可能會定義一些屬性, 如:<div id="title" name="title" class="class-name" title="title div">***</div>,那Attributes返回的HtmlAttributeCollection就包含了 “id,name,class,title”的信息。HtmlAttributeCollection類是實現了接口 IList<HtmlAttribute>的一個集合類,故此可以通過下面代碼方式訪問每一個成員。
HtmlNode node = doc.GetElementbyId("title");
或者
foreach(HtmlAttribute attr in node.Attributes)
在獲取屬性值時,如果某一個屬性名稱不存在的話,Attributes["name"]返回的是null值。
2)FirstChild,LastChild,ChildNodes,ParentNode屬性
FirstChild屬性:返回所有子節點的第一個節點,如下面代碼:
FirstChild則返回的是“<span>HtmlDocument doc =new HtmlDocument();
string html ="<div id="demo"><span ><h1>Hello World!</h1></span></div>";
doc.LoadHtml(html);
HtmlNode node = doc.HtmlDocument;
Console.WriteLine(node.OuterHtml); /// return "<div id="demo"><span>Hello World!</h1></span></div>";
Console.WriteLine(node.InnerHtml); /// return "<span>Hello World!</h1></span>";
如要獲取節點的文本值,通過InnerText屬性來獲取,InnerText屬性過濾掉了所有的Html標記代碼,只返回文本值,如下面:
HtmlNode類提供了足夠豐富的方法供查詢當前節點下的子節點(元素),當然也包括查詢當前節點的父節點(元素)的方法,下面列出主要的方法和使用說明。
獲取父節點的系列方法:
1)public IEnumerable<HtmlNode> Ancestors()
獲取當前節點的父節點列表(不包含自身)。
2)public IEnumerable<HtmlNode> Ancestors(string name)
以指定一個名稱來獲取父節點的列表(不包含自身)。
3)public IEnumerable<HtmlNode> AncestorsAndSelf()
獲取當前節點的父節點列表(包含自身)。
4)public IEnumerable<HtmlNode> AncestorsAndSelf(string name)
以指定一個名稱來獲取父節點的列表(包含自身)。
獲取子節點的系列方法:
1)public IEnumerable<HtmlNode> DescendantNodes()
獲取當前節點下的所有子節點的列表,包括子節點的子節點(不包含自身)。
2)public IEnumerable<HtmlNode> DescendantNodesAndSelf()
獲取當前節點下的所有子節點的列表,包括子節點的子節點(包含自身)。
3)public IEnumerable<HtmlNode> Descendants()
獲取當前節點下的直接子節點的列表(不包含自身)。
4)public IEnumerable<HtmlNode> DescendantsAndSelf()
獲取當前節點下的直接子節點的列表(包含自身)。
5)public IEnumerable<HtmlNode> Descendants(string name)
獲取當前節點下的以指定名稱的子節點列表。
6)public IEnumerable<HtmlNode> DescendantsAndSelf(string name)
獲取當前節點下的以指定名稱的子節點的列表(包含自身)。
7)public HtmlNode Element(string name)
獲取第一個符合指定名稱的直接子節點的節點元素。
8)public IEnumerable<HtmlNode> Elements(string name)
獲取符合指定名稱的所有直接子節點的節點列表。
9)public HtmlNodeCollection SelectNodes(string xpath)
獲取符合指定的xpath的子節點列表。
10)public HtmlNode SelectSingleNode(string xpath)
獲取符合指定的xpath的單個字節點元素。
查詢節點的方法主要是上面10個方法,該類還有其他寫節點的系列方法,這裡不詳細介紹寫操作的方法,留作以後詳細介紹。
結合Xpath進行查詢節點是功能比較強大,這像操作xml那樣方便。
簡單例子的代碼
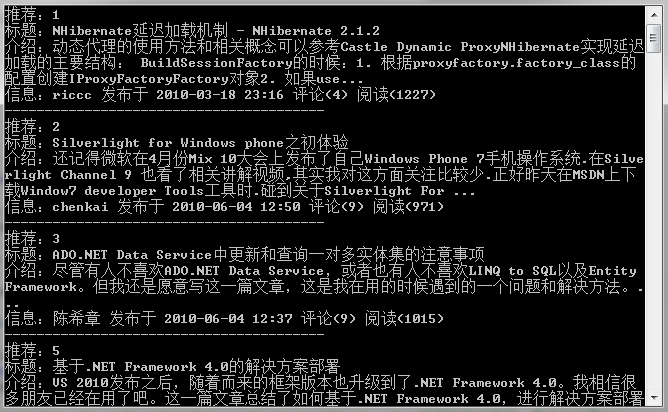
下面例子是把博客園的精華區博客列表查詢出來。執行結果如下面:
代碼
using System;
轉自:http://www.cnblogs.com/huangcong/p/3408309.html